Содержание
Статья полезна для общего понимания обработки сайтов поисковиком, но особенно актуальна тем, кто видит проблемы в сканировании сайта.
В статье:
- Как поисковик обходит сайт
- Кому нужно беспокоиться о краулинговом бюджете
- Как посмотреть сканирование сайта ботами
- Как оптимизировать краулинговый бюджет
- Как оптимизировать рендеринговый бюджет
Как поисковик обходит сайт: что такое краулинговый и рендеринговый бюджет
Страница появится в поиске, будет ранжироваться по ключевым словам и получать трафик, если поисковый бот ее найдет и проиндексирует.
Процесс немного различается для статических HTML-страниц и динамических страниц с JavaScript.
Статические страницы
Боты, которые ищут и обрабатывают страницы, называются краулеры, процесс обработки — краулинг.
-
Поисковый бот формирует список URL сайта — их он находит по Карте сайта, внутренним и внешним ссылкам.
-
Сверяется с разрешениями на обход в файле robots.txt. В этом файле не строгие правила, а рекомендации, так что закрыть страницу от бота через запрет в robots.txt не получится. Если на страницу есть ссылки и редиректы, бот может решить, что она все-таки важна, и включить ее в свой список.
-
Дальше он сортирует ссылки по приоритетности и начинает сканировать. Приоритетность определяет по многим факторам: удаленность от главной, PageRank и другие.
У поисковых систем нет технических возможностей обрабатывать все страницы, появляющиеся у сайтов, так что для краулинга есть лимиты — краулинговый бюджет — это количество страниц, которое поисковый бот может проиндексировать за один ограниченный по времени визит на сайт.
Если количество регулярно обновляемых страниц больше бюджета сканирования сайта, на нем будут не проиндексированные страницы.
Динамические JS-страницы
Краулеры сканируют и индексируют контент статической HTML-страницы. Если страница динамическая, с визуализацией и JS-фреймворками, то процесс в целом такой же, но нужен еще промежуточный этап. После сканирования бот должен сначала отрисовать контент, закодированный через JavaScript, а уже потом отправить его в индекс. Этот этап называется рендеринг.
Поисковые боты обрабатывают код JavaScript с помощью последней версии Chromium. Количество страниц, которые бот может отобразить, называется рендеринговым бюджетом.
Получается, рендеринг — добавочный этап в обработке страницы, который требует ресурсов. Если страницу приходится долго отрисовывать из-за асинхронности и сложности JavaScript, индексирование займет больше времени.
Подробнее про обработку страниц на JavaScript Google рассказал в Центре поиска. Если страница или ее часть не отображаются в выдаче, причиной могут быть проблемы с кодом JavaScript. Руководство от Google поможет их устранить.
Скорость сканирования не относится к факторам ранжирования и сама по себе никак не влияет на позиции. Но важна для работы сайта — если бот не сможет просканировать новые страницы, они долго не появятся в выдаче и пользователи их не увидят. Разберемся, что делать, чтобы боты успевали сканировать все нужные страницы.
Кому нужно беспокоиться о краулинговом бюджете
На небольших проектах количество страниц, которым нужно сканирование, обычно меньше, чем лимит краулера. Так что владельцам маленьких сайтов о краулинговом бюджете можно не беспокоиться.
Если новые страницы месяцами не могут попасть в выдачу, стоит заняться оптимизацией: помочь боту не тратить краулинговый бюджет зря и находить страницы, которые вам нужны. Обычно это проблема крупных проектов.
Осталось понять, достаточно ли большой у вас проект, чтобы нужно было беспокоиться о лимитах краулера. Оптимизаторы называют разные цифры по объему страниц. Одни говорят, что у сайта до 50 тысяч страниц и четкой структурой не должно быть проблем с индексированием, другие называют цифру в 10 тысяч страниц. Проще проверить.
Как определить, что у вас проблемы с краулинговым бюджетом:
-
Найти, сколько страниц теоретически должно быть в индексе. Это страницы без тега noindex (актуален для Яндекса) и нет запрета в robots.txt.
-
Соотнести количество проиндексированных страниц с тем, что теоретически должно быть в индексе. Эти данные можно посмотреть в консоли Google и Яндекс.Вебмастере.
-
Если страниц, которые теоретически должны быть в индексе, во много раз больше, то есть проблемы.
Как посмотреть сканирование сайта поисковыми роботами
Динамика сайта
Динамику по обеим поисковым системам можно смотреть в сервисе Анализ сайта:
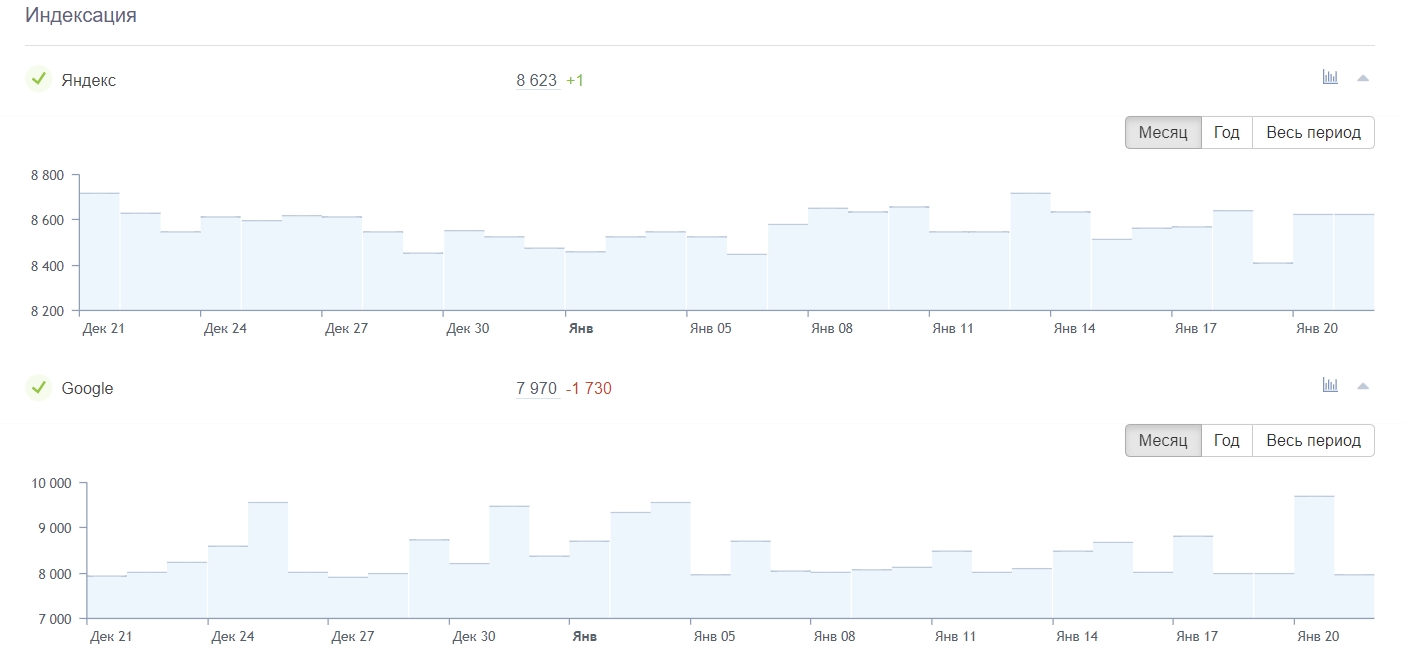 Индексация в Анализе сайта
Индексация в Анализе сайта
В Яндекс.Вебмастере в разделе «Статистика обхода» можно посмотреть, какие страницы сайта обходит робот, а какие он не смог загрузить.
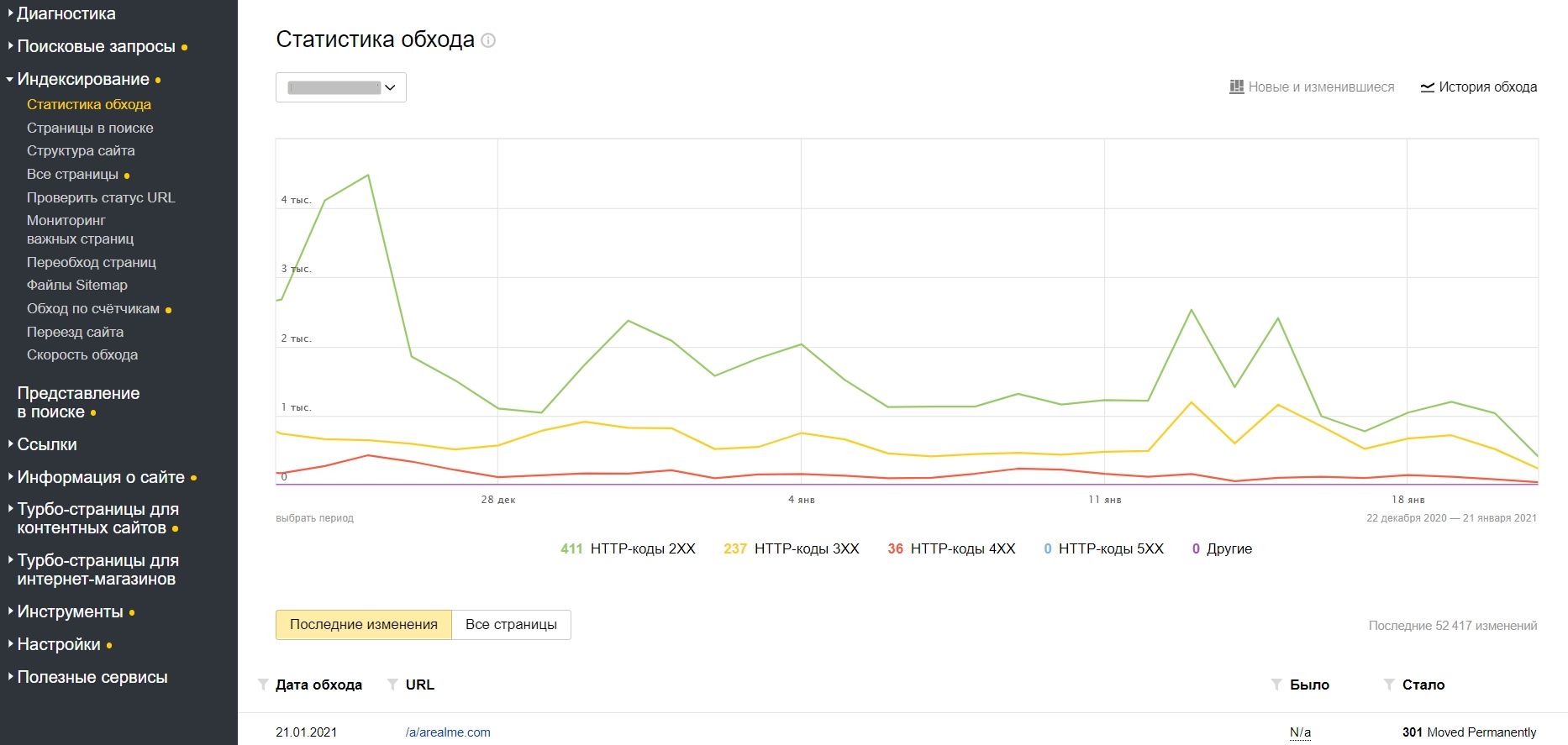 Статистика обхода в Яндекс.Вебмастере
Статистика обхода в Яндекс.Вебмастере
В Google Search Console на вкладке Статистика сканирования можно увидеть общую картину — количество просканированных ботами страниц.
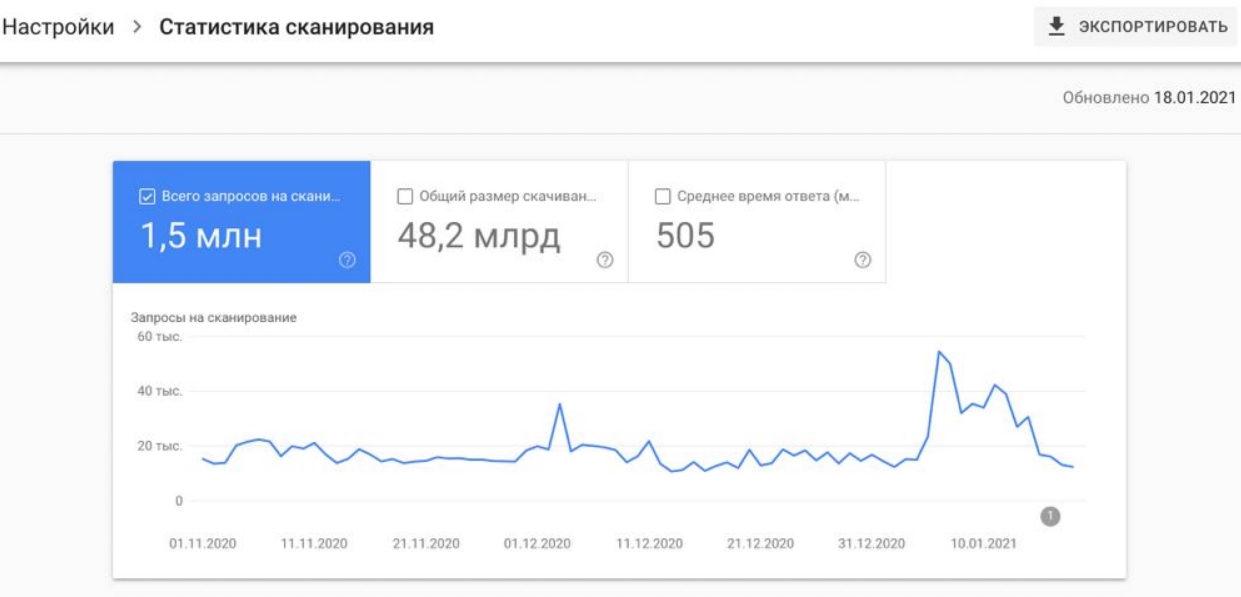 Запросы на сканирование страниц
Запросы на сканирование страниц
Проблемы с индексацией могут повлечь и проблемы с ранжированием, а значит и с трафиком. Если вы заметили падение трафика, то проверьте данные отчета «Покрытие» в консоли Google. Нужно сравнить динамику изменения ранжирования и динамику на всех четырех вкладках отчета.
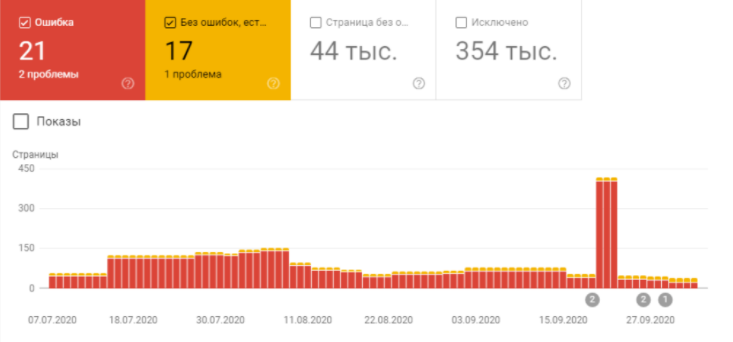 Отчет «Покрытие»
Отчет «Покрытие»
Особенно интересны разделы «Покрытие» — «Ошибки» и «Покрытие» — «Исключено». В «Исключено» будут страницы, которые Google считает некачественными: переадресации, закрытые от индексации и другие.
 Список исключенных страниц
Список исключенных страниц
Проверка конкретной страницы
Узнать, на какой стадии конкретная страница, можно через Инструмент проверки URL. Он отобразит текущий статус индексирования страницы и даст знать, если что-то мешает обработке.
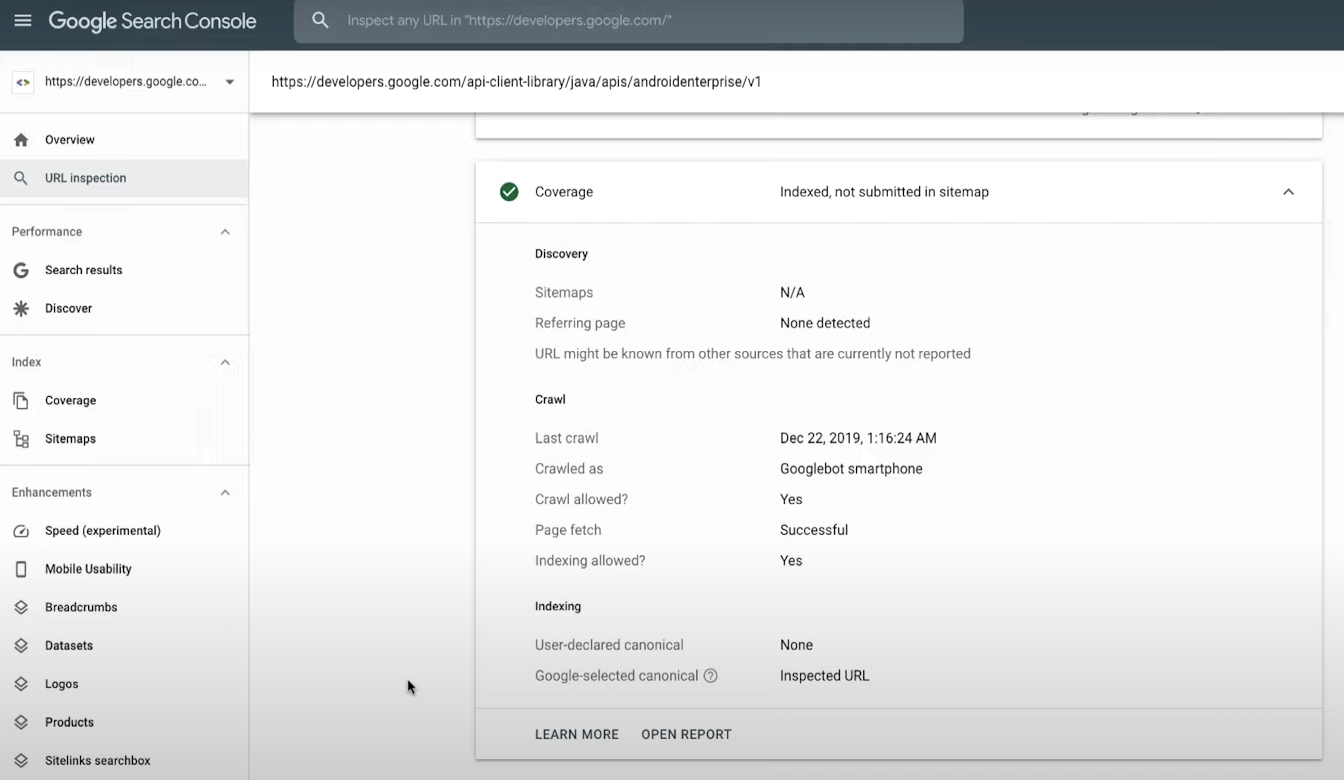 Проверка URL
Проверка URL
Инструмент проверяет последнюю проиндексированную версию страницы. Если после последнего сканирования страницу изменили или удалили, он это не отобразит. Кликните на «Проверить страницу на сайте», чтобы получить данные о текущей версии страницы.
Есть еще момент: инструмент не учитывает санкции поисковика и временную блокировку URL. Так что даже если вы видите в результатах проверки «URL есть в индексе Google», страницы может не быть в выдаче. Проверить, есть ли она там, очень просто — нужно загуглить ее URL.
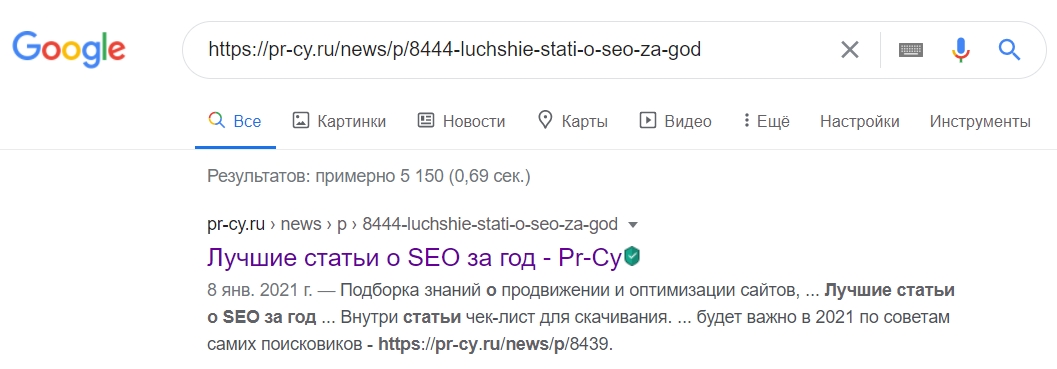 URL есть в выдаче Google
URL есть в выдаче Google
Посмотреть на страницу глазами поискового бота можно с помощью этого бесплатного инструмента. Он покажет Header ответ, код, который видит бот, а также соберет в список внутренние и внешние ссылки и укажет, какие из них индексируются.
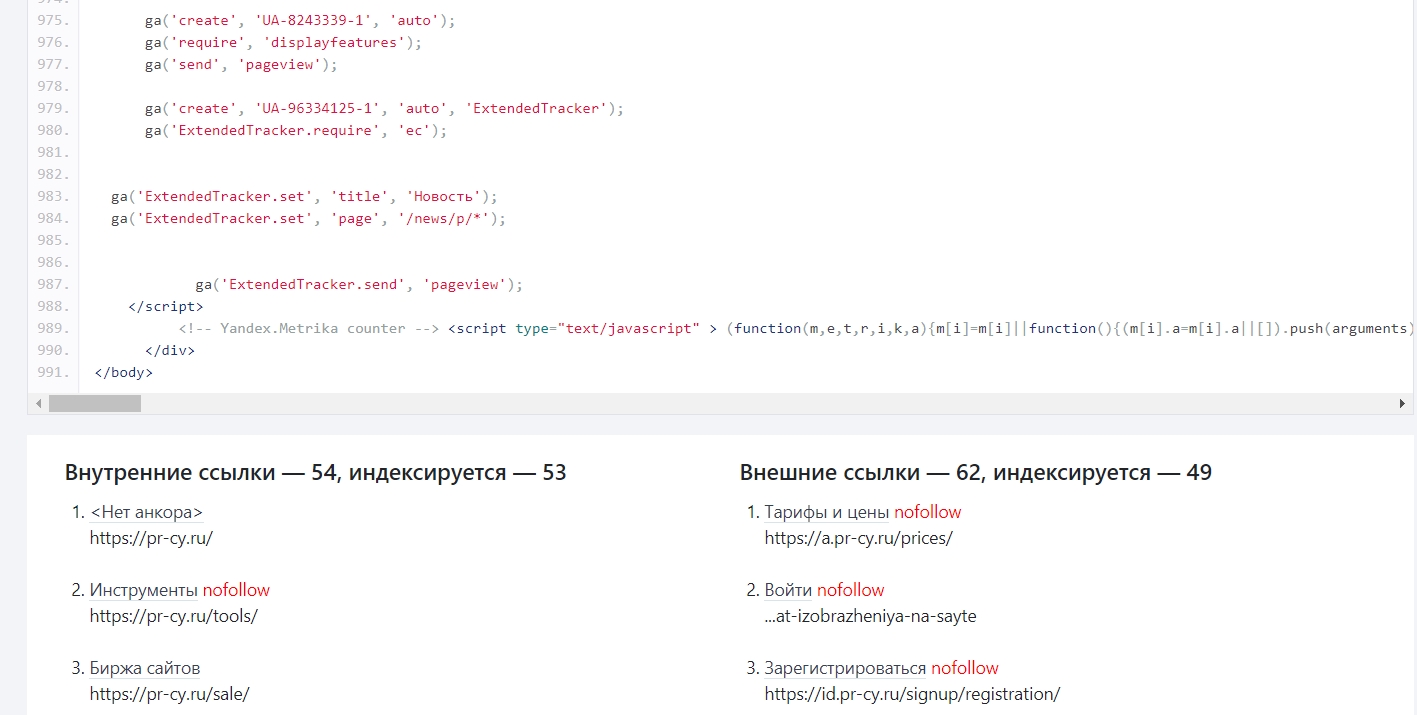 Фрагмент результатов работы инструмента
Фрагмент результатов работы инструмента
Серверные логи
Проверить краулинговый бюджет можно в серверных логах, там можно проследить за тем, какие страницы посещает краулер, увидеть маршруты и расписание обходов сайта. Новичку может быть сложно, но можно разобраться.
Искать логи нужно в файле access.log в системной папке сервера или через панель управления хостинга, но не все типы хостинга это позволяют.
Если вы смотрите на поведение бота Google, вам нужен GoogleBot, но не все, что так называется, действительно относится к ботам поисковика — Как убедиться, что сайт сканируется роботом Googlebot.
Анализировать данные лучше за большой промежуток, не менее месяца. Так получится выявить общие принципы: как часто появляется бот, смотрит ли он Карту сайта, какие URL обходит часто, а какие игнорирует, какие возникают ошибки. Игнорируемый раздел можно усилить внутренними и внешними ссылками.
Регулярно анализировать логи стоит владельцам сайтов, у которых больше 100 тыс страниц, поскольку за ними сложно уследить.
Ориентироваться на больших массивах данных удобнее через программы. Для анализа логов есть программы: LogViewer, Screaming Frog Log Analyzer, JetOctopus, Loggly, GoAccess и другие.
Материал по теме:
Анализируем лог-файл веб-сервера для выявления SEO-проблем
Эффективные способы оптимизировать краулинговый бюджет сайта
Увеличить лимит на сканирование можно только двумя способами:
-
выделить дополнительные ресурсы сервера для сканирования;
-
повысить ценность контента для пользователей.
Разберем, как веб-мастеру работать со вторым.
Ускорить загрузку страниц
Долгая загрузка сайта отнимает время поискового бота. Увеличить скорость сканирования нельзя без ускорения сайта.
Проверить скорость загрузки можно в сервисе Анализ сайта. Он проверяет загрузку онлайн в соответствии параметру Core Web Vitals, который Google начал использовать в 2021 году. Если со скоростью будут проблемы, сервис их покажет и посоветует, что делать:
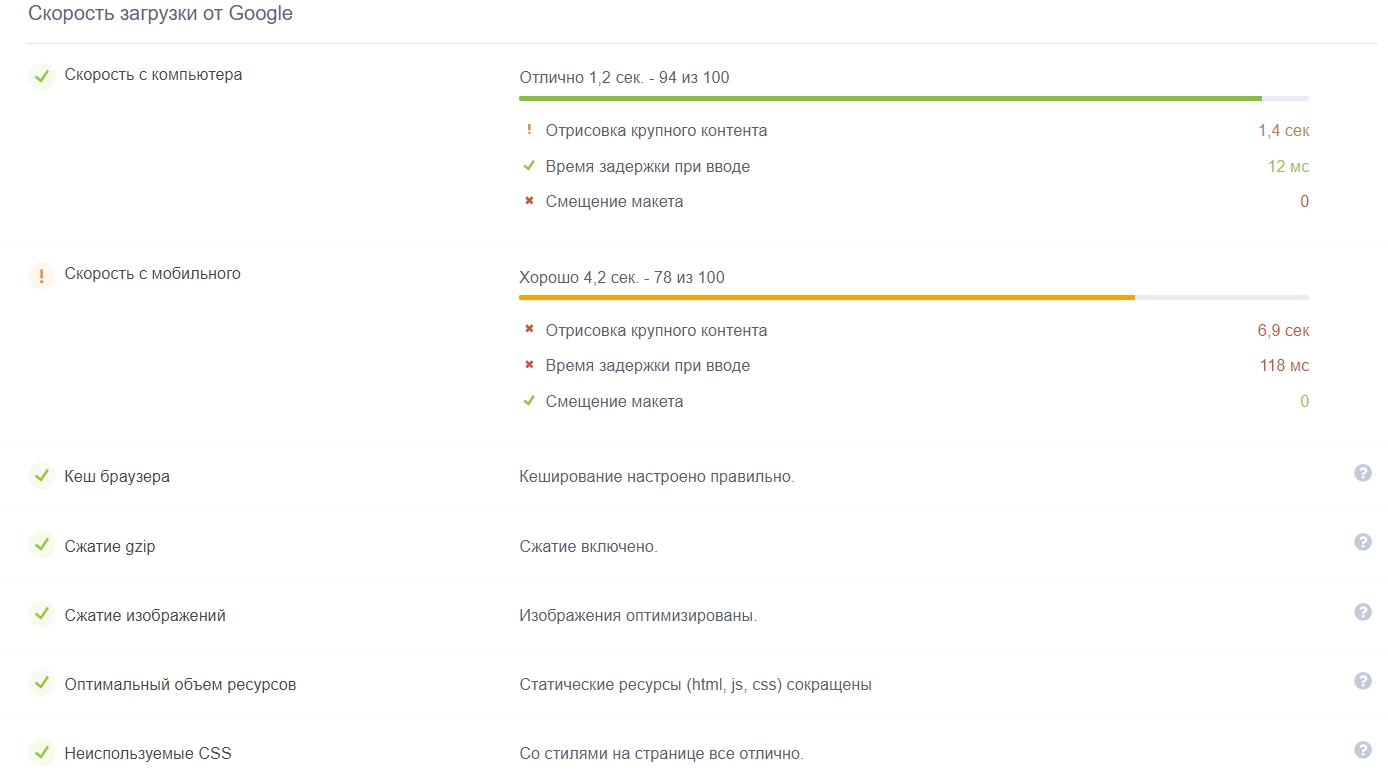 Фрагмент проверки скорости загрузки страницы
Фрагмент проверки скорости загрузки страницы
Проверить скорость сайта
Способов ускорения загрузки много, советуем посмотреть подборку материалов, в которой мы подробно разобрали самые эффективные.
Настроить Sitemap.xml
Обработать Карту сайта: очистить ее от дублей и ненужных ссылок с редиректами. В Карте должны быть только URL качественных страниц, которые нужны в индексе. Служебные там ни к чему.
Как составить файл Sitemap.xml правильно
Обработать robots.txt
Хоть это файл не с правилами, а рекомендациями для поисковых ботов, все равно он может повлиять на решение о сканировании. Чтобы роботы не тратили краулинговый бюджет на обработку страниц, которые не изменились со времени последнего сканирования, добавьте им значение last-modified.
Избавиться от редиректов
Очищайте длинные цепочки редиректов — это вредно и для пользователей, и для роботов-краулеров. Для пользователей увеличивается время загрузки итоговой страницы, приходится дольше ждать. Краулеры расходуют лимиты на редиректах, а если цепочка переадресаций затягивается, краулер может «потерять след» и не дойти до конечной страницы.
Разобраться с дублями контента
От дублей нужно избавиться, они в принципе бесполезны как пользователям, так и ботам. Поисковики не любят дублирующийся контент, роботы реже сканируют повторяющиеся страницы.
Выявить такие страницы поможет технический аудит. Проанализируйте совпадения и либо удалите более слабые страницы с повторениями, либо настройте редирект, если удалить не получится.
Настроить внутреннюю перелинковку
Бот назначает ссылкам приоритетность в сканировании в том числе по отдаленности страницы от главной. Чем меньше кликов нужно, чтобы перейти с главной до искомой страницы, тем она важнее. Поэтому важные для работы пользователей страницы располагайте ближе к главной.
Выстроить архитектуру сайта поможет материал 15 советов по seo-архитектуре сайта
Бот переходит по ссылкам на страницах и таким образом находит другие страницы,которые нужно просканировать. Кстати, это не позволяет запретить сканирование страницы в robots — если бот найдет ее по внутренним ссылкам, то может решить, что она важна, и добавить в свой список для сканирования.
Без внутренних ссылок на страницу боту будет проблематично на нее попасть, поэтому важно перелинковывать новые страницы с существующими.
Направление ссылочного веса по внутренним ссылкам подробно разобрали в статье Эффективная перелинковка: как работать с внутренними ссылками
Наращивать внешние ссылки
Также в определении приоритета страницы важен ее авторитет: чем больше качественных ссылок с релевантных площадок на нее ведет, тем она кажется важнее. Поэтому важные страницы нужно подпитывать ссылками с подходящих по теме площадок.
Без покупки обратных ссылок сложно обойтись, но есть и бесплатные способы, как можно их получить.
Проблемы с индексацией и советы о том, как ее ускорить, мы собрали в этом материале.
Как оптимизировать рендеринговый бюджет
Если вы используете динамические страницы, то нужно позаботиться о том, чтобы поисковым ботам было легко взаимодействовать и с ними. К индексированию добавляется рендеринг — «вторая волна индексирования», которая увеличивает время обработки страниц.
Рассмотрим, что можно внедрить, чтобы оптимизировать этот процесс.
Большую часть контента не визуализировать
JS-решения нужны не для всего контента, не усердствуйте с визуализацией, чтобы не перегружать страницы и дать роботу возможность понять большую часть смысла страницы при первом сканировании, до рендеринга.
Сократить JS
В коде часто бывает мусор: ненужные фрагменты, неиспользуемые библиотеки, разрывы и разделители. Можно уменьшить размер кода, то есть минифицировать JavaScript. Для минификации есть много бесплатных онлайн инструментов, ссылки и больше теории есть в статье.
Ускорить загрузку страницы
Нужно ускорить отображение контента, чтобы страница быстрее загружалась. Есть много возможностей, например, кэширование на длительный срок. Подойдет страницам, содержание которых нечасто изменяется.
Настройку кэширования и другие способы ускорить загрузку разобрали в этой же статье.
Применить динамическое отображение контента
Не все боты поисковиков могут обрабатывать JavaScript, и не все делают это быстро и качественно. Пока проблема существует, Google советует использовать динамический рендеринг.
Сервер должен распознавать поисковых роботов и при необходимости предоставлять им контент, уже обработанный на сервере — в виде HTML-страницы. Запросы от пользователей обрабатываются обычным образом как JS на стороне клиента. Динамический рендеринг можно настроить для всех страниц или только для некоторых.
О том, как это работает, Google рассказал в материале (на русском языке)
Беспокоиться о лимитах для краулеров нужно владельцам больших сайтов, если страницы долго не появляются в индексе. Проблемы с индексированием можно решить, для этого подойдут описанные в материале способы.
Расскажите в комментариях, какие способы мы зря не упомянули в статье? Что работает лучше всего по вашему опыту?