Содержание
На страницах блога PR-CY в рубрике «Спроси PR-CY» пользователи задают экспертам вопросы по оптимизации и продвижению сайтов. В каждом выпуске эксперт новый.
На вопросы Спроси PR-CY#15 ответила
Ксения Пескова
SEO-TeamLead, специалист по технической оптимизации, под её руководством выходят в ТОП все проекты Siteclinic, а еще она пишет скрипты для автоматизации работы и лайфхаки в SEO-блоги.
Эксперт выбрала самые интересные для нее вопросы, на которые она может развернуто ответить. Не попали в выпуск очень простые темы, которые можно легко нагуглить, вопросы, подразумевающие изучение статистики конкретного сайта или полноценный аудит проекта.
Пользователь Илья Апрувин спрашивает:
«Добрый день, вопрос следующий. На данный момент оптимизирую сайт ПП с помощью средств автоматизации. Структуру сайта, в прямом смысле, нет возможности как либо изменять. Есть возможность добавлять sitemap и редактировать robots.txt.
На сайте более 3 000 000 товаров и около 40 000 категорий. Однако примерно 10 000 категорий пустые — нет товаров.
Как вернее всего уберечь их от индексации? Понятное дело, что исключить их из sitemap(-s). И неужели все 10 000 ссылок, у которых нет между собой уровня вложенности, скрывать с помощью robots?»
Оптимальный способ уберечь их от индексации — это для начала выделить паттерн, под который будут попадать все страницы листинга без товара. Например, фраза в теле страницы «В этой категории товар временно отсутствует» или определённое количество тегов , которое совпадает только со страницами без товара.
Вторым шагом на страницах по выделенному паттерну нужно будет настроить HTTP-заголовок X-Robots-Tag: noindex (или none, если хотите запретить ботам следовать по ссылкам на этих страницах). Его понимает и Яндекс, и Google.
А если закроете сканирование в файле robots.txt — это всё равно может не уберечь от индексации страницы, так как:
- в файле мы запрещаем сканирование;
- это всего лишь рекомендации, а не прямое указание.
Пользователь Анжела Малахова спрашивает:
«Напишите, пожалуйста, какие скрипты используете, какие процессы автоматизируете. Спасибо!»
В основном в работе автоматизируем следующие процессы:
1. Анализ динамики трафика из органики: выделить страницы, которые просели или выросли.
Пример скрипта, на который натянули интерфейс:
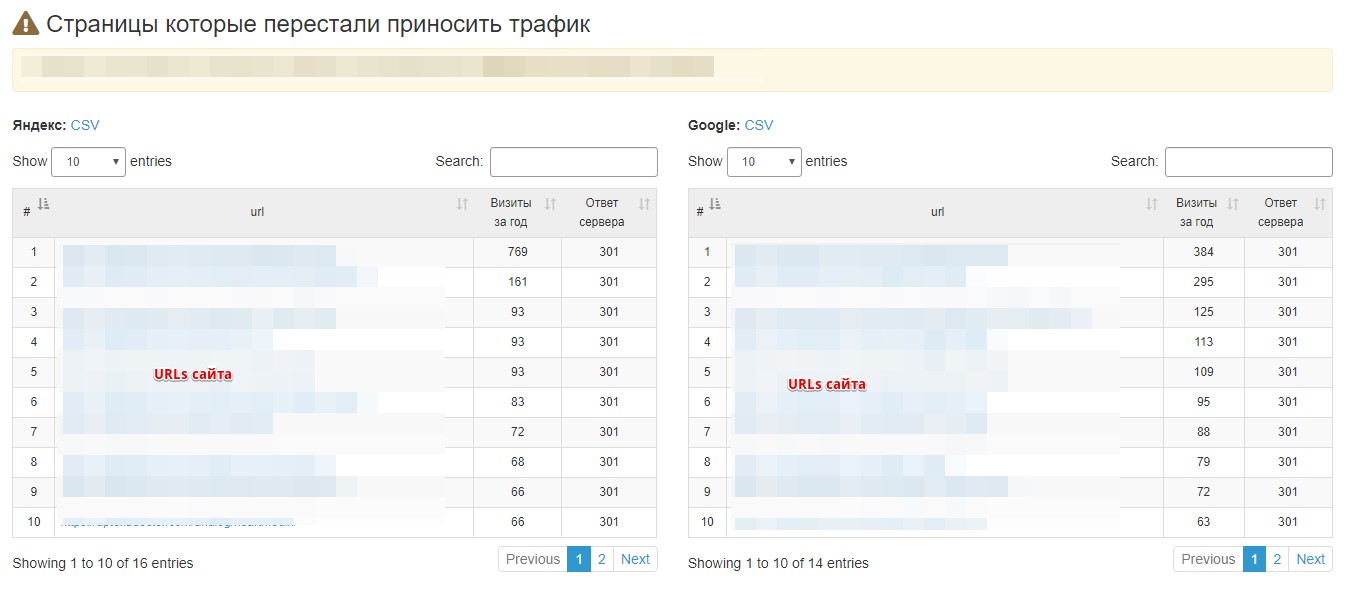
Дополнительно ещё проверяем код ответа сервера сразу же.
2. Анализ динамики количества запросов в ТОП-3 и ТОП-10. Этот процесс автоматизируем с помощью Power BI и дополнительно скрипта. Руками ничего не считаем. На выходе получаем вот такие таблицы:
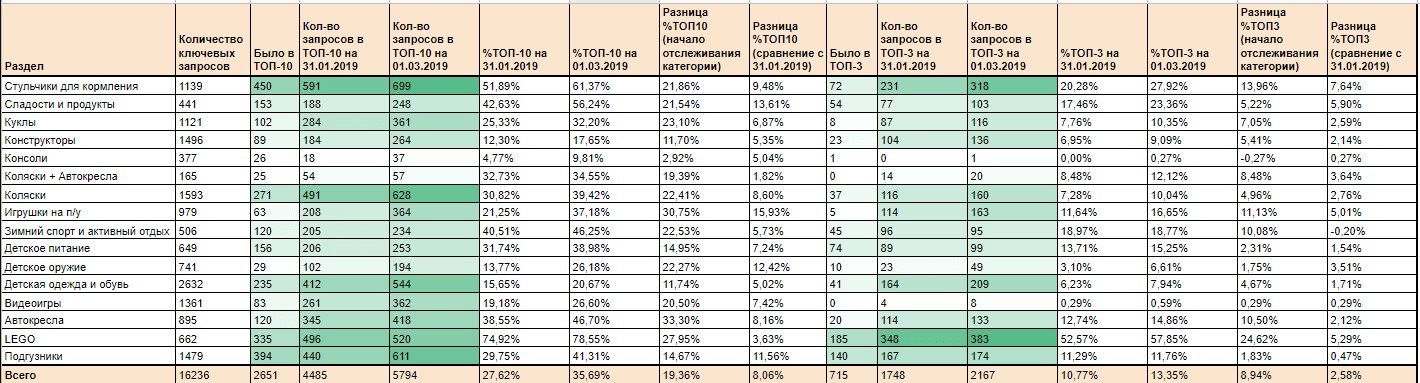
3. Автоматизируем много процессов по семантике, например, поиск дополнительных маркерных слов (особенно актуально, если продвигаешь сайт медицинской тематики). Как работает скрипт:
- На вход он получает текстовый файл с поисковыми фразами (я обычно использую 5–6 фраз, под которую собираюсь искать дополнительные маркеры). Указываем ПС и регион.
- Парсит по этим фразам URL в ТОП-10. Составляем список уникальных документов.
- С помощью API Serpstat вытаскиваем ключевые запросы, по которым ранжируются страницы из нашего списка.
- На выходе мы получаем таблицу с уникальными поисковыми запросами.
Преимущество заключается в том, что: а) у нас есть новые маркеры; б) уже есть отчасти собранное облако запросов. Также используем этот скрип, чтобы быстро собрать семантику для прогнозирования трафика.
4. Автоматизируем рутинные процессы, которые занимают много времени, а парсеры или другие инструменты всё равно требуют ресурсов (человекочасов).
Например, у нас есть задача, которая повторяется из месяца в месяц на одном пациенте: по разделу нужно вытащить категории и подкатегории. Затем по определённым типам фильтров вытащить их атрибуты и количество товарки. При этом не собирать потенциальные страницы, где три и меньше товара. По H1 этих страниц сравниваем с имеющейся семантикой. Если частота кластера больше 50 запросов в месяц — открываем страницу к индексации и оптимизируем её.
5. Скрипт, который предназначен для переиндексации пакетно URL в Google, чтобы ручками не отправлять.
На самом деле, мы используем очень много разных инструментов/скриптов для автоматизации процессов. Многие написаны нами под отдельные задачи и процессы, многие берём из сети (по необходимости допиливаем под себя). Под этот вопрос можно написать целую статью.
Пользователь Александр Мальнев спрашивает:
«Как правильно создавать поддомены под Яндекс при отсутствии физических адресов? Нужно ли уникализировать контент? Как присваивать нужный регион в Вебмастере и Справочнике? Спасибо!»
Мне кажется, что в сеошке поддомены и придумали, чтобы обойти надобность физических адресов. В Вебмастере присваивается регион так же, как и основному домену. В справочнике на втором степе нужно выбрать «Нет, у меня онлайн-компания»:
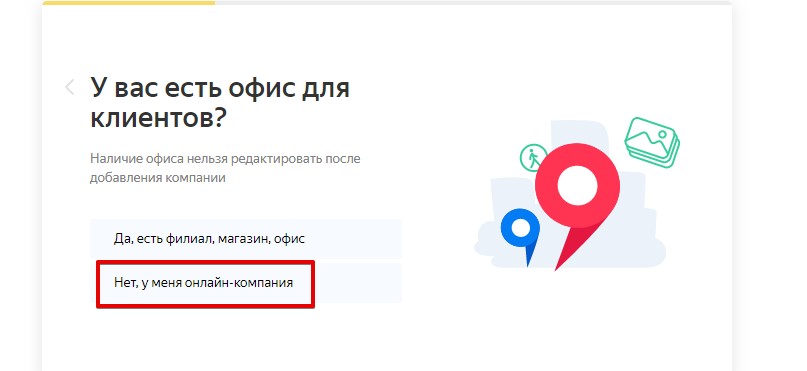
Особых правил, как создавать «правильно» поддомены — нет.
Есть несколько рекомендаций:
- Если вы используете текст на листинге — не переносите его на поддомены.
- Если у сайта превалирует категорийный спрос (например, у ИМ одежды) — настройте canonical со страниц карточек товара поддоменом на аналогичные основного домена.
- Качественно уникализировать контент можно за счёт коммерческих блоков. Таких, как например: а) сроки доставки в регион; б) стоимость доставки; в) какие ТК доставляют в этот регион; г) пару адресов пунктов доставки. Также можно добавлять отзывы покупателей, которые заказывали в регион, присвоенный поддомену. Например, «Текст отзыва. Алексей, Санкт-Петербург».
Пользователь Игорь Правознайкин спрашивает:
«Индексируются ли тэги abbr в тексте, влияют ли на ПФ и семантику текста? Если я в abbr,например, убрал некоторые ключи».
На самом деле, это хороший вопрос, который требует эксперимента (и не на одном пациенте), чтобы подтвердить или опровергнуть влияние abbr на SEO. Поисковики 100% понимают, что текст в теге — это аббревиатура, а title — расшифровка. Если говорить про значимость этого тега и его атрибута, то я считаю, что текст в том же теге p имеет большее значение для ранжирования, но это не означает, что при любом удобном случае Яндекс не наложит постраничный фильтр (как, например, за переспам в атрибуте title тега img). Если вы убрали несколько ключей в этот тег, то, скорее всего, вы нивелировали их значимость. Но опять же повторюсь, что этот вопрос требует эксперимента, а я с тегом abbr лично не игралась.
Пользователь Сергей Чирка спрашивает:
«Мой сайт попал под фильтр в Яндексе — малополезный контент, некорректная реклама, спам. Подскажите как можно выйти из-под этого фильтра? Спасибо!»
Вариантов, почему сайт попал, может быть много: от пустых страниц до n-ного количества блоков рекламы. Так как сайт я не вижу, наверняка сказать не могу.
Мне по какой-то причине постоянно попадаются сайты с фильтром МПК, где причина кроется в рекламе:
- либо её очень много и не отличишь от основного контента сайта;
- либо это кнопка с реферальной ссылкой на какого-нибудь партнёра.
Зачастую эта проблема решалась предупреждением пользователей, что это реклама и сейчас его перебросит на другой сайт.
Пользователь Алексей Дергач спрашивает:
«Есть потребность при маленьком семантическом ядре под некоторые ключи написать одновременно и коммерческие, и информационные запросы. Как их лучше всего разграничить в рамках одного сайта, чтобы не было каннибализма индексируемых страниц в SERP?»
Я считаю, что есть, потому что:
- информационный трафик также можно сконвертить;
- за счёт частого появления в выдаче вы повышаете узнаваемость своего бренда;
- дополнительным плюсом — повышение экспертности в тематике.
Основной совет, как разграничить — просто не смешивайте запросы на одной странице, а также при размещении ссылок как внешних, так и внутренних следить за текстом анкора. Например, одна группа запросов у вас будет включать такие ключевые слова, как: вывоз мусора москва. вывоз мусора, вывоз мусора цена.
Под такие страницы будут оптимизирована страница услуг. А например, под группу запросов «куда вывозят мусор из москвы» будет отдельная посадочная информационная страница.
Сейчас достаточно редко можно вообще заметить каннибализацию между информационными и коммерческими страницами.
Пользователь Mike Mike спрашивает:
«Интересует медицинская тема. Как правильно оформлять ссылки на источники информации? На какие сайты лучше не ссылаться? Нужно оформлять их тегом nofollow?»
Мы используем несколько вариантов оформления источников на медсайтах:
- Источник без тега.
- Источник со ссылкой и без nofollow.

Мы ориентируемся в этом случае на справку Google, которая говорит: «Используйте nofollow, если не хотите, чтобы Google связал ваш сайт с акцептором». А нам как раз и нужно, чтобы он их связал. Поэтому мы не используем nofollow на своих сайтах медтематики.
На какие сайты лучше не ссылаться: на ГС без трафика без доверия у Google.
Мы для себя выделили наиболее оптимальный алгоритм при поиске источников (на примере страниц инструкций препаратов):
- Берём название препарата на латинице.
- Идём в гугловскую выдачу штатов или ещё какую-нибудь забугорную.
- Смотрим ТОП-3.
- Отсеиваем коммерческие сайты.
- Вот он — наш идеальный источник с трастом у Google, а также не наш конкурент.
Пользователь gratsby спрашивает:
«Какой для вас идеальный текст, что там должно быть и какие показатели должны быть соблюдены? Например, наличие абзацев, подпунктов, фото, видео, уникальность по адвего минимум 92/92, наличие структуры предложения…»
Для меня лично у идеального текста три критерия:
- Он должен быть полезным.
Как бы банально это ни звучало, но многие об этом забывают.
Я не хочу видеть на странице категории ИМ «Автосигнализации» текст «Автомобильная сигнализация — это… Она очень полезна для любого автомобиля…». Нет, это хрень, даже если уникальная и со списком. Что может быть полезным в этом случае:
- сколько товара в этой категории;
- какая минимальная и максимальная цена;
- на каких производителей стоит обратить внимание;
- стоимость и сроки доставки.
Это просто примеры. Прежде чем писать текст на страницу, нужно ответить себе на главный вопрос: какой текст будет действительно полезен.
- Если это информационная статья — то там должна быть новая информация.
Я говорю сейчас про смысловую уникальность хотя бы одного блока. Если вы пишете статью про 404 ошибку, недостаточно просто сделать выжимку статей интернета (или хотя бы так её и назовите). Нужен хотя бы 1 блок, который будет идти из вашей головы или опыта. Например, мини-кейс, как выросли позиции после того, как убрали битые ссылки с сайта, или как повлияло на ПФ добавление блока «популярные товары» на 404 странице.
- Она должна легко читаться.
Ни для кого не секрет, что сейчас почти все читают по диагонали. Я хочу сэкономить как своё время, так и время пользователей. Поэтому оформление текста действительно важно. За пару секунд по заголовкам мы оцениваем, есть ли что-то для нас полезное. В случае если мы выделили для себя что-то важное, останавливаемся и читаем. Многую информацию мозгу действительно легче воспринимать списком или таблицей, чем просто абзацем.
По уникальности — опять же, я больше топлю за смысловую, нежели техническую. Есть такие боги рерайта, у которых уникальность будет 100%, а полезность — 0%.
Пользователь mixas спрашивает:
«Какие по вашему мнению самые важные и эффективные моменты(способы) в оптимизации и продвижения сайтов за исключением текстового наполнения для Я и G?».
- Увеличение процента CTR. Мы проводим очень много работ, чтобы улучшить сниппет в выдаче. Это уже как отдельный вид искусства.
- В Google ссылки никто не отменял. У нас прошлогодний кейс, как за счёт ссылок из ТОП-3 в ТОП-1 дотягивали.
- Техничка — это вообще сейчас крайне важно. Но этот параметр далеко за гранью «просто спарсить сайт на ошибки парсером».
- Ещё наблюдаю сильное влияние коммерческих факторов (как новые сайты бустились после расширения информации о компании, доставке, гарантии и т. д.).
Пользователь abrazivru спрашивает:
«Добрый день! Как вы считаете, какое ближайшее будущее регионального продвижения коммерческого сайта в городах, где есть офис и городах где нет офиса? Пункты выдачи и нечто подобное не считать. Профиль компании — продажа мелким оптом инструментов (не интернет магазин). На сегодняшний день позиции сайта в Москве выше, даже в городах, добавленных через Вебмастер».
Сайты с физическими представительствами в городах априори будут выигрывать у тех, у кого представительств нет. Это при абсолютно равных условиях (которых зачастую нет). Вебмастер — это же не решение всех проблем с региональным ранжированием. Как минимум есть ещё справочник, в котором можно регистрировать компанию без физического адреса. А ещё можно указать города доставки в Яндекс.Маркете, что тоже даст свой буст в продвижении по регионам.
Пользователь Mr_Smith спрашивает:
«На сайте есть раздел, где можно почитать книги онлайн, а также есть возможность скачать каждую книгу в трех форматах: fb2, epub, mobipocket. Получается, текст книг дублируется, не только внутри сайта в нескольких форматах, но и на других сайтах. Закрыл в robots.txt доступ к файлам скачивания, на страницы с текстом книг добавил возможность скачать аудиокнигу и видео с пересказом, но страницы в Вебмастере все равно получают статус «Недостаточно качественная» и вылетают из индекса. Как по запросам вида: «$book_name: читать онлайн на русском языке» занять топ?»
В первую очередь ещё раз проверьте сайт на наличие дубликатов. Возьмите кусок текста основной страницы, которая удалена как НКС, и в кавычках в Яндексе проверьте, а не ранжируется ли какая-то другая страница на сайте. В 97% случаев проблема кроется именно в дубликате. И, возможно, именно с форматами это не связано. Проверьте таким образом страниц 5–6. Если найдёте дубликат, можно: а) закрыть в noindex или настроить canonical, если страница нужна пользователям, а поиску — нет; б) если не нужна ни пользователям, ни ПС (технический дубль) — настроить 301 редирект.
Если дубликатов нет и нужно вывести страницу в ТОП-1:
- добавьте полезный контент, например, поместите наверх уникальную рецензию на книгу;
- добавьте возможность оставлять комментарии/голосовалки и т. д.;
- сделайте кликабельное оглавление;
- предложите сотрудничество букинистическим магазинам и разместите карту с адресами магазинов, где можно её купить;
- проанализируйте отображение по запросу в выдаче и улучшите его, чтобы увеличить CTR.
Любые действия, которые сделают вашу страницу лучше, чем у конкурентов.
Пользователь Максим Смирнов спрашивает:
«Есть коммерческий сайт, продажа лицензий на софт. Одно из приложений связано с фильмами, случайно выложили списки фильмов (типа топ 100 комедий) и Яндекс стал на эти списки приводить сильно больше трафика, чем на полезные конвертирующиеся страницы. Видимо, счёл эти страницы некоммерческими. И действительно, этот трафик не получается ни во что полезное конвертировать. Вопрос такой — есть ли вред от таких страниц? Я вижу как минимум ухудшение общего bounce rate для сайта и других поведенческих факторов. Могут ли они отрицательно влиять на «правильный» трафик с Google/Яндекса? Может стоит удалить эти страницы из индекса? Спасибо!»
Я бы не удаляла эти страницы из индекса. Лучше сделать так:
- проанализировать, по каким именно запросам пользователи переходят на страницу;
- проанализировать, совпадает ли интент с контентом.
Например, если переход по запросу «топ 100 комедий», нужно понять, достаточно ли она отвечает этому запросу:
- действительно ли там 100 фильмов;
- действительно ли там комедии;
- удобно ли пользователю воспринимать информацию (есть рейтинг/год/актёры/постеры) или же просто пустая страница со списком из 100 наименований.
С околотематичным трафиком тоже нужно уметь работать. Вреда от него точно не будет. Максимум эти страницы просто перестанут приносить трафик, и всё.
Пользователь Дмитрий Хитрый спрашивает:
«Что скажете про фильтр YMYL от Google для финансовых сайтов? Словил такой частично в Январе 2020, то есть кое-где трафик упал где-то на пару тысяч. Карточки эксперта на сайте были, политики конфиденциальности, пользовательское соглашение — все создано. Статьи пишутся реальными специалистами с опытом в банке… Причем я сам имею опыт в банке и разбираюсь в теме. Но фильтр все равно есть. Интересует, есть ли кейсы выхода из под этого фильтра именно для финансовых сайтов (статейников)? Ну или примеры сайтов. Что посоветуете для финансового статейника в случае YMYL?»
Судя по тому, что сейчас творится в выдаче после январского Core, скорее всего, возможен откат, как был в прошлом году. Исходя из анализа проигравших и выигравших сайтов мы видим, что Google отдал предпочтение:
- Сайтам-гигантам (очень много стало сервисов Яндекса в выдаче Гугла, крупных отзовиков, лидеров ниши, которые уже особо и не парятся, соцсетей). Часто даже интент запроса не соответствует документам в выдаче.
- Узкотематичным сайтам (сродни витальным запросам; пример выдачи по запросу «как взять кредит в отп банке украина»):
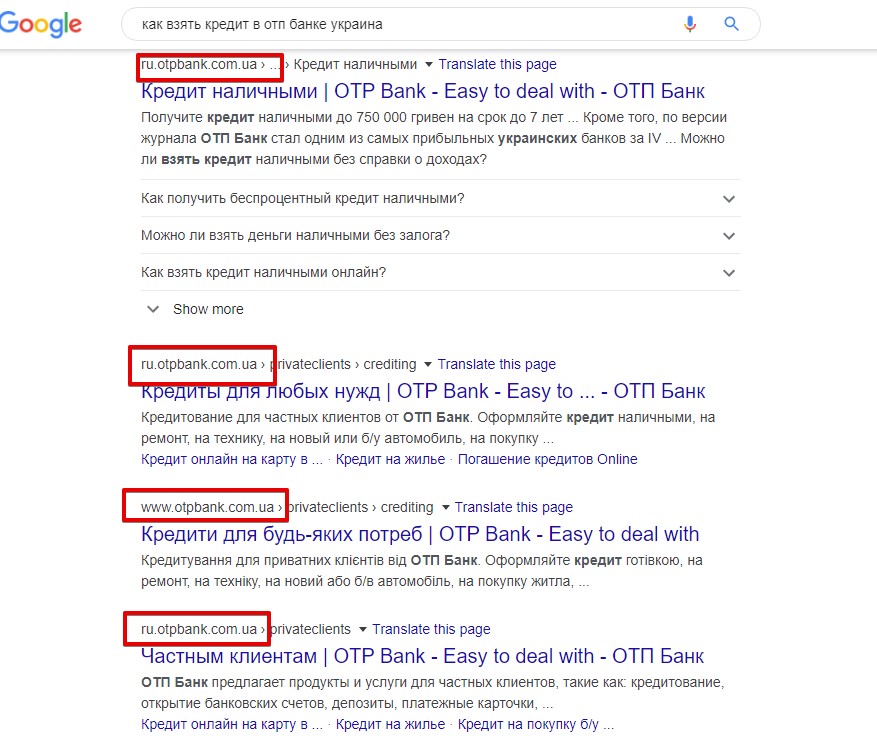
То есть судя по нынешней выдаче, как бы вы ни прорабатывали EAT своего сайта, тем ребятам вы всё равно проиграете в экспертности и авторитетности.
Единственный выход для финансовых сайтов, который я вижу — искать поисковые запросы, где реально попасть в ТОП-3-5 (где сайты равнозначны нашему). Ну либо сидеть ровно и ждать откат (если он, конечно, будет).
Пользователь Петр Плоских спрашивает:
«Где обучались профессии, сколько потребовалось времени для выхода на достаточный уровень знаний? И ваша рекомендация — где сейчас можно повысить свою квалификацию? Может, возьмете меня к себе на стажировку?) Спасибо!»
Все знания, которые были мне необходимы для работы, я получила на стажировке в Siteclinic. Я пришла на собеседование, не зная даже, что такое семантика. Но у меня были преимущества: я быстро соображаю, быстро впитываю информацию и я очень хотела попасть в эту компанию. Женя Аралов обучил меня, по сути, с нуля. За два месяца я закончила стажировку и стала помощником оптимизатора. Через ещё четыре месяца мне уже отдали мой первый проект с нуля. Через месяц ещё один. Siteclinic дал мне основной костяк и вектор направления. Остальное — это уже моё личное любопытство и желание расти.
Повысить свою квалификацию можно и дома. Например, захотели разобраться в вопросе «Как увеличить краулинговый бюджет». Составили себе мини-план, что нужно:
- узнать, что такое краулинговый бюджет;
- какие данные мне нужны, чтобы понять, всё хорошо или плохо;
- какие данные мне нужны, чтобы выявить проблему;
- как провести анализ;
- как решить выявленную мной проблему.
В идеале нужно не просто читать, а применять эти знания на практике сразу же.
Большая часть полезной информации всё-таки находится в англоязычном Google.
Если говорить про курсы, опять же, это не панацея. Например, у нас в городе есть одни курсы, после которых нужно также с нуля всему обучать. Они дают только вектор обучения. Дальше копать нужно самому.
Если вы проживаете в Одессе, мы всегда будем рады рассмотреть вашу кандидатуру.
Бонусы за интересные вопросы
Эксперт выбрал авторов самых интересных вопросов: Mike Mike получает бесплатную консультацию эксперта, а Анжела Малахова — промо-код на месяц тарифа «Профи» в «Анализе сайтов» от PR-CY! Проверяйте личные сообщения 🙂
Мнение редакции PR-CY может не совпадать с мнением приглашенного эксперта