Первой о таком новшестве сообщила известная на Западе сеошница Мари Хейнс. В своем Твиттере она выложила следующую гифку, дополнив ее словами:
«Просмотр форума не самое приятное занятие. С недавних пор Google стал отображать превью форумных постов прямо в результатах поиска. Как результат, во многих случаях отпала необходимость непосредственного перехода на страницу топика».
If you run a forum site, this is something scary. Google is now showing a preview of forum posts making it unnecessary to click through in many cases. pic.twitter.com/UAL0wrh5qw
— Marie Haynes (@Marie_Haynes) 14 августа 2018 г.
Картинка выше показывает, что комментарии форумчан оформлены в выдаче в виде карусели с прокруткой под сниппетом сайта. Таким образом, переходить на страницу форума и в самом деле нет надобности, так как важную информацию можно увидеть прямо в SERP.
Интересно, будут ли владельцы форумов в восторге от такого нововведения? Это риторический вопрос…
Напомним, раньше Google заявил, что использует один алгоритм ранжирования для разных страниц SERP.
Как блоки с ответами влияют на конверсию и CTR: исследования
Нужно ли стремиться к расширенному сниппету
Два способа получить расширенный сниппет
Доработать свои страницы из топа
Найти новые ключевые слова
Как оптимизировать контент, чтобы попасть в блок с ответами
Google старается удержать пользователя на своей площадке, так что на многие запросы поисковик выдает расширенный сниппет, в котором есть полный ответ. Пользователю даже не приходится переходить на сайт, чтобы получить информацию по запросу. Это удобно пользователям, но сказывается на трафике сайтов.
Расширенный сниппет или Featured Snippet — это блок с ответами в верхней части результатов поисковой выдачи Google. Иногда его называют избранным фрагментом. Выглядит как блок с частью контента с сайта, который отвечает на конкретный пользовательский запрос
Расширенный сниппет в выдаче
Раньше этот блок называли нулевой позицией, поскольку сайт мог оказаться в двух местах на первой странице выдачи — и в основных результатах, и в этом блоке. В январе 2020 Google объявил, что больше не будет дублировать ссылку: теперь можно попасть либо в блок с ответами, либо в основную выдачу. Расширенный сниппет больше не нулевая позиция, а одна из топ-10.
Такие блоки представлены в разных форматах.
Форматы расширенных сниппетов в выдаче Google
Сниппет в виде текста встречается чаще всего, он нужен, чтобы дать поисковикам прямой ответ на запрос. Часто в блоке одна или несколько картинок, выбранных алгоритмом. Согласно Search Engine Journal, текстовый блок выводится на запросы с ключевыми словами и как правило поясняют термин, дают советы, отвечают на вопросы и начинаются с конструкций «Как сделать/получить», «кто», «почему», «что», «зачем».
Пример текстового сниппета
Когда запрос предполагает, что пользователь ищет набор шагов для выполнения задачи, Google показывает список. Чтобы попасть этот блок, на странице нужно описать последовательность шагов в нумерованном списке.
Пример сниппета с нумерованным списком
Иногда Google сам форматирует заголовки столбцов списка в пункты с маркерами, чтобы вывести в блоке краткое содержимое страницы. Часто в таком виде выводятся характеристики и состав продукта.
Сниппет со списком характеристик
Google может создавать блоки с ответами из внешних источников данных, к примеру, из YouTube:
Сниппет из YouTube
Поисковые системы могут отвечать на запросы пользователя, используя текст из описания видео:
Пример блока с текстом из описания видео
С одной стороны, благодаря блокам с ответами пользователям нужно совершать меньше действий, чтобы получить достаточную информацию. С другой, сайты получают меньше трафика, поскольку пользователи даже не переходят по ссылке.
Получается, сайтам невыгодно попадать в расширенный сниппет? Посмотрим, что говорят исследования.
Как блоки с ответами влияют на конверсию и CTR: исследования
Сотрудники компании Ahrefs проанализировали два миллиона блоков с ответами и обнаружили, что из результатов выдачи 8,6% всех кликов приходится на них. Поскольку блоки с ответами занимают верхнее место, они перетягивают часть внимания пользователей.
Статистика по кликам
Расширенные сниппеты выдают 13% всех результатов поиска.
Данные по показу блоков с ответами
По исследованию Semrush 2018 года расширенные сниппеты выводятся по 41% ключевых запросов.
Исследование команды SEOquick показало, что наличие расширенных сниппетов в выдаче по запросу негативно сказывается на кликабельности. Они сравнили CTR расширенных сниппетов с CTR других особенных элементов выдачи — блоков с видео, новостями, изображениями, похожими запросами.
CTR разных элементов выдачи
Если в выдаче по запросу нет сниппетов, кликабельность по исследуемому сайту в среднем составляет 14,6%. Если такие сниппеты есть — CTR всего 0,46%. По другим расширенным элементам выдачи CTR был 0,69%.
Даже если сайт в топе, кликабельность все равно страдает. Если он просто в топе, то CTR снижается с 30% до 19,6%, а если он попал в расширенный сниппет, то, по данным того же исследования Ahrefs, CTR около 8,6%.
Нужно ли стремиться к расширенному сниппету
По данным исследований получается, что расширенные сниппеты получают мало кликов. Зачастую пользователь получает из них всю информацию и ему нет необходимости переходить по ссылке. Оптимизаторам выгоднее сосредотачиваться на ключах, в выдаче по которым нет такого сниппета.
Но это не всегда реально, довольно много запросов имеют расширенный сниппет в выдаче. Если сниппет все равно будет портить кликабельность, лучше, чтобы его занял ваш сайт, а не конкурентный. Причем стоит постараться, чтобы пользователям хотелось перейти на сайт за подробностями.
Пример блока с ответами
Оптимизатор Робби Ричардс считает, что попасть в блок с ответам довольно быстро и несложно для качественных сайтов:
99,58% блоков берутся из десяти лучших позиций выдачи;
одна страница может выдавать тысячи различных блоков ответов.
Эксперимент по отказу от сниппета
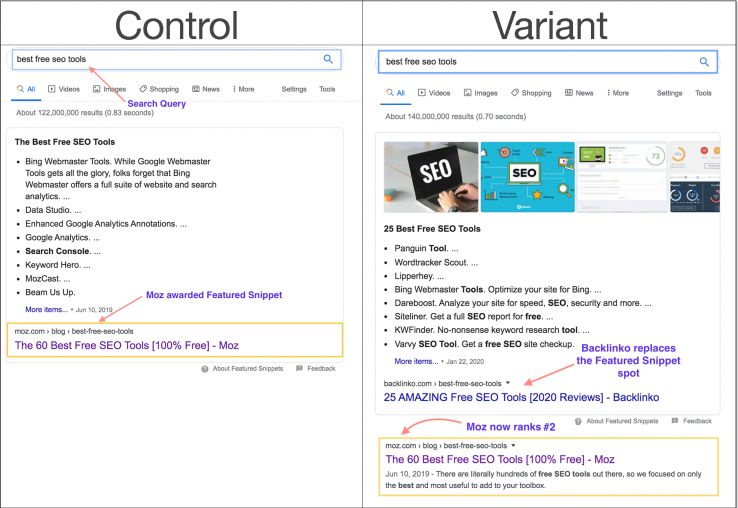
На страницах блога Moz рассказали об эксперименте с расширенными сниппетами. План был такой: удалить страницы блога Moz из расширенных сниппетов и посмотреть, как изменится трафик.
Важный момент: страницы обычно ранжируются по множеству ключей, какие-то дают расширенный сниппет, какие-то нет. В отдельных случаях потеря сниппета может сильно повлиять на трафик, а в каких-то будет смягчено, если URL ранжируется по множеству других ключевых слов.
Они нашли несколько страниц блога в сниппетах и использовали тег data-nosnippet, чтобы удалить страницы с «нулевой позиции».
По этому запросу страница с сайта Moz почти сразу потеряла место в сниппете. Вместо нее сниппет занял другой сайт, а статья Moz вернулась на верхнюю позицию в «естественной» выдаче.
Аналогичная ситуация с другой статьей: расширенный сниппет занял материал с сайта Backlinko, а статья Moz спустилась ниже в топ выдачи.
В итоге исследователи потеряли значительный объем трафика — у всех страниц из эксперимента трафик упал примерно на 12% после потери места в расширенном сниппете.
Итоги эксперимента:
тег nosnippet действительно запрещает Google извлекать данные со страницы для использования в расширенном сниппете;
для тестируемых страниц отказ от сниппетов повлек уменьшение трафика на 12%;
после завершения теста вернуть некоторые сниппеты страницам не удалось — это место либо заняли конкуренты, либо запрос не выводил сниппет.
Наверняка есть исключения, но по итогу для большинства сайтов лучше будет стараться занять расширенные сниппеты своими страницами.
Дальше подробнее рассмотрим, как попасть в блоки ответов.
Два способа получить расширенный сниппет
1. Доработать свои страницы из топа
Один из способов попасть в расширенный сниппет в Google — иметь такие же частотные ключевые слова, как на странице, которая уже находится в блоке с ответами.
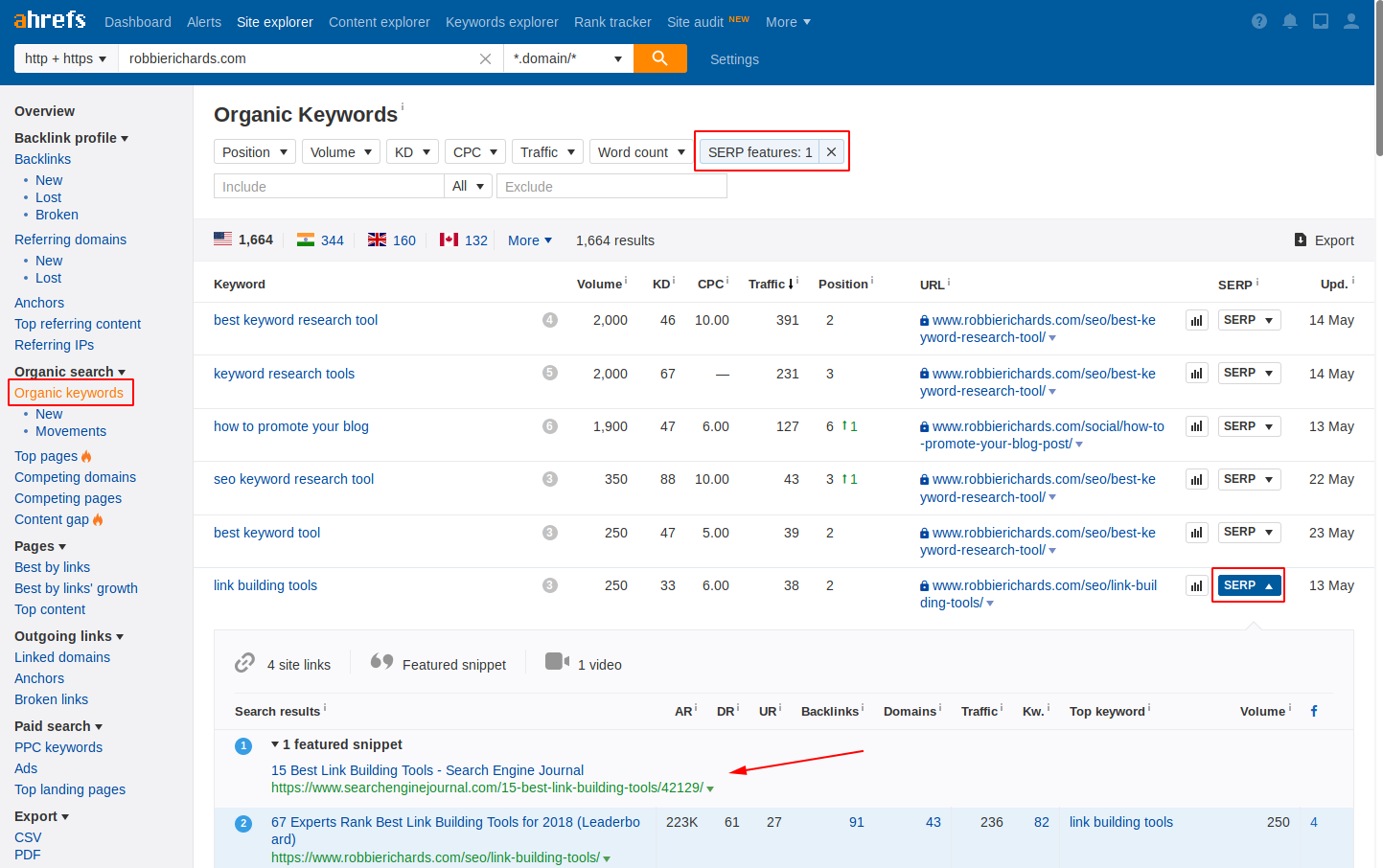
Автор статьи искал их с помощью параметров фильтрации ключевого слова в Ahrefs:
Перейдите в проводник Ahrefs и вставьте в свой домен.
Нажмите «Органические ключевые слова».
Откройте фильтр функций SERP и выберите «Featured Snippet»:
Окно настройки в проводнике Ahrefs
Вы увидите список всех ключевых слов, на которых размещается сайт на первой странице в блоке с ответами. Оптимизируйте ваши страницы под эти ключи.
Еще в этом может помочь SEMrush: откройте SEO Toolkit > Organic Research, введите свой сайт и перейдите на вкладку «Позиции»:
Вкладка с позициями
В раскрывающемся меню «Функции SERP» нужно выбрать «Домен не ранжируется» > «Расширенный сниппет»:
Вкладка с позициями
Это позволит открыть список всех ключей, по которым ваш сайт занимает топ, но не имеет расширенного сниппета.
Далее можно добавить фильтр, чтобы показать запросы, по которым ваш сайт находится в топ-3:
Фильтр топ-3
Над этими страницами можно поработать, чтобы попробовать занять блок с ответами.
Следить за позициями своего сайта можно и в сервисе от PR-CY «Анализ сайта». Следите за позициями сайта по интересным вам запросам в Яндексе и Google, следите за динамикой по регионам и устройствам. Сервис умеет учитывать поддомены.
Отслеживание позиций в Анализе
В сводке по регионам видны изменения средней позиции и топов, вы сами устанавливаете интересующий вас временной период. Кликните на нужный регион и сервис построит график, чтобы вы оценили среднюю позицию.
Сводка по регионам в Анализе
Пример от Робби Ричардса. Подробный материал с инструментами построения ссылок находится на первом месте по запросу «инструменты линкбилдинга», а в сниппете с ответами был фрагмент статьи Search Engine Journal’s с кратким перечислением инструментов:
Блок с ответами и ссылка на статью с инструментами
Сама статья Search Engine Journal’s была на третьем месте в выдаче, а более подробная статья автора на первом. Учитывая, что число ссылочных доменов и ранжирование ниже, не сразу понятно, почему в блоке ответов не полная статья автора с инструментами, а материал из журнала.
Скорее всего дело в форматировании. Посмотрите на подзаголовки на странице Search Engine Journal’s, которая попала в блок с ответами:
Статья из блока с ответами
Google часто берет теги H2, когда формирует список, и здесь произошло то же самое.
Пост автора статьи более подробный, глубокий, но отформатирован по-другому:
Углубленная статья с инструментами, не попавшая в блок
Google берет заголовки для пунктов списка, а в этой статье нельзя выделить заголовки, которые бы помогли ответить на пользовательский запрос. Списки инструментов отформатированы как абзацы (< br >), а Google, скорее всего, ищет нумерованные списки (< ol >) или маркированные списки (< ul >).
Хотя в этом материале со списками все в порядке:
Материал со списками
Видимо, нельзя с точностью угадать, как сработает принцип построения блока с ответами на основе содержания статьи.
Что автор статьи мог бы сделать, чтобы его материал попал в блок ответов? Самый очевидный вариант — включить в статью новый раздел с нумерованным или маркированным списком рекомендованных инструментов. Что-то вроде этого:
Пример списка инструментов
Тогда Google будет проще понять «лучшие инструменты», перечисленные в материале. И, поскольку пост уже занимает первое место, у него будет отличный шанс перейти вверх в блок с ответами.
2. Найти новые ключевые слова
Второй способ подразумевает поиск новых ключевых слов. Можно найти запросы, по которым Google показывает расширенные сниппеты, и попытаться занять их место.
Автор снова обращается к Ahrefs:
Введите ключевое слово в Инструмент Keyword Explore.
Перейдите в Phrase Match report > Search Features > Featured Snippet.
Пример поиска по ключу
По запросу «масло для бороды», сервис выдал 362 разных блоков с ответами на сопутствующие ключи.
4. Нажмите на раскрывающееся меню в разделе SERP, чтобы открыть сайт из блока с ответами:
Данные из раздела SERP
В этом примере блок с ответами принадлежит сайту baldingbeards.com.
5. Скопируйте URL-адрес домена и вставьте его в Site Explorer.
6. Перейдите к категории Organic Keywords > SERP Features > All Features > Featured Snippets, чтобы просмотреть список всех ключевых слов, по которым ранжируются блоки с ответами.
Результаты из раздела Featured Snippets
В результате сервис покажет 53 773 различных поисковых запросов для этой темы, где есть блок с ответами.
Если вы хотите еще больше сузить результаты и увидеть только ключевые слова, по которым в поиске выходит этот конкретный сниппет, то укажите целевой домен в списке:
Указываем целевой домен
Теперь сервис показывает список из 2 284 ключевых слов:
Результаты по домену
Если набор ключевых слов по-прежнему слишком большой, можно наложить и другие фильтры: KD, Volume, Word Count.
Далее следует проанализировать блоки с ответами, которые заняли конкуренты, чтобы увидеть, можно ли украсть у них эту позицию.
Другой вариант — использовать SEMrush. Введите ключ в инструмент Keyword Magic Tool, выберите вкладку «Сопоставление фраз» > Расширенные фильтры, а затем выберите «Рекомендуемый фрагмент» в раскрывающемся списке «Функции SERP»:
Функции SERP
Для ключа «масло для бороды» Робби Ричардс нашел 877 различных расширенных сниппетов. Далее он предлагает кликнуть по результатам и увидеть сайт, который сейчас занимает блок с ответами.
Сайт с расширенным сниппетом
В этом примере лидирует сайт baldingbeards.com. Дальше нужно скопировать URL и вставить его в SEO Toolkit. Убедитесь, что в раскрывающемся списке выбран точный URL:
Анализ конкурента из расширенного сниппета
Чтобы увидеть только те запросы, по которым конкурент занимает расширенный сниппет, нужно открыть Точное ранжирование URL > Расширенный сниппет:
Фильтр по расширенным сниппетам
В итоге у Ричарда получился список из 110 ключевых слов, по которым его конкурент — сайт baldingbeards.com — занимает блок с ответами.
Автор посмотрел статьи этого сайта и понял, что каждая статья отформатирована похожим образом: строится на основе списка с тегами H2, которые и идут в маркированный список блока с ответами.
Пример блока с ответами сайта baldingbeards.com
Чтобы занять его место на нулевой позиции, нужно сделать следующее:
Написать более подробный оптимизированный обзор, включая большее количество продуктов.
Включить обзорную таблицу лидеров с лучшими продуктами во введении.
Упомянуть каждое имя продукта внутри тега H2.
Поставить заголовок «подробный обзор лучших средств для ухода за бородой» ближе к списку во введение.
К примеру, как поступили BuiltVisible: написали заголовок около списка, чтобы он попал в заголовок сниппета:
Текст около списка в материале
Что попало в сниппет:
Блок с ответами со ссылкой на материал
Это даст вашему сниппету более высокий CTR и увеличит шансы надолго задержаться в нулевой позиции.
Как оптимизировать контент, чтобы попасть в блок с ответами
1. Включите в материал списки и резюме
Чем проще вы сделаете контент для Google, тем вероятнее он предоставит вам место в блоке с ответами. По этой причине выбор правильного ключевого слова — это только половина битвы. В материале должны быть нумерованные или маркированные списки, в которых содержатся ключевые моменты или резюме статьи.
Например, посмотрите на блок с ответом по запросу «как помыть собаку»:
Сниппет на запрос «как помыть собаку»
В тексте по ссылке есть список, который Google и подтянул в сниппет.
Список в тексте
Аналогичным образом на сайте Fossbytes список лучших инструментов составлен в формате списка, а каждый элемент помечен тегом H2.
Статья на сайте
И Google переформатировал надписи с тегом в списки для блока с ответами:
Расширенный сниппет со списком
В списке 15 позиций, а в сниппете отображается всего восемь, поэтому пользователю предложено открыть полный список по щелчку.
2. Сформулируйте ответ четко и лаконично
Для блока с ответами Google ищет короткий текст — около 50 слов, он должен давать прямой ответ на поисковый запрос.
Википедия — мировой лидер в сниппетах. Каждая статья содержит полезный ответ на запрос в первом предложении и содержание. Возьмите страницу из Википедии, введите ключевое слово и результат будет похож на словарное определение.
Сниппет со ссылкой на Википедию
3. Обратите внимание на вопросы, предлоги и сравнения
В исследовании Gerggich & Co проанализировали 30 различных ключевых слов, разделенных на вопросы, предлоги и сравнения. В результате определили, какие вопросы популярнее в блоках с ответами:
Google хочет увеличить вовлеченность и лояльность, предоставив пользователям ответы на популярные вопросы и топики форумов сразу в ленте выдачи.
Составляющие блоков с ответами
Gerggich & Co обнаружили, что слова «как» (46,91%) и «есть» (17,71%) встречаются в большинстве ключевых слов, по которым появляются блоки с ответами, а «кто» (16,2%) чаще всего встречалось в сниппете-таблице.
Почти все ключевые слова с вопросами выводят в результатах сниппет:
Доли вопросов в расширенных сниппетах
Google будет тянуть из вашего контента в сниппет абзац, который дает прямой ответ на вопрос пользователя.
Для доработки материала понадобятся ключи. Автор воспользовался сервисом Ahrefs, чтобы найти ключи с вопросами для таргетинга:
Введите ключевое слово в Ahrefs Keyword Explorer, настройте фильтр вопроса на левой боковой панели:
Панель сервиса
Вы можете использовать Answer the Public, чтобы получить список популярных вопросов в своей нише.
Answer the Public может выдать вам либо визуальную карту ключевых слов, разделенных по их типу, либо экспортируемый файл, который вы можете использовать в работе:
Визуальная карта ключевых слов по запросу «open source»
Но не нужно останавливаться на вопросах, в ключевых словах также популярны определенные предлоги и фразы для сравнения.
Ключевые слова для сравнения, такие как «цена», «лучший» и «сравнить», дают больше шансов для попадания в блок с ответами.
Примеры использования слов для сравнения
4. Работайте с другими показателями сайта
Подробное исследование Ларри Кима, основателя компании интернет-маркетинга WordStream, показало, что ранжирование сайта, продолжительность его посещения влияет на шанс занять нулевую позицию:
Зависимость времени посещения сайта
Результаты исследования Ларри позволяют предположить, что Google ориентируется на показатели взаимодействия с сайтом.
Есть много факторов,которые влияют на взаимодействие с сайтом:
время, проведенное на странице;
полезный контент;
скорость загрузки сайта;
кроссплатформенность;
читабельность;
мультимедиа;
качество копирайтинга.
5. Используйте микроразметку
Микроразметка помогает поисковику понять содержание страницы. Google не гарантирует, что структурированные данные будут отображаться в результатах поиска, даже если ваша страница размечена правильно, тем не менее, это стоит сделать.
Помимо привычных разметок для статей, рецептов и товаров можно использовать разметку FAQ, HowTo и Q&A.
Разметка FAQ
«FAQ» – страница с ответами на часто задаваемые вопросы, ответы с вопросами берутся с одной страницы.
Пример размеченного FAQ
Разметка описана в Справке с примерами готового кода.
Увеличить CTR с помощью разметки FAQ
Пользователь Витя Смертный поделился своим опытом: благодаря разметке FAQ удалось увеличить CTR на 38,42%.
Оптимизатор работает с проектом Автопортала, сайту 9 месяцев. Автомобильная тематика очень конкурентна, продвижение стоит дорого, у этого проекта нет возможности конкурировать с сайтами, которые работают по пять-десять лет и держат топы.
Чтобы компенсировать минусы, нужно выделить сайт в выдаче, для этого решили использовать разметку FAQ. Подобрали вопросы, которые интересовали реальных пользователей: идеи брали из личного опыта, сервисов и подсказок поисковых систем.
Блок с вопросами и ответами не будет очень выделяться, поэтому для привлечения внимания использовали заметные эмодзи, примерно описывающие суть вопроса.
Сначала блок FAQ не выводили в видимой части сайта: он был в коде сайта, но не на странице, видимой пользователю. Поисковик не воспринимал такой FAQ, но как только его вывели на страницу, то в выдаче появился сниппет:
Сниппет с вопросами и ответами в выдаче
Такой сниппет выглядит привлекательнее и кликабельнее. После месяца ожидания посмотрели статистику. CTR вырос на 38,42%:
CTR сниппета вырос
Разметка How-to
«How-to» — пошаговая инструкция для выполнения действия. Например, так выглядит разметка пошаговых действий, если к каждому действию добавить картинку:
Разметка под пошаговые действия
Как настроить How-to, описано в Справке с примерами кода разметки в форматах JSON-LD и Микроданные.
Разметка Q&A
Q&A — ответы разных пользователей на вопрос. В FAQ были собраны вопросы и ответы от лица компании, а здесь на вопрос дается несколько ответов пользователей.
Пример разметки QA
Установка описана в Справке с примерами разметки в форматах JSON-LD и Микроданные.
6. Добавьте страницу в Search Console
Не ждите, пока Google заметит ваш новый оптимизированный контент. Используйте Search Console, чтобы быстро проиндексировать его. Перейдите в Search Console и откройте Сканирование:
Search Console
Это отправит страницу в Google и для повторной индексации. Даже если ваша страница уже проиндексирована, добавьте ее еще раз, чтобы быстрее обновить ее в результатах поиска и попасть в сниппет.
Почитать по теме: Как ускорить индексацию сайта в Яндексе и Google
Продвигать интернет-магазины в поисковиках можно разными способами, на выбор метода влияет то, на каком поисковике стоит сосредоточиться в большей степени, какой магазин нужно продвигать и какие есть для этого ресурсы. В материале приоритеты Яндекса и Google в поисковой оптимизации и работающие методы seo для интернет-магазинов.
Нужен ли текст на сайте интернет-магазина
Один из факторов ранжирования в поисковиках — полезность ресурса, сайт должен дать пользователю исчерпывающую информацию по его запросу в удобном и понятном виде. Но кроме этого, для поисковиков важны и другие факторы. Яндекс дает больший приоритет качественным текстам, чем Google, а для Google обязателен ссылочный профиль сайта, поэтому для seo-стратегии нужно понимать, какой поисковик для нас важнее.
Посмотрим на первые десять результатов выдачи по запросу «купить холодильник».
Наличие seo-текста на сайте
Сайты, где есть тексты, находятся выше в выдаче, поэтому логично предположить, что нужно писать тексты, чтобы попасть на топовые позиции.
Но изучим внимательнее: на верхних позициях находятся популярные магазины и площадки — M.Видео, Mediamarkt, Эльдорадо, Авито и другие. В Яндексе у этих магазинов есть приоритет в ранжировании, поскольку у таких сайтов высокий type-In — количество прямых переходов на сайт, связанное с запросами по названию бренда. К примеру, пользователь ввел «Эльдорадо» в поисковик и перешел на сайт магазина Эльдорадо.
Ввод в Яндексе
Эффект такого type-In в Яндексе начинает ощутимо проявляться, когда сайт ищут больше 1 000 000 человек в месяц, поэтому у крупных брендов появляется дополнительный фактор ранжирования.
На примере с запросом «купить холодильник» видно, что некорректно говорить о значимости текстов на страницах. Сайты могут быть в топе совсем по другим причинам.
По запросу «купить угловой диван» в выдаче появились сайты, которые не имеют такого высокого показателя type-In.
Наличие seo-текста на сайте
Тексты на страницах есть только у двух ресурсов из десяти, причем они находятся не на первых местах в выдаче. Из этого примера следует вывод, что совсем не нужно писать тексты для сайта магазина.
Есть точка зрения, что seo-текст должен решать следующие задачи:
в нем можно использовать длинные ключи;
он делает контент на странице уникальным;
дает плюс к ранжированию.
Это спорные пункты.
С одной стороны, в текстах можно использовать сложные составные ключи, которые больше никуда не поставишь. С другой стороны, некоторые неестественные запросы, по которым чаще всего ищут пользователи, все равно не получится употребить в тексте из-за риска попасть под пессимизацию Яндекса.
Текст делает контент уникальным, но на листинге товаров будет много уникальных позиций со своими характеристиками, поэтому текст для этого может не понадобиться.
И непонятно, дает ли текст действительный плюс к ранжированию. В топе могут быть сайты с текстом и без него, поэтому стоит написать качественный текст, разместить его на сайте и проверить на собственном примере, как он будет работать.
Почитать по теме: Как сделать пагинацию: актуальные методы 2020
Когда текст точно нужен
Есть особенные случаи страниц с контентом, для которых текст действительно важен и может помочь в ранжировании.
Листинги с неуникальным контентом
Если пользователи называют по-разному один и тот же тип товара, будет сложно сделать категории под каждый запрос, потому что товары остаются одинаковыми. К примеру, смартфоны могут в том числе искать по запросам «мобильные» и «сотовые телефоны». Задачу уникализации контента может взять на себя текст.
Некоторые seo-специалисты делают страницы уникальными, меняя порядок товаров или вид отображения. Такой способ может негативно влиять на конверсию из-за перестановок товаров, так что безопаснее написать тексты.
Деление каталога смартфонов на множество разделов
Малое количество товаров
Листинги, где мало товаров, могут выпадать из выдачи как не очень качественные, либо склеиваться друг с другом в поиске. В этом случае можно добавить текстового контента и таким образом сделать страницу уникальной. Есть и другие методы: имитировать большой ассортимент, разделив товары по свойствам и характеристикам, добавить блок «часто покупают», где товары будут те же, но с другими анкорами.
Деление одинаковых товаров по цвету
Текст на листингах
Пользователи, которые перешли в каталог, редко читают текст, им интереснее сразу смотреть товары. Поэтому лучше поместить текст внизу, под перечнем позиций. Текст над каталогом может отвлекать и упадет конверсия.
Текст над каталогом
Текст под каталогом
Тексты можно коллапсировать, то есть показывать небольшой фрагмент начала, а остальную часть скрывать под «читать далее» или «открыть полностью». Поисковики не наказывают за коллапсирование текста, если тексты качественные.
Часть текста скрыта под «читать полностью»
Такой текст пишется не для того, чтобы его читали пользователи, но тем не менее он должен быть уникальным и читабельным, иначе за неестественные конструкции и переспам можно получить санкции. На продвижение не влияет оформление текста, типографика и его фактическая полезность, но это важно для тех пользователей, кто все-таки доберется до текста и прочитает его.
Текст на карточках товаров
Тексты на страницах каталогов пользователи обычно не читают, но карточки товаров изучают внимательно, чтобы узнать больше. Поэтому, раз их читают, то писать нужно, ориентируясь на людей, а не только на алгоритмы.
Многие магазины размещают в одном месте на карточках товара и характеристики, и отзывы, и обзоры, и описания. Так делать не рекомендуется, чтобы не смешивать интенты. В Яндексе для ранжирования важен интент: запрос на карточку товара будет коммерческим, а запрос на отзывы или обзоры — информационным.
Карточка товара с отдельными вкладками
Если все будет на одном месте, для ранжирования будет непонятно, что это за страница — информационная с полезным контентом или коммерческая? Поэтому рекомендуется разделять отзывы, описание и характеристику, и назначать им отдельные URL. Имеются в виду не якоря на одной странице, а отдельные страницы со своими адресами.
Разные URL для вкладок
Если на сайте крупного интернет-магазина карточки разделены на коммерческую и информационную составляющую, то по информационным запросам они смогут бороться за трафик с крупными отзовиками, как IRecommend, Otzovik и другие.
У разделения информации на карточке есть и свои минусы: не всегда получается сделать так, чтобы все страницы прошли индексацию со своими интентами. Может возникнуть проблема, что разные страницы одного товара, будут недостаточно уникальны.
Иногда проще оставить всю информацию на одной карточке, тогда характеристика и отзывы будут сами по себе уникальны и добавочные меры не понадобятся. Это сработает в том случае, если тексты отзывов и характеристики товара не будут скопированы с других источников. Тогда описания делать в принципе не нужно, но можно использовать текст для внедрения дополнительных ключевиков. К тому же, по запросам со смешанным интентом карточки без разделения ранжируются лучше.
Как настроить поддомены для регионов
В Яндексе для ранжирования товаров по разным регионам нужна региональная привязка доменов. Настраивается она несложно, но добавляет seo-специалисту проблем с оптимизацией.
Региональный субдомен
С ранжированием региональных субдоменов часто возникают проблемы. Распространено мнение, что причина может быть в неуникальных текстах, но чаще дело в некорректной работе справочника. Региональные офисы могут оказаться привязанными не только к субдоменам, но и к основному домену, поэтому ранжирование некорректно. Привязка может появиться, даже если вы не добавляли основной домен сами, поэтому стоит периодически проверять и отвязывать региональные офисы от основного домена.
Региональность работает только в Яндексе, в Google не предусмотрено как таковых регионов, поэтому в вебмастере Google лучше закрыть региональные папки от индексации.
Ссылочное продвижение для Яндекс и Google
При работе со ссылками, ориентируясь сразу на две поисковые системы, нужно быть аккуратнее: техники построения ссылочного профиля для каждого поисковика разные, и можно попасть под санкции Яндекса, если ориентироваться на Google, и наоборот.
Как поисковики относятся к ссылкам:
Яндекс
Нужны анкорные ссылки, спам безанкорными ссылками попадет под Минусинск.
Можно получить санкции за хостовые ссылки или ссылки на конкретные документы.
Важна ссылка на конкретный продвигаемый ресурс.
Google
Работают безанкорные и анкорные ссылки.
Важна ссылка на сайт или страницу-хаб.
Если поставить ссылку на страницу-хаб, то при попадании в топ там окажутся и теги, категория с брендом.
Google лучше приспособлен для работы со ссылочным профилем.
Чтобы избежать санкций от поисковиков, настраивают проксирующие прокладки: через них на основной домен идет 301 редирект, и ссылочный профиль направляется под разные поисковики. Если Яндекс или Google наложил санкции, прокси-прокладку вместе со ссылочным профилем снимают.
Виды ссылок
Арендные ссылки
Хороши тем, что их легко купить и легко снять при Минусинске, а также можно найти ссылку с большим весом для Google. Но, как правило, такие ссылки есть преимущественно на заспамленных площадках, и для Яндекса нужно слишком много ссылок.
Вечные ссылки
Их проще найти на незаспамленных площадках, к тому же это будет ссылка из контента, что важно для Google. Но минус в том, что при санкциях их сложно снять, они обычно дорогие и передают малый вес. С количеством ссылок для Яндекса то же самое — их слишком мало. Покупать рекомендуется только через прокси-прокладку, чтобы в случае санкций снять.
Размещение с целой площадки
Можно выкупить всю площадку и размещать на ней только свои ссылки. Вы получите много ссылок за небольшую цену, что хорошо для Яндекса, но для Google такие площадки будут иметь слишком мало веса.
Крауд
Есть еще третий способ получения ссылок, которым еще некоторые пользуются — крауд-маркетинг, то есть размещение ссылок в комментариях и на форумах. Это устаревший метод, такие ссылки не работают на ранжирование.
Почитать по теме: Сколько ссылок nofollow и dofollow должно быть на сайте
Как работать со ссылками
Определяем, какой поисковик приоритетнее, и будем ли работать и с Яндекс и с Google одновременно.
Размещение ссылок определяем тем, как на сайте построен поисковый спрос, где он сосредоточен — в карточках товара, тегах или где-то еще. Где больше спрос, там и работаем со ссылками.
Делаем два ссылочных профиля с прокси-прокладкой для Яндекс и Google.
Начинаем закупку ссылок.
Метод прогона, то есть массовой закупки ссылок на форумах, в отзывах и на сайтах-каталогах, использовать не рекомендуется из-за риска санкций. Но практика показывает, что при соблюдении минимальных правил Google может закрыть на это глаза.
Сквозные ссылки, проставляемые в шаблон сайта, лучше использовать только с анкорами, в Яндексе безанкорные ссылки не работают.
В заключение
Если Яндекс или Google посчитали некоторые страницы сайта недостаточно качественными, они будут плохо относиться ко всему ресурсу. Важно удобство сайта, полезность и соответствие актуальным алгоритмам ранжирования. Для продвижения в Google очень важны ссылки, а для работы в Яндексе приоритетнее сосредоточиться на текстах.
Почитать по теме: Как выбрать и подключить платежный сервис на сайт и как принимать платежи без сайта
За конспект лекции « Классическое SEO в интернет-магазинах» Алексея Чекушина спасибо Рустему Низамутинову, ведущему SEO-специалисту в «Реаспект».
Если сайт плохо индексируется поисковыми системами, он недополучит органического трафика. Поэтому в агентстве «Реаспект» принято за стандарт проводить клиентам постапдейтную аналитику. Цель этой работы — поиск и устранение ошибок в индексации сайта.
Частоту постапдейтной аналитики определяем в зависимости от размера сайта:
небольшой сайт услуг до 500 страниц — 1 раз в месяц;
интернет-магазин или портал от 1000 страниц — 2-4 раза в месяц.
Для первого анализа данные берутся за весь доступный период, а последующие отчеты собираются за период между проведенными анализами.
В статье руководитель отдела поискового продвижения Руслан Фатхутдинов рассказывает, как они проводят эту работу в агентстве, на что обращают внимание и как исправляют типовые ошибки.
Минимальный требуемый инструментарий бесплатен и доступен каждому — это консоли поисковых систем: Яндекс.Вебмастер и Google Search Console.
#1 Все домены для сетки должны «настояться» прежде чем ставить с них ссылки #2 Ссылочный профиль домена обнуляется, когда освобождается домен #3 Монетизация PBN негативно сказывается на эффективности ссылок с сетки #4 Для PBN необходимы позиции и трафик, чтобы ссылки с сетки давали эффект #5 Контент на сайте в сетке нужно восстанавливать со старого сайта #6 Аккаунты Google, подтвержденные по телефону, усиливают эффект от ссылок с PBN #7 Надо избегать регистрации просроченных доменов через серых регистраторов #8 Чем чаще менялся владелец домена, тем хуже работают ссылки с него #9 Можно обмануть Google, что владелец домена не поменялся, используя те же nameservers #10 Объединение всех подтвержденных теорий повлияет положительно
В заключение
В марте 2017 года в алгоритме Google произошли изменения, которые сильно повлияли на PBN — закрытые сети сайтов — как стратегию ранжирования.
Справка:
PBN, Private Blog Network — сеть тематических сайтов или блогов, которая создается для наращивания ссылочной массы продвигаемому ресурсу. Они будут ссылаться на сайт, помогая продвижению страниц в поиске. Термин «PBN» обычно используют в англоязычных источниках, в рунете чаще говорят «сайты-сателлиты» или «закрытые сети сайтов».
Для создания сети блогов нужно купить авторитетные дроп-домены с обратными ссылками и трастом от поисковиков или зарегистрировать новые. Часто у SEO-компаний есть свои сетки по разным тематикам, поэтому можно обратиться к ним. Если создавать сетку самостоятельно, будет проще контролировать результат, но затраты могут быть выше. Дальше на этих сайтах размещают публикации со ссылками на ресурс, который нужно продвинуть.
Когда автор статьи создавал сеть сайтов-сателлитов Rank Club, он тестировал каждый отдельный домен, прежде чем добавлять его в сеть. Если ссылка на домен увеличивала трафик тестового сайта, его добавляли в сеть. В противном случае домен попадал в корзину.
Затем внезапно показатели стали стремительно падать. В зависимости от типа домена (с истекшим сроком действия или задержанный, отложенный или аукционный) трафик снизился как минимум на 20%, а около 50% доменов стали для сайта токсичными.
Ссылки с этих сайтов вредили ресурсу, и это шокировало автора, но тем интереснее было разобраться и найти решение: что изменилось у Google и как можно обернуть изменения в свою пользу?
Директор компании R&D Роб Рок, который сейчас также занимается проектом Rank Club, вместе с автором разработали десять тестовых экспериментов для заказных сеток сайтов, по которым проверили около 300 сайтов-сателлитов.
Как тестировали сайты-сателлиты
Схема от affiliatelab.im
Методика тестирования: выбирали домены, которые будут целевыми адресами, на них направляли тестовые ссылки, а дальше замеряли результат.
Целевые ссылки выбирали с такими качествами:
на них не было ссылок в течение года;
они ранжируются на второй-четвертой странице для некоторых неконкурентных ключевых слов;
у них никогда не было анкорных ссылок.
Хорошим примером будет выдача сайтов по запросу «Гарт Брукс билеты Нэшвилл 2015».
При выборе тестовых ссылок важно обратить внимание на два фактора, которые могут испортить тест:
Оптимизация: если вы определите неправильные анкоры, вы не сможете понять, как повлияла на сайт сеть блогов.
Внешние переменные: если на целевой URL ссылаются другие сайты, то не получится узнать, какой сайт стал причиной изменений, и протестировать сеть сайтов не получится.
Подробнее о плане тестирования
Примеры прохождения теста. На всех скриншотах дата начала работы стоит в черном поле.
График положительных результатов
График нейтральных результатов
График негативных результатов
Ситуация на начало теста
Позиции сайтов внезапно упали. В зависимости от типа домена, сайты-сателлиты оказывали разное влияние, но в целом ситуация ухудшилась.
Влияние по видам доменов
Стратегия, которой придерживался автор, стала неэффективной: если раньше аукционные домены давали лучшие результаты, то сейчас они оказывали положительный эффект на трафик с вероятностью 50%.
Нужно было проводить тестирование, чтоб проверить составленные автором теории.
Проверка теорий
#1 Все домены для сетки должны «настояться» прежде чем ставить с них ссылки
Подтверждено
В 2016 году автор обнаружил, что домены из сетки сайтов могут плохо влиять на продвигаемый ресурс, если они были созданы недавно.
Как тестировали:
Для теста взяли 20 освобождающихся доменов и 20 аукционных доменов, и сразу же поставили с них ссылки. Затем подождали 35 дней и повторили.
Разница результатов в сравнении между двумя тестовыми замерами:
Таблица влияния
Подтверждением теории будут отметки в зеленых полях. Домены поделились на три категории:
не удалось выполнить первый тест (Toxic);
проходит второй тест через 35 дней (Pass);
ничего не произошло (Neutral).
Эта ситуация похожа на то, что происходит с доменами с истекшим сроком регистрации. Такой же фильтр применяется к доменам, созданным недавно.
Выводы:
Аукционные домены показывали лучшие результаты, если выдерживалось время от создания до ссылок, по сравнению с задержанными доменами.
В обеих категориях все равно было много токсичных и нейтральных доменов, так что выдерживать время после создания домена — не универсальный способ.
Домены сайтов-сателлитов могут положительно влиять на сайт, даже если не выжидать от создания, а сразу работать со ссылками. Похоже, что выжидать не обязательно, но проверка теории показала, что это лучше влияет на позиции.
В итоге автор решил включить эту технику в работу, чтобы увеличить вероятность успеха.
#2 Ссылочный профиль домена обнуляется, когда освобождается домен
Опровергнуто
Версия такая: когда у домена заканчивается срок действия, он выходит на аукцион или становится задержанным, в таком случае Google сбрасывает ссылочный профиль до нуля.
Как тестировали:
Для теста взяли десять доменов каждого типа. Домен проходил тест, если Google не сбрасывал ссылочный профиль. В тесте участвовали домены с истекшим сроком, которые не использовались более года.
Итоги теста
По итогам теста теория оказалась ложной.
#3 Монетизация PBN негативно сказывается на эффективности ссылок с сетки
Не получилось подтвердить или опровергнуть
Чрезмерная коммерциализация сайтов может повлиять на их позиции в поисковой выдаче, также и с коммерциализацией сетки блогов. Перебор с монетизацией может уменьшить их положительное влияние на сайт, который продвигается.
Пример монетизации сайта-сателлита:
Сайт с монетизацией
Возможно, нужно убрать монетизацию? Автору не получилось проверить этот тест, поскольку монетизация на их сайтах была чисто косметическая.
Теорию не получается проверить, поэтому вопрос остается открытым.
#4 Для PBN необходимы позиции и трафик, чтобы ссылки с сетки давали эффект
Опровергнуто
Концепция звучит логично: если сайты-сателлиты имеют органический трафик, то значит они положительно воспринимаются Google, и могут использоваться как ссылки.
Как тестировали:
Автор собрал 158 сайтов из сетки, которые прошли тесты предыдущих экспериментов, и проанализировали их сервисами SEMRush, Ahrefs и Similar Web, чтобы оценить трафик.
Результаты анализа в таблице, сайты с больше сотни посетителей в месяц обозначены как «есть трафик», меньше ста — «нет трафика».
Диаграмма результатов
Несмотря на распространенное мнение, сайты-сателлиты могут не иметь трафика, чтобы быть позитивными ресурсами.
#5 Контент на сайте в сетке нужно восстанавливать со старого сайта
Подтверждено
Джейсон Дюк, член тестовой группы, на мозговом штурме рассказал о своем опыте: он смог сохранить контент с одного сайта на другой с помощью Wayback. В компании Diggity Links не получалось сделать также, поскольку нужно было полностью перестраивать WordPress. Вместо этого они использовали другой способ.
Как тестировали:
Из каждой категории взяли 20 сайтов-сателлитов. Нужно искать домены с сайта archive.org, чтобы вывести содержимое главной страницы из старого домена, и переместить его на новую версию сайта-сателлита на WordPress.
В компании назвали этот процесс «Duking» сайтов-сателлитов.
Затем проверили домены, чтобы узнать, изменилось ли их положение относительно исходного. В итоге результаты оказались такими:
Результаты теста
По итогу аукционные домены показали лучший результат от методики, но преимущество кажется незначительным.
Сохранение непрерывного потока контента кажется простым и дешевым способом значительно увеличить пропускную способность на истекших и аукционных доменах. Но тем не менее, если вы копируете содержимое чужих сайтов, будьте готовы к юридическим последствиям, даже если на домене истекает срок регистрации.
#6 Аккаунты Google, подтвержденные по телефону, усиливают эффект от ссылок с PBN
Опровергнуто
Большинство «реальных» сайтов связаны с Google Search Console, Analytics, Google+ или каким-либо другим проектом Google. Возможно, это влияет на доверие Google, когда дело доходит до ссылок.
Как тестировали:
60 учетных записей в проектах Google подключили к 60 сайтам-сателлитам, то есть по 20 сайтов в каждой категории. Дальше наблюдали на результатами:
Итоги тестов
Добавление не принесло каких-то ощутимых результатов. Судя по таблице, можно сказать, что результаты даже стали немного хуже, но все-таки выборка слишком мала, чтобы заявлять о таком эффекте.
#7 Надо избегать регистрации доменов через серых регистраторов
Подтверждено
Этот тест придумал prodigy SEO Яшар Гаффарло. Теория заключается в том, что не нужно покупать домены на подозрительных сайтах, как Xz, Pheenix, Dropcatch и т.д., поскольку у Google есть фильтр, наказывающий ссылки, созданные определенными регистраторами.
Как тестировали:
Было куплено 30 ссылок у различных регистраторов. В каждой группе по 10 сайтов:
Группа A: домены перемещены в Godaddy и связаны через 3 дня.
Группа B: так же, но связаны через 15 дней.
Группа C: так же, но связаны через 30 дней.
Итоги теста
Просто переместив эти домены на другого регистратора, вы сможете заставить токсичный домен работать на вас.
Как ни странно, лучший результат показывают задержанные домены после передачи другому регистратору, но, возможно, что корреляция ошибочна.
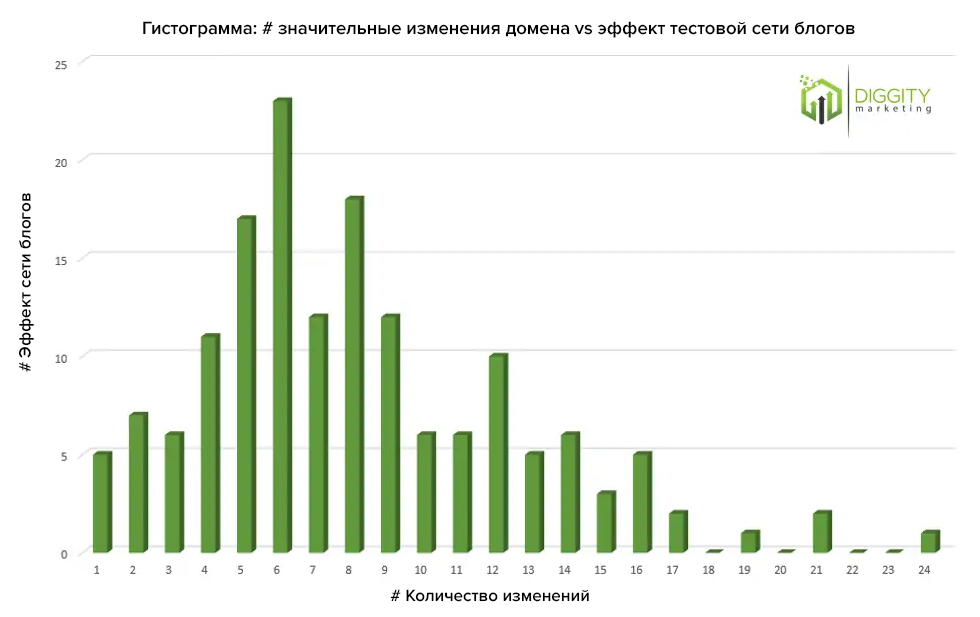
#8 Чем чаще менялся владелец домена, тем хуже работают ссылки с него
Подтверждено
Для теста взяли случайный домен, который был впервые зарегистрирован в 2008 году, но был передан между 20 владельцами, хостами и регистраторами. Будет ли он хуже домена, который был зарегистрирован в 2015 году, и у него было суммарно два владельца?
Как тестировали:
До этого теста эксперименты успешно прошли 158 сайтов. Авторы нарисовали гистограмму владельцев, изменений хоста, мени сервера и прочего, сопоставили с количеством успешно работающих доменов.
Результат:
Итоги теста
На первый взгляд по результатам видно, что сайт успешно пройдет тест, если в его истории будет меньше изменений. Но на практике не получится найти домены для сеток блогов с неизменной информацией, скорее всего за историю существования домена изменений будет не меньше десяти.
Чем меньше изменений, тем больше вероятность пройти тест.
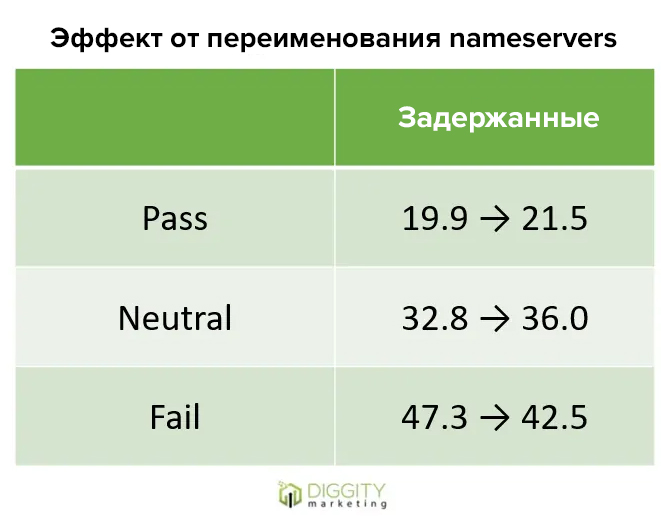
#9 Можно обмануть Google, что владелец домена не поменялся, используя те же nameservers
Не получилось подтвердить или опровергнуть
Джейсон Дюк дал еще одну идею, вытекающую из прошлого теста. Можно попробовать обмануть Google: он должен думать, что раз сервера имен не изменились со времени последнего владельца, то, следовательно, сам владелец тоже не изменился.
Как тестировали:
Типичные настройки сервера имен позволяют размещать четыре разных входа:
Nameserver 1
Nameserver 2
Nameserver 3
Nameserver 4
Можно попробовать установить два старых имени на два первых места, а фактические два сервера вписать в нижние.
Nameserver 1: ns1.oldserver.com
Nameserver 2: ns2.oldserver.com
Nameserver 3: ns1.ourserver.com
Nameserver 4: ns2.ourserver.com
Домены будут отображаться правильно, так как первые две строки будут ошибочны, и система будет по умолчанию использовать две нижних записи из списка. Если Google достаточно наивен и на самом деле смотрит на серверы имен как на указание изменения собственности, то обман может сработать.
Автор протестировал это на 20 доменах и посмотрел, помогло ли оно для увеличения пропускной способности сайта:
Не получилось каких-либо явных результатов, чтобы сделать однозначный вывод.
Результаты теста
Хотя результаты не вышли достаточно убедительными, автор решил использовать этот способ для коммерческих сайтов.
#10 Объединение всех подтвержденных теорий повлияет положительно
Подтверждено
Тесты показали, что некоторые из теорий выигрышные:
ожидание перед подключением домена;
постоянный контент;
использование доменов с небольшим количеством изменений собственности;
перемещение доменов из токсичных регистраторов.
Но будет ли положительный эффект, если объединить все советы из успешных тестов? Как это повлияет на сайты из сетки блогов?
Как тестировали:
Взяли 20 доменов из каждой категории, применили все успешные тесты и сравнили результаты с исходными. По итогу оказалось, что положительный эффект действительно растет.
Результаты итогового теста
В заключение
Управление сетками сайтов не просто включает в себя поиск, создание, обслуживание и обновление тысяч доменов, но и постоянное тестирование, чтобы реагировать на обновления алгоритмов поисковиков.
По итогу тестирования в компании автора статьи выяснилось, что подтвердились гипотезы:
Все домены для сетки должны «настояться» прежде чем ставить с них ссылки.
Контент на сайте в сетке нужно восстанавливать со старого сайта.
Надо избегать регистрации просроченных доменов через серых регистраторов.
Чем чаще домен освобождался и менялся его владелец, тем хуже работают ссылки с него.
Объединение всех подтвержденных тестов также даст положительную динамику.
Но даже выполняя все рекомендации, в работе будут встречаться домены, которые не дают ничего или даже приводят к отрицательному результату.
Архитектура сайта — это структура страниц и программной части сайта. Она позволяет представить все разделы проекта перед разработкой. В нее входит навигация по страницам, сеть ссылок, «хлебные крошки», страницы категорий, файлы карты сайта, контент и другие элементы, из чего сайт состоит.
Структура сайта — более узкое понятие, это логическое построение страниц, расположение разделов и их связь между собой. Работа со структурой — одна из методик SEO. Она влияет на работу пользователей с ресурсом и на восприятие его поисковыми роботами. Грамотно выстроенная структура направляет пользователей и ботов на важные страницы, помогает им найти на сайте то, что они ищут.
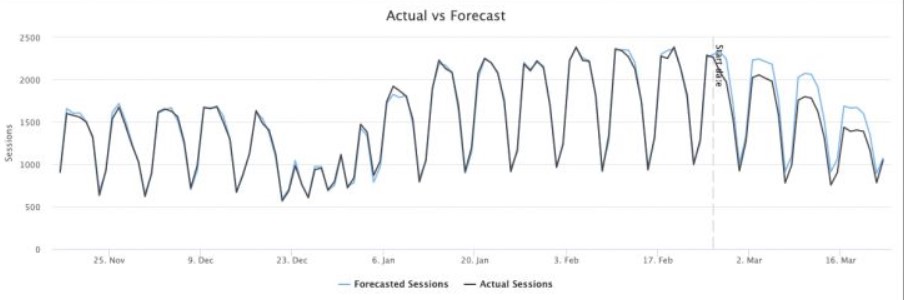
Свежей статистики у нас нет, но несколько лет назад Zyppy переработали неудачную архитектуру, использовав часть советов из этого списка на своем проекте. Они засекли рост трафика на 175% за несколько месяцев.
Рост трафика после доработки архитектуры
Если использовать все советы, трафик может вырасти еще больше.
Советы для работы с архитектурой сайта
15 пунктов, разделенных на тематические кластеры.
1. Удовлетворите потребности пользователей
Структура семантики основывается на трех составляющих:
Частотность спроса
Интент пользователя, нужна ли ему эта страница и зачем
Кластеризация собранной семантики по топу
Остановимся подробнее на интенте. Когда вы работаете с навигацией на сайте и внутренними ссылками, задайте себе три ключевых вопроса:
Что ищут пользователи?
Какую информацию им предложить?
Что еще им может быть интересно, то есть какие страницы связать друг с другом?
Приведите страницы в соответствие интентам — потребностям. Страница не будет хорошо ранжироваться, если на ней не тот контент, который хотят видеть пользователи. Как это сделать — рассказываем в статье.
Если страница удовлетворяет потребности пользователя, это показывают поведенческие факторы: уровень кликабельности сниппета в выдаче, время просмотра страницы, количество отказов и другие.
Этим же принципом нужно руководствоваться при составлении навигации, подбирая и связывая такие страницы, которые интересуют пользователя и нужны ему, чтобы закрыть все вопросы и сделать заказ.
Если сайт удачно построен, пользователь сможет максимально быстро решить свою проблему и найти на нем то, что нужно.
Почитать по теме: 5 принципов современного дизайна сайта: как сочетать минимализм, пользу и красоту
На сайте магазина REI большой каталог и много страниц, но они сделали четкую навигацию:
ссылки помогает людям быстро переходить на нужную страницу;
страниц много, поэтому контент структурирован по темам;
другие важные страницы видны вне навигации справа.
Пример хорошо построенной структуры для большого сайта rei.com
Все решения по перестройке структуры нужно принимать на основе данных по посещениям сайта и анализа своего ресурса, чтобы сделать сайт удобнее для пользователей и понятнее для поисковых краулеров.
Проведите аналитику и определите:
какие страницы имеют большую посещаемость;
какие совпадают с пользовательскими запросами;
с какими дольше взаимодействуют;
на каких выполняют конверсионные действия.
Страницы с высокими показателями по этим параметрам должны быть заметнее на сайте. Страницы с меньшими результатами скорее всего не так важны.
К примеру, если на страницу «О нас» мало переходов, когда она выделена в шапке и занимает важное место в навигации сайта, то скорее всего она не так интересна клиентам, и ее можно переместить, поставив на ее место в навигацию более важные страницы. Подробнее о том, как отследить конверсию и ранжирование, в статье.
Другое дело, если страница действительно важна для конверсии, на нее ведут CTA — конверсионные кнопки с других страниц, а переходов мало. Возможно, вы выбрали неудачный вариант CTA. Проведите A/B тестирование разных вариантов кнопок с разными текстами, поменяйте местоположение, внешний вид или формулировку. Как успешно провести тестирование, если опыта нет — в статье.
2. Упростите: важные страницы ближе к главной
Чем меньше кликов нужно, чтобы добраться до страницы, тем ее легче найти, а чем ближе она к главной, тем она важнее.
Многие оптимизаторы применяют «правило трех кликов»:
Ни одна важная страница на сайте не должна быть на расстоянии больше трех кликов от главной или другой страницы с высоким авторитетом.
Поисковый бот обходит страницы как бы ярусами: сначала главную, потом страницы второго уровня вложенности, затем третьего и так далее. Чем ближе страница к главной, тем быстрее он ее посетит. Ссылка на новый пост с важной страницы даст боту сигнал о том, что ее тоже нужно просканировать.
В этом плане правило трех кликов полезно. Но это скорее не правило, а рекомендация. Могут возникать ситуации, в которых это бессмысленно, но лучше стараться не размещать важные страницы далеко от главной.
Почитать по теме: Правило трех кликов — миф?
У вас может возникнуть вопрос: почему бы не связывать все страницы с главной, чтобы они все оказались важными? Есть минимум две причины так не делать:
Слишком большое количество ссылок имеет свои недостатки, к примеру, размывает авторитет, который можно было бы передать нескольким важным страницам.
Структура в один ярус лишает возможности организовать контекстуальную иерархию в контенте, а это важно для поисковых систем.
Как проверить уровень вложенности
Если на вашем сайте много страниц, будет тяжело определить количество кликов для каждой страницы вручную. Авторы предлагают воспользоваться сервисами для SEO-аудита, которые помогут определить уровень вложенности. К примеру, это Screaming Frog, Ryte, Moz, SEMrush и другие. У OnCrawl к тому же есть хороший отчет о внутренних ссылках.
Большинство сервисов считают уровень вложенности, начиная с главной страницы. Иногда это затрудняет понять общую структуру сайта, поэтому авторы отдельно рекомендуют сервисы для визуализации: WebSite Auditor и Sitebulb. К тому же это позволит найти одиночные страницы и связать их с чем-нибудь.
Визуализация структуры сайта от Sitebulb
Грамотно распределить вес и разместить важные страницы ближе к главной поможет четкая организация структуры сайта.
3. Проработайте структуру
На небольших личных блогах или сайтах местных пиццерий структура обычно несложная. Но большие порталы, к примеру, с 250 тысячами страниц требуют организованности и особого внимания.
Поместить важные страницы ближе к главной помогает так называемая плоская структура сайта, где для перемещения с главной на любую внутреннюю страницу нужно как можно меньше кликов, при этом все страницы связаны. Она помогает Google и другим поисковым системам сканировать 100% страниц сайта.
Плоская структура сайта. Источник backlinko.com
Такую организованную структуру можно сделать по модели SILO.
SILO-структура
«SILO» означает «бункер, «закрытая система». SILO-структура — это плоская структура ресурса, основанная на семантике контента, подразумевающая распределение тем по иерархии.
Страница-хаб объединяет контент в общую ветку, а структура SILO отвечает за распределение внутри этой ветки.
Схема SILO
Каждая ступень иерархии связана со ступенями выше и ниже себя. Это помогает пользователям ориентироваться и лучше понимать содержимое.
Страницы-хабы находятся вверху иерархии и обычно содержат:
навигацию, в том числе «хлебные крошки»;
контекстные ссылки;
структуру URL.
О них еще будет идти речь в материале. Важно то, что нужно группировать контент по темам и структурировать его от общей категории к конкретным позициям.
??
Что о структуре SILO думает Игорь Рудник, руководитель биржи Collaborator и сервиса крауд-маркетинга Referr:
«Если кратко — ничего лучше SILO-структуры нет.
SILO-структура — это в первую очередь про логику для пользователя, чтобы товары или статьи на сайте было легко найти. Конечно, в первую очередь это важно для интернет-магазинов и маркетплейсов, где большое количество позиций.
При этом, если структура сайта выстроена логично, то это дает вам следующие преимущества:
масштабируемость — вы сможете без проблем добавлять новые товарные категории, новые товары и ваш сайт все также будет оставаться понятным для людей и поисковых систем;
«дружба» с поисковыми системами — они смогут легко краулить, индексировать ваш сайт; это очень важно, когда у вас хотя бы десятки тысяч товаров, а тем более сотни тысяч и миллионы SKU;
легкая организация внутренней перелинковки — для логичной структуры легко организовать внутреннюю перелинковку».
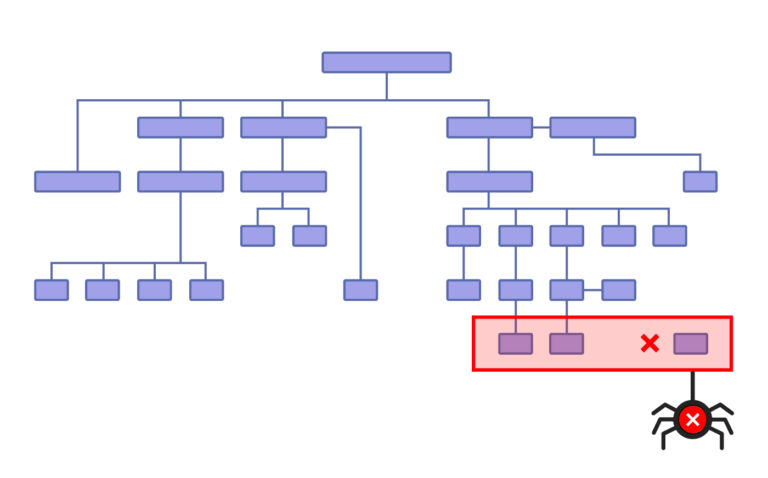
Если не внедрять структуру с родительскими категориями, а делать перелинковку без четкой системы, могут появиться так называемые страницы-сироты, на которые не ссылаются другие внутренние страницы сайта.
Страницы-сироты
Пользователи и боты ПС не смогут найти такую страницу во время перемещения по сайту, это вредит ее посещаемости и ранжированию.
Страница вне структуры. Источник backlinko.com
Если вы заметили, что какая-то из страниц проседает по трафику и позициям, проверьте внутренние ссылки.
Консоль поиска> Поиск трафика> Внутренние ссылки> введите URL своей страницы:
Проверка по консоли
На консоли появится количество ссылок и источники:
Ссылки на страницу
Если у страницы не оказалось ссылок, внедрите ее в вашу систему внутренней перелинковки: определите категорию, устройте перекрестный обмен ссылками со страницами схожей тематики.
Почитать по теме: Как настроить передачу ссылочного веса с помощью внутренней перелинковки
4. Задействуйте страницы-хабы
В SILO-структуре участвуют страницы-хабы — важные обзорные страницы с общей темой или категорией, которые объединяют дочерние категории и подробные темы в одну. Разберем, какими они должны быть.
Зачем нужны хабы:
Дают понять, о чем темы в этом разделе.
Отвечают на вопросы, которые могут возникнуть у пользователей.
Содержат ссылку на важные подтемы и категории продуктов.
Удобнее для пользователя, чем общие страницы категорий.
Делают тему значимой.
Пример хаб-страницы Consumer Reports:
Страница-хаб
Лучше, когда на страницу-хаб указывают много релевантных ссылок, чтобы они могли передать вес ссылок и на дочерние темы.
Страницы категорий часто сами по себе являются страницами-хабами, потому что часто уже содержат много естественных ссылок. Размещайте на таких страницах дополнительную информацию, кроме список подкатегорий или статей и продуктов, ставьте ссылки на релевантные страницы, которые помогут пользователю.
Проверить сайт по 70+ параметрам поможет сервис «Анализ сайта». Он проанализирует оптимизацию и технические характеристики главной и внутренних страниц, сравнит с конкурентами и покажет динамику позиций по регионам.
Неделю пробуйте расширенный тариф бесплатно и оставайтесь, если понравится!Попробовать
5. Используйте иерархическую структуру URL
При организации вашего контента часто лучше использовать URL-адреса, которые отражают структуру, то есть страницу-хаб и подкатегорию, где находится исходная страница.
Структура URL страницы
Зачем нужна иерархическая структура URL:
Пользователи могут по URL понять, где находятся.
Ключевые слова в URL-адресе могут помочь в ранжировании и CTR.
Плюс к ранжированию: Google использует показатели уровня вложенности страницы, чтобы какое-то время определять по этому важность и релевантность новых URL-адресов.
Некоторые веб-мастера «подделывают» плоскую структуру каталогов, размещая все URL-адреса в корне или ограничивая папки. Хотя этот метод может иметь свои достоинства, для Google важнее то, сколько кликов до перехода на страницу контента, а не сколько информации между слешами в ее URL. Размещение ваших страниц в разных категориях дает Google дополнительный контекст о каждой странице в этой категории.
6. Используйте HTML карту сайта
Почти все понимают важность HTML-файлов карты сайта, но такие файлы, встроенные в веб-страницы, встречаются все реже. Некоторые специалисты предлагают их вернуть.
HTML-карта сайта находится на сайте, но не в файле HTML, она доступна пользователям для чтения и предоставляет посетителям сайта и поисковым роботам подсказки о структуре сайта и актуальных ссылках.
В HTML-карте для газеты New York Times отражена каждая страница на сайте, они выстроены по дате, формату контента и теме:
HTML-карта New York Times
HTML-файлы карты сайта более эффективны на крупных сайтах, где структура сайта может быть очевидна не сразу, или маршруты сканирования не идеально оптимизированы. Но и сайтам помельче могут пригодиться карты сайта, поскольку они могут помочь пользователям ориентироваться.
7. Внедрите «хлебные крошки»
«Хлебные крошки» — навигационная цепочка по сайту, которая показывает путь SILO-структуры контента от корня сайта до страницы, на которой находится пользователь.
Крошки полезны для юзабилити, потому что помогают пользователю ориентироваться на сайте и возвращаться на предыдущие категории, а еще они добавляют внутренние ссылки на категории и подстраницы, так что поисковые системы индексируют ссылки из «хлебных крошек».
Их роль в структуре:
определение относительной позиции URL-адреса в иерархии;
связывание материалов внутри SILO-структуры контента;
 Расширенный сниппет в выдаче
Расширенный сниппет в выдаче Пример текстового сниппета
Пример текстового сниппета Пример сниппета с нумерованным списком
Пример сниппета с нумерованным списком Сниппет со списком характеристик
Сниппет со списком характеристик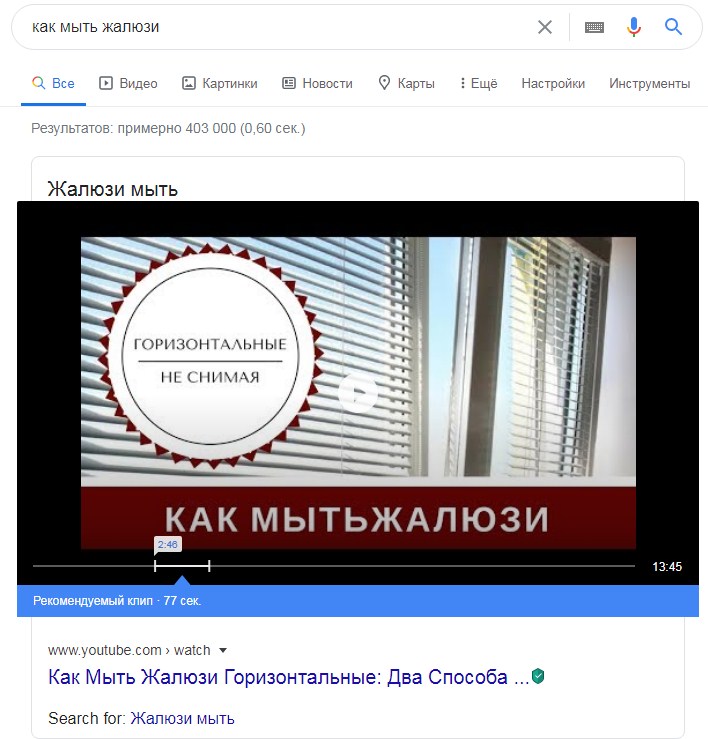 Сниппет из YouTube
Сниппет из YouTube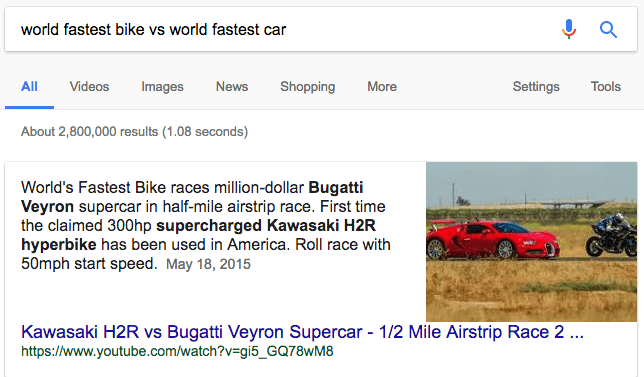 Пример блока с текстом из описания видео
Пример блока с текстом из описания видео Статистика по кликам
Статистика по кликам 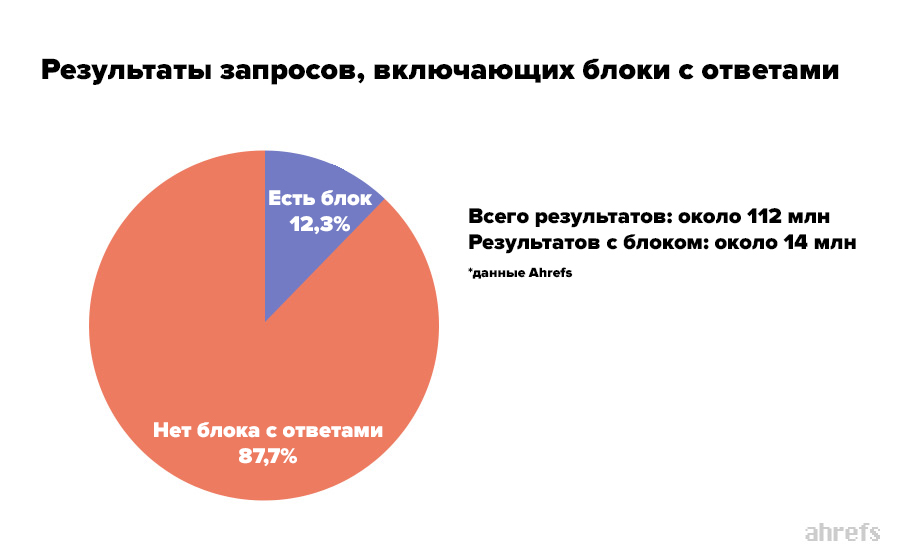 Данные по показу блоков с ответами
Данные по показу блоков с ответами 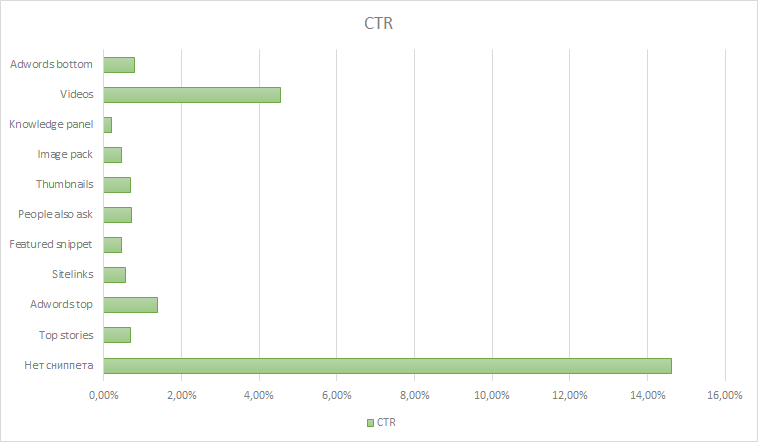 CTR разных элементов выдачи
CTR разных элементов выдачи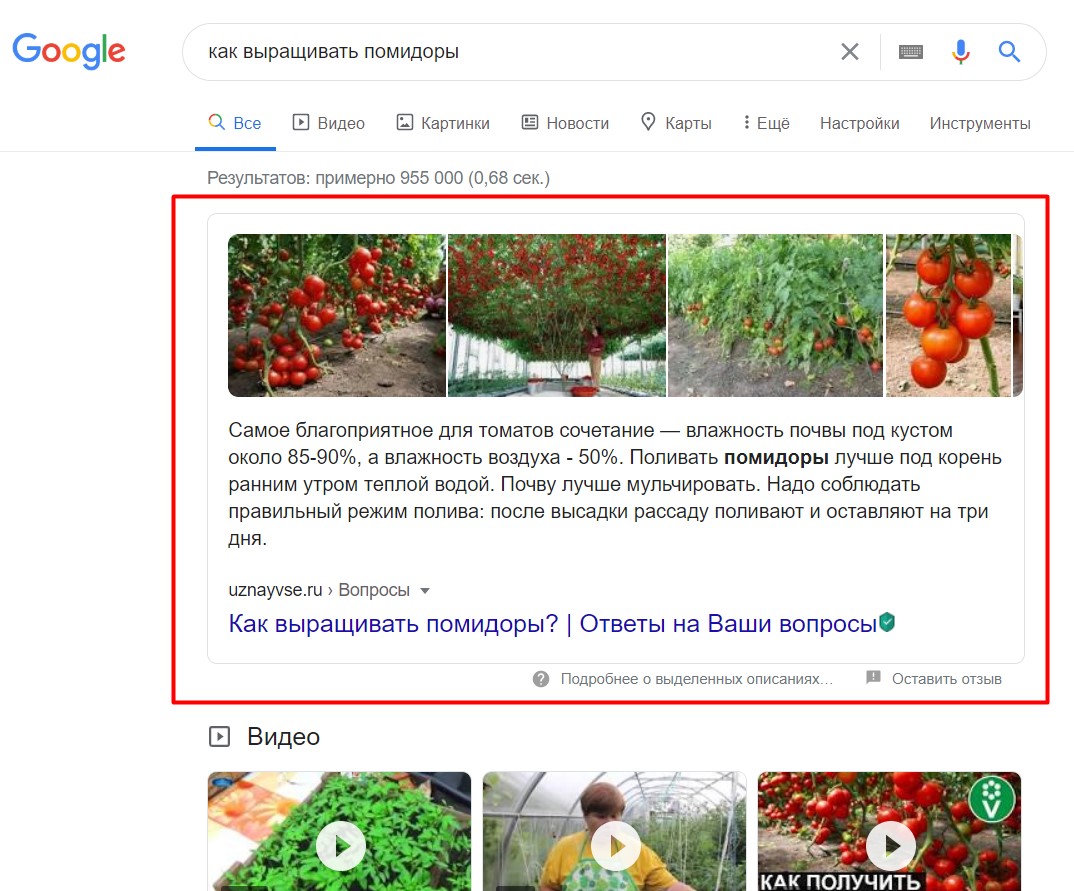 Пример блока с ответами
Пример блока с ответами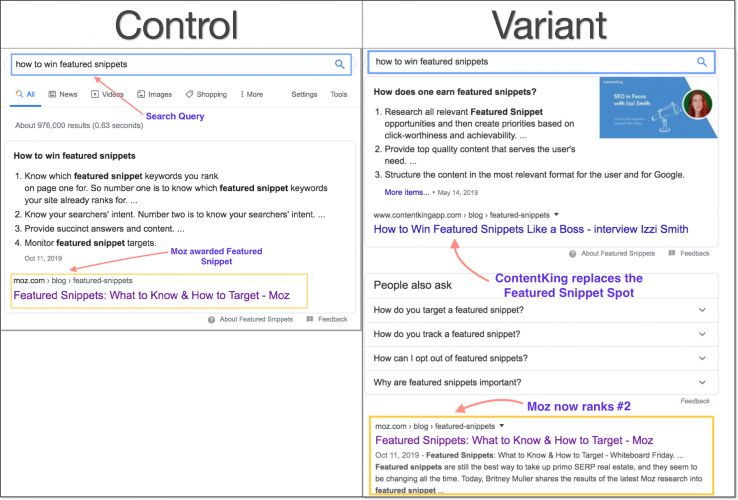
 Окно настройки в проводнике Ahrefs
Окно настройки в проводнике Ahrefs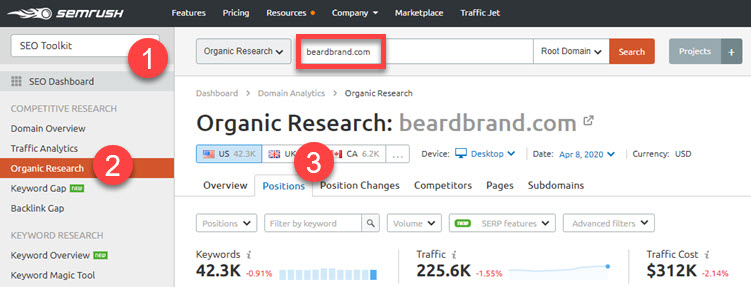 Вкладка с позициями
Вкладка с позициями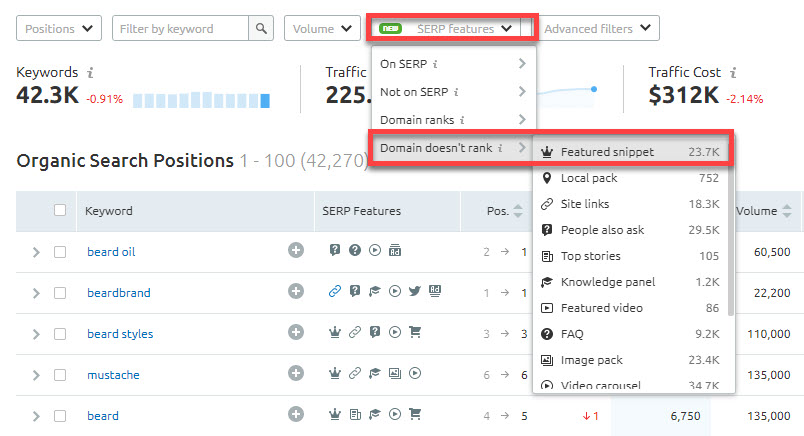 Вкладка с позициями
Вкладка с позициями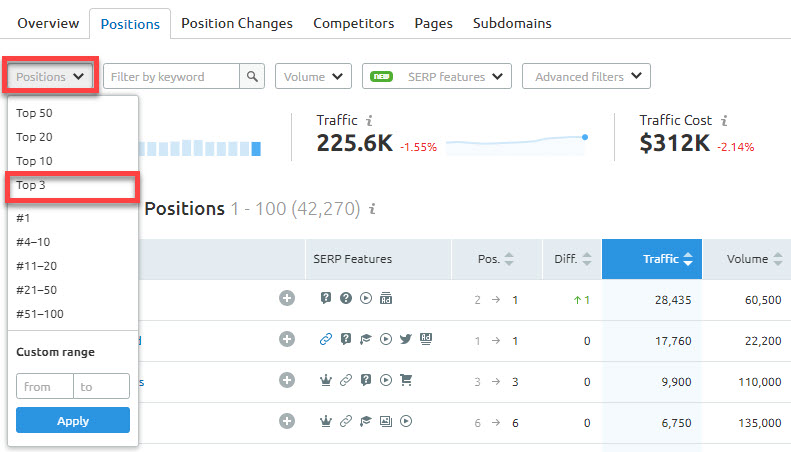 Фильтр топ-3
Фильтр топ-3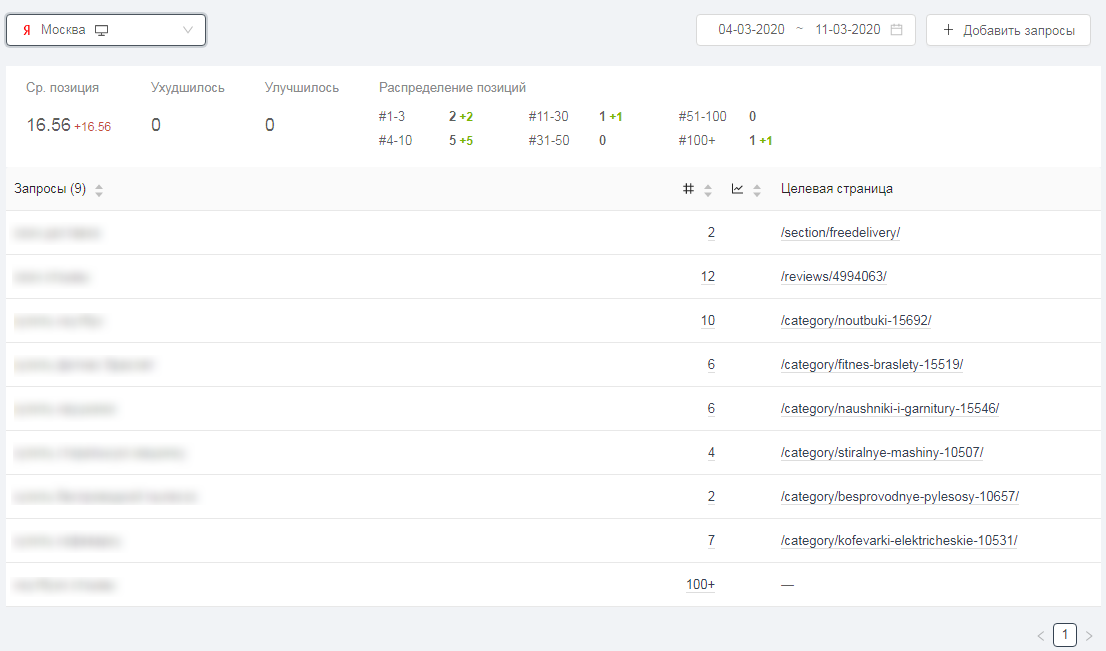 Отслеживание позиций в Анализе
Отслеживание позиций в Анализе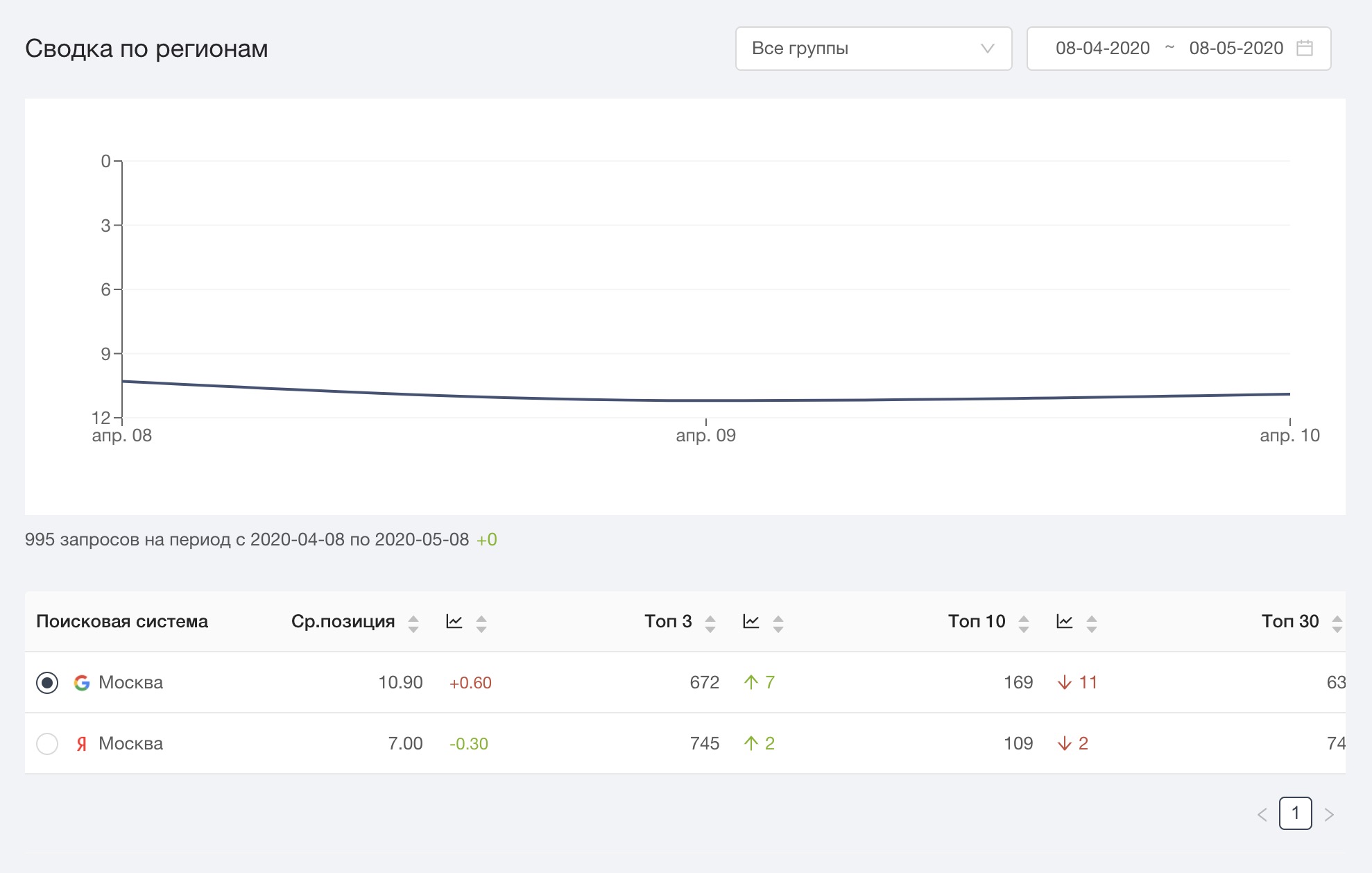 Сводка по регионам в Анализе
Сводка по регионам в Анализе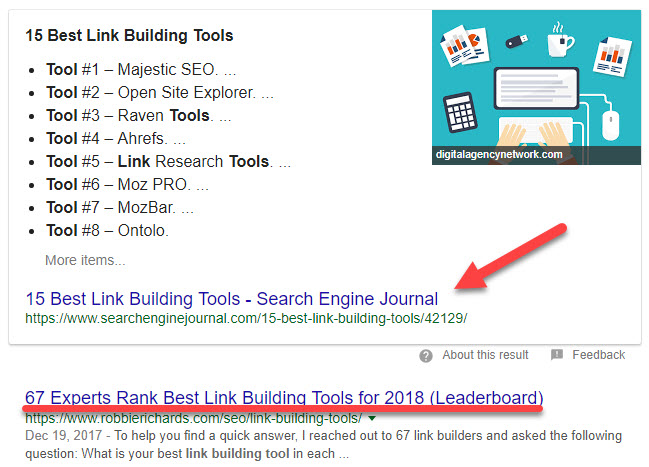 Блок с ответами и ссылка на статью с инструментами
Блок с ответами и ссылка на статью с инструментами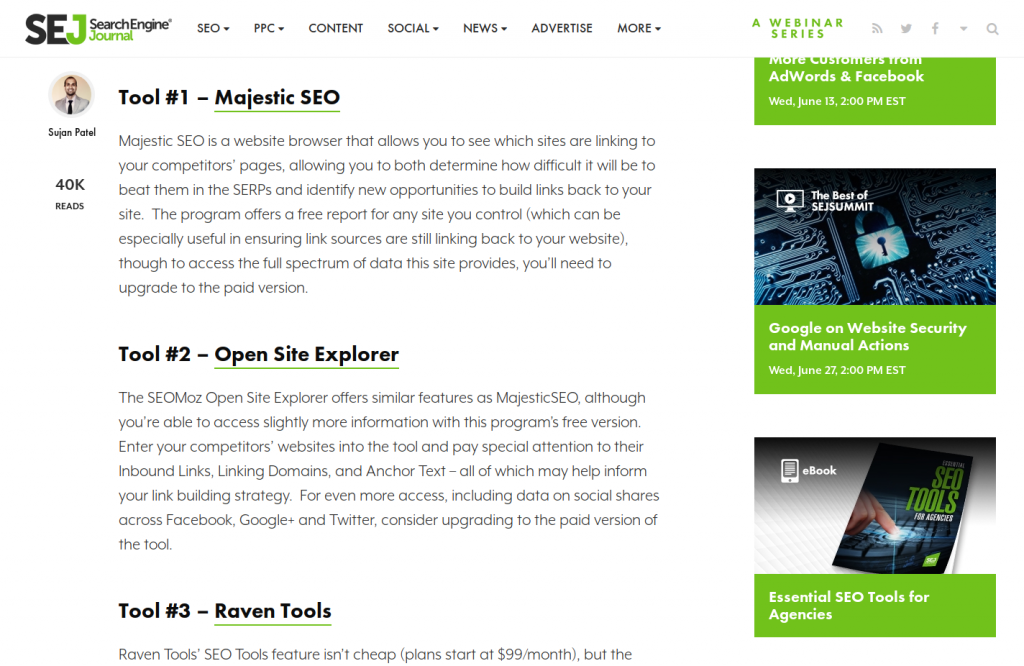 Статья из блока с ответами
Статья из блока с ответами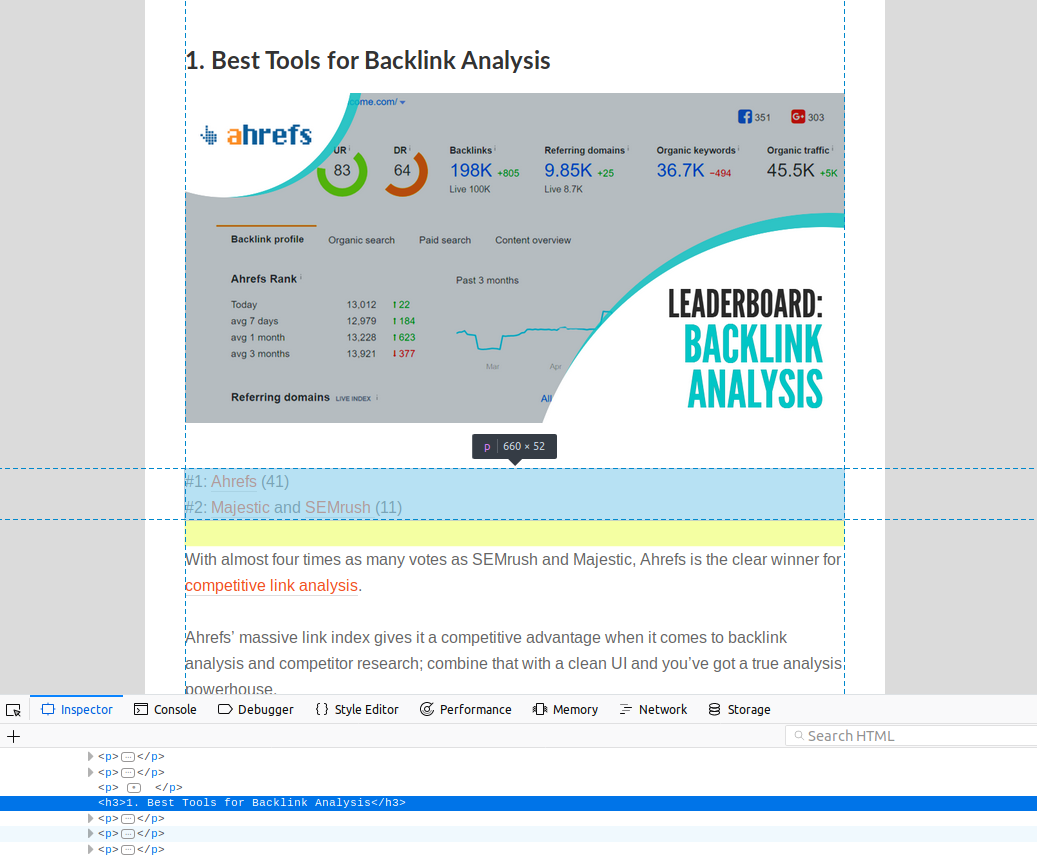 Углубленная статья с инструментами, не попавшая в блок
Углубленная статья с инструментами, не попавшая в блок Материал со списками
Материал со списками Пример списка инструментов
Пример списка инструментов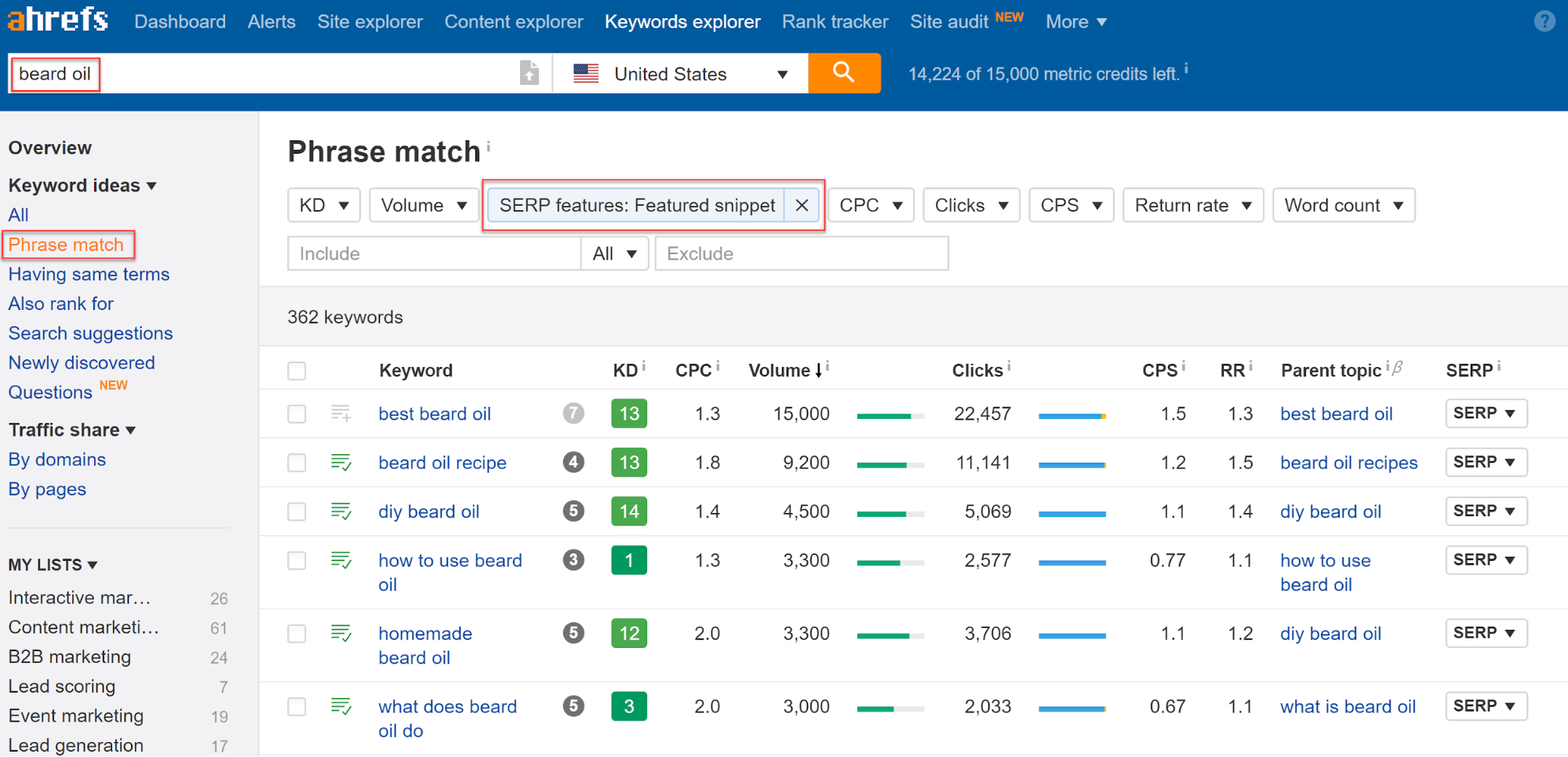 Пример поиска по ключу
Пример поиска по ключу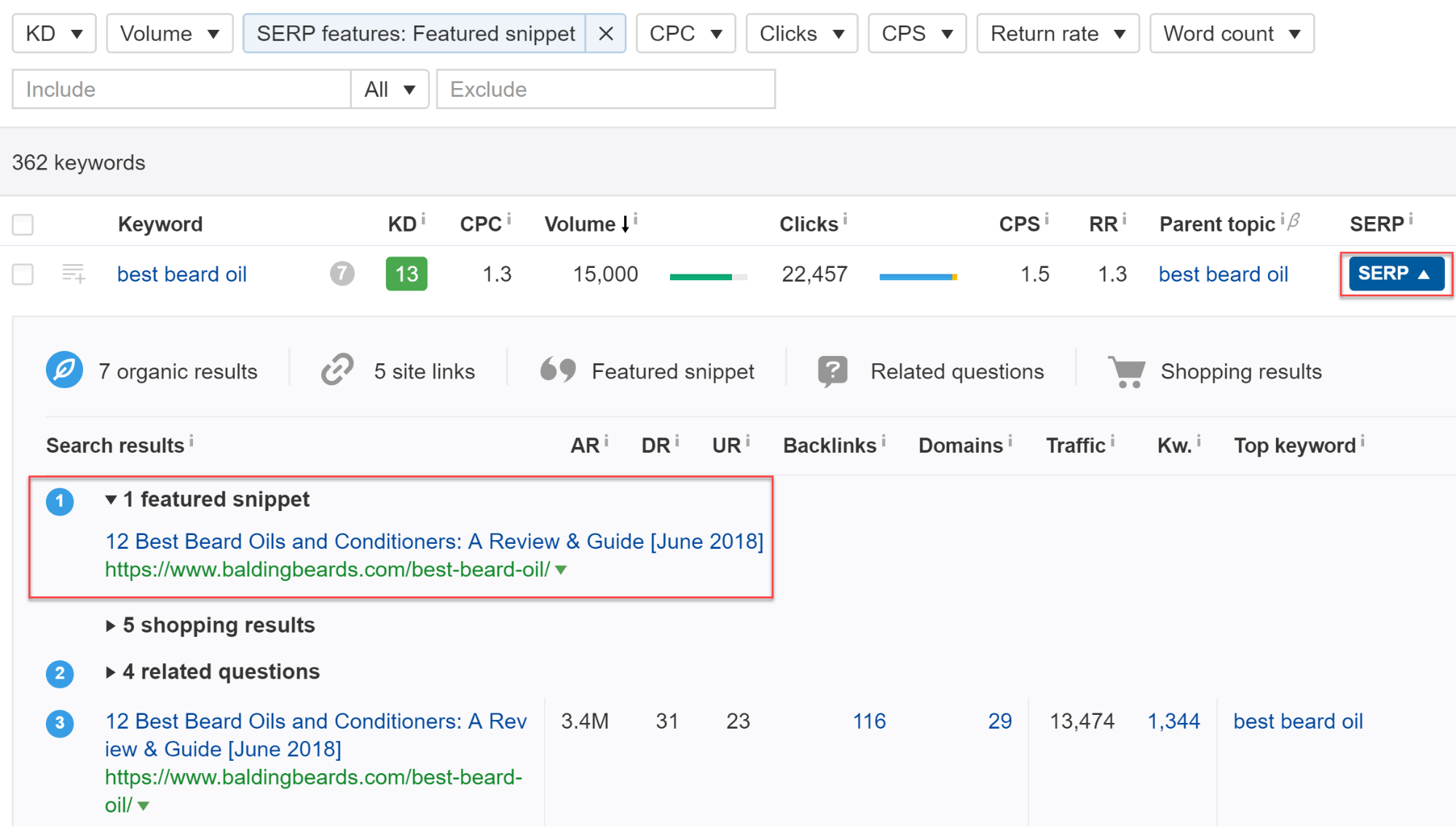 Данные из раздела SERP
Данные из раздела SERP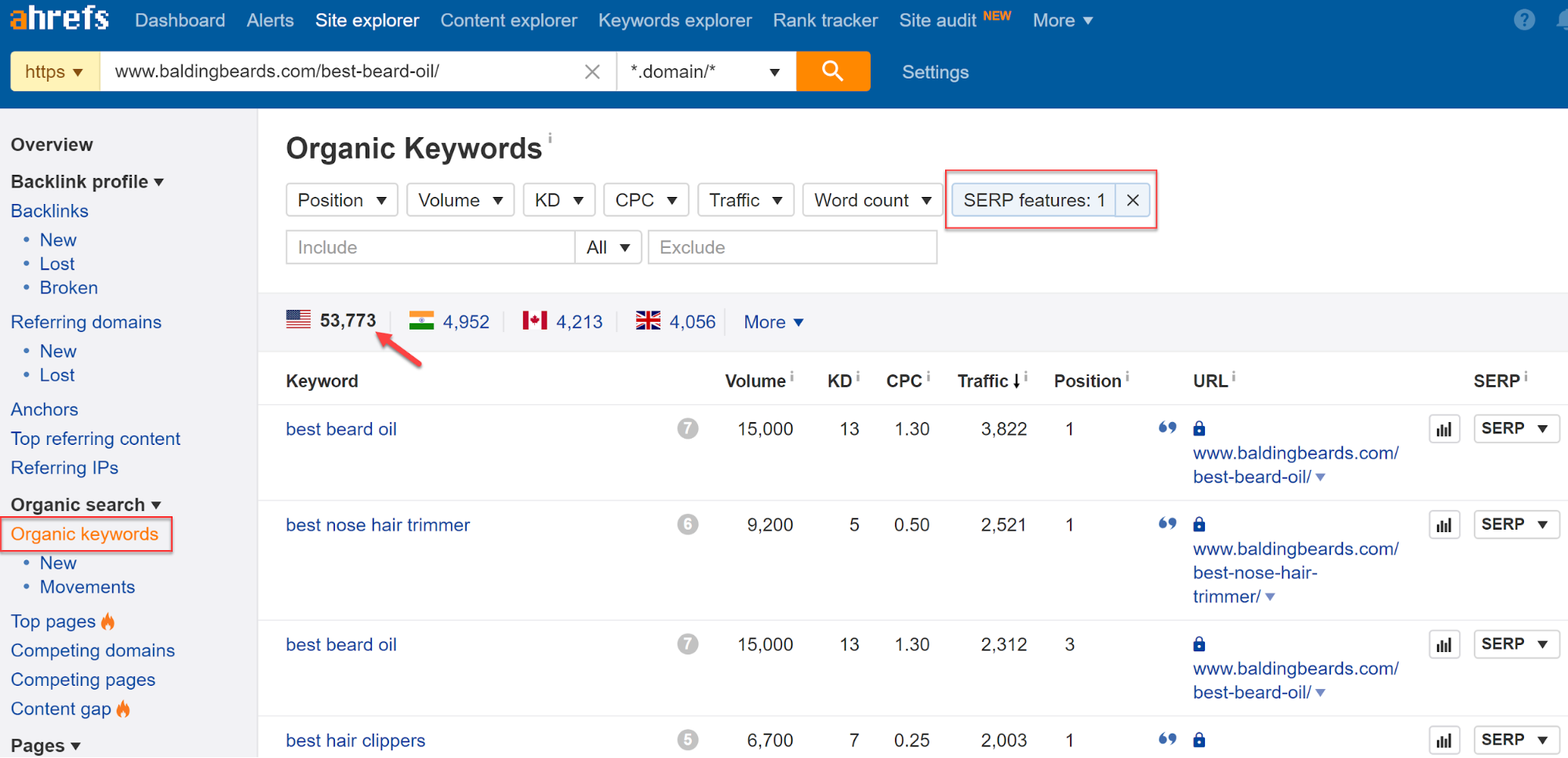 Результаты из раздела Featured Snippets
Результаты из раздела Featured Snippets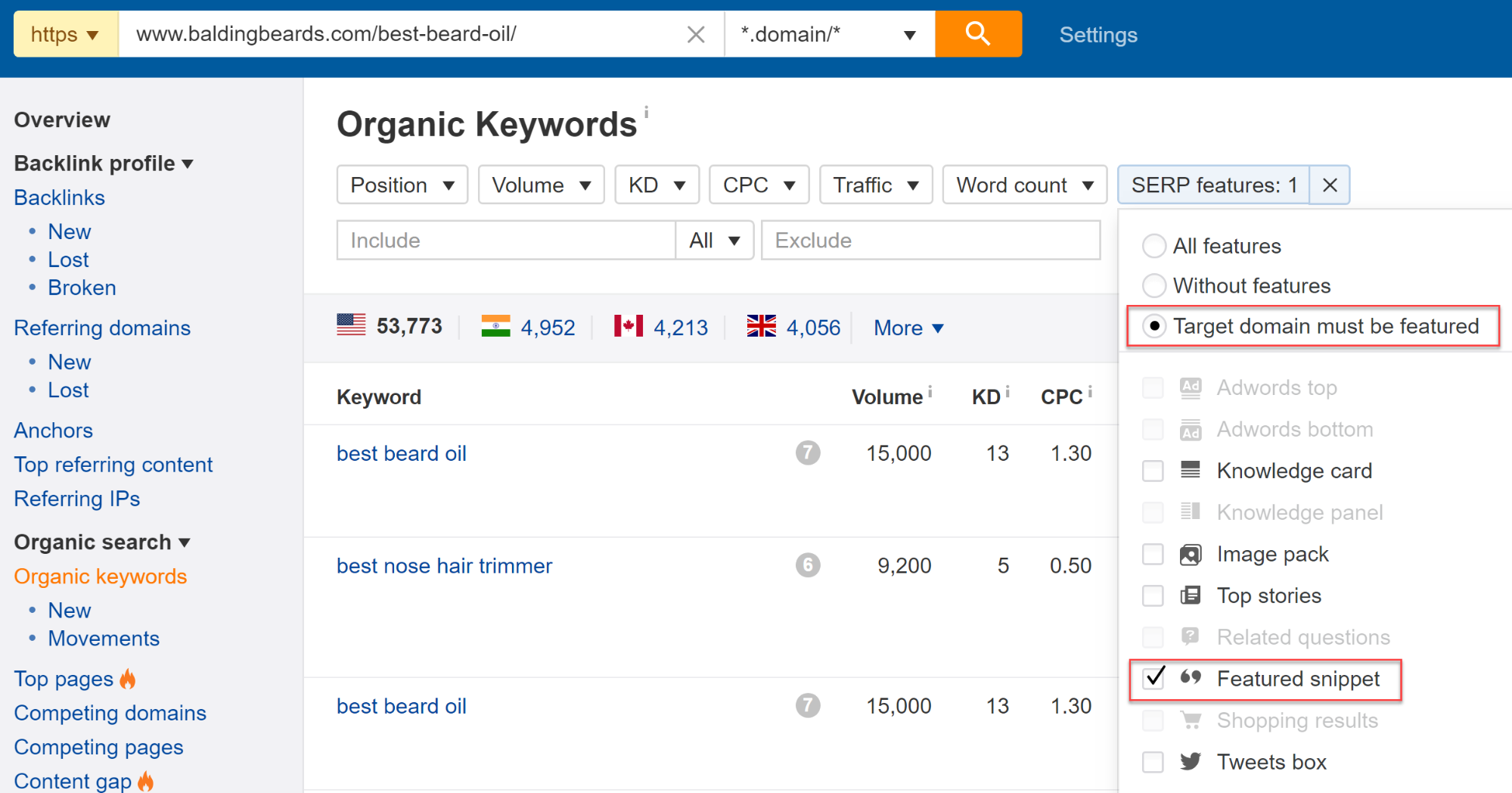 Указываем целевой домен
Указываем целевой домен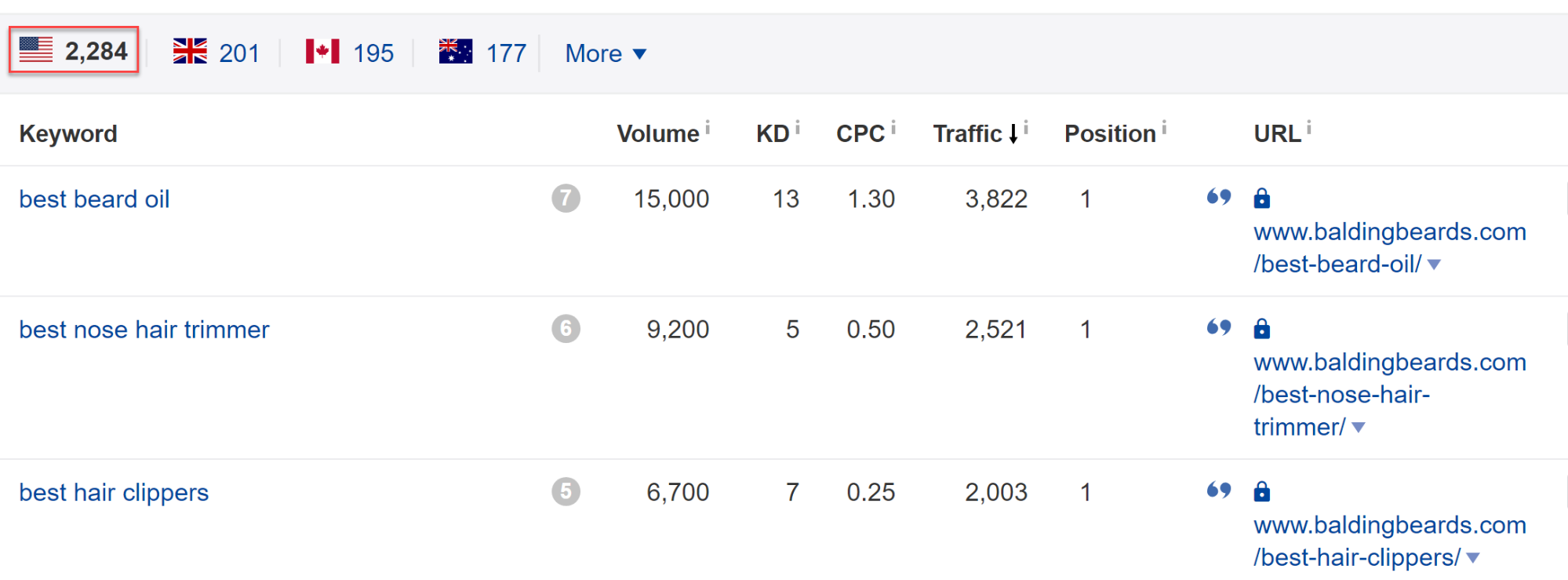 Результаты по домену
Результаты по домену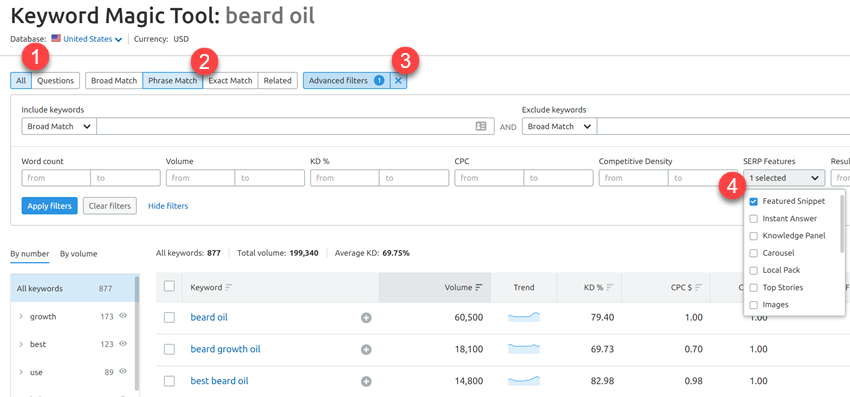 Функции SERP
Функции SERP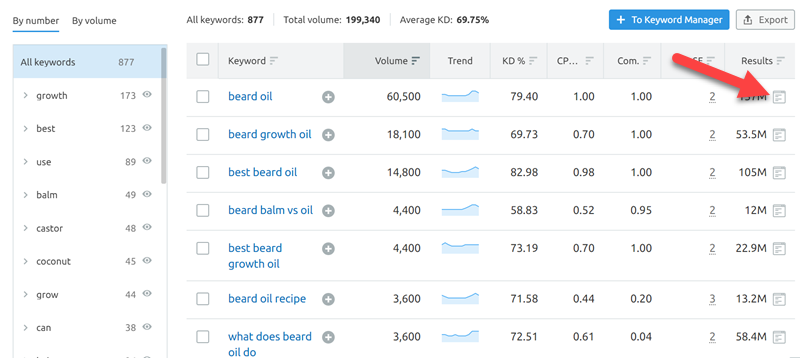 Сайт с расширенным сниппетом
Сайт с расширенным сниппетом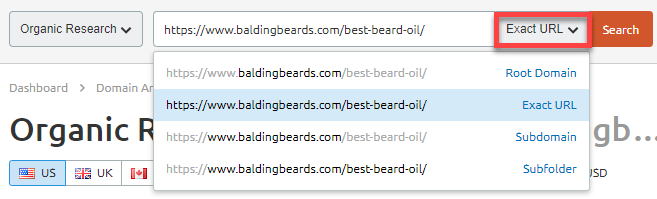 Анализ конкурента из расширенного сниппета
Анализ конкурента из расширенного сниппета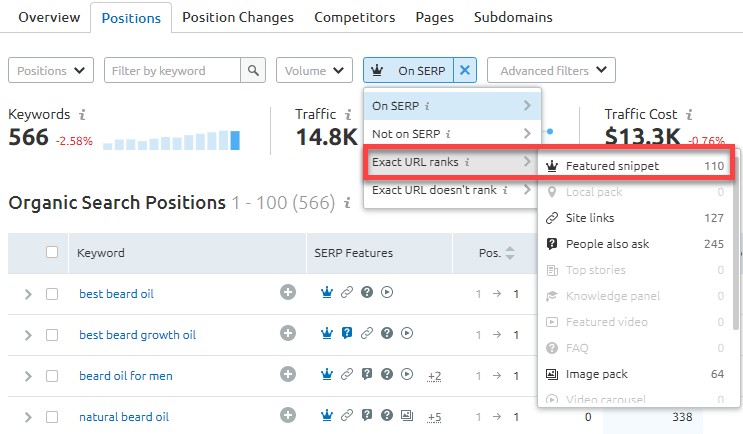 Фильтр по расширенным сниппетам
Фильтр по расширенным сниппетам Пример блока с ответами сайта baldingbeards.com
Пример блока с ответами сайта baldingbeards.com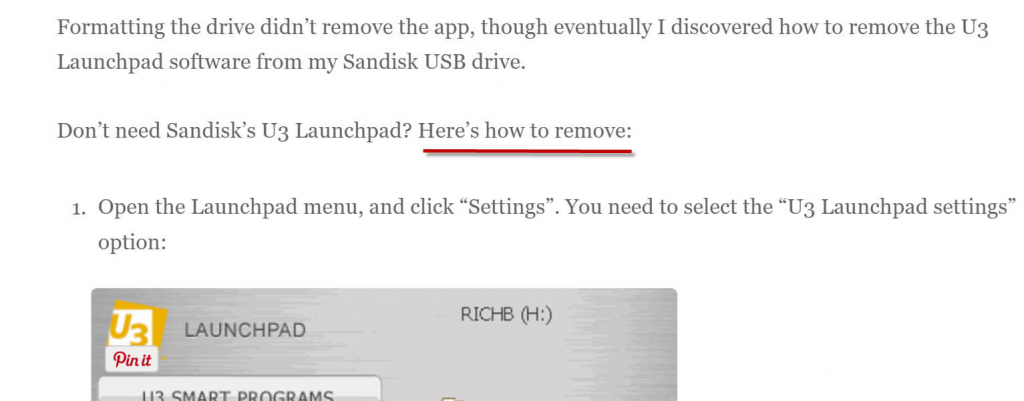 Текст около списка в материале
Текст около списка в материале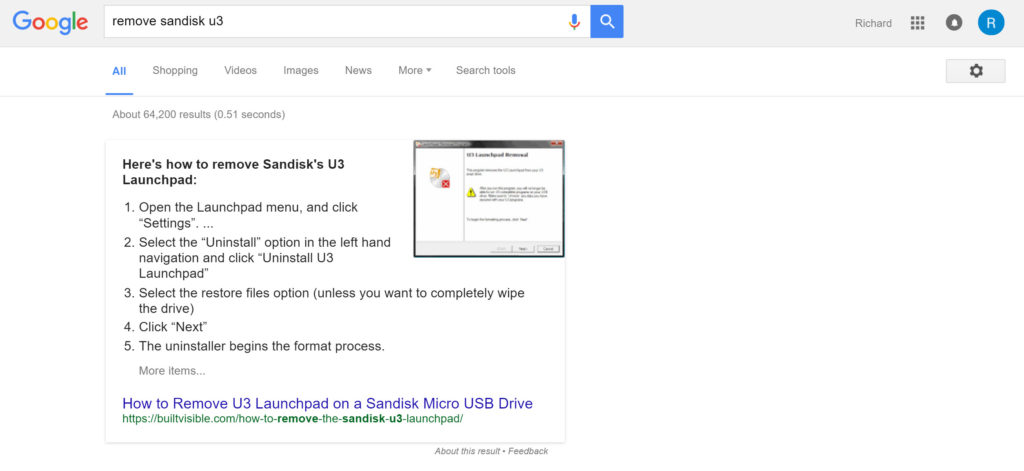 Блок с ответами со ссылкой на материал
Блок с ответами со ссылкой на материал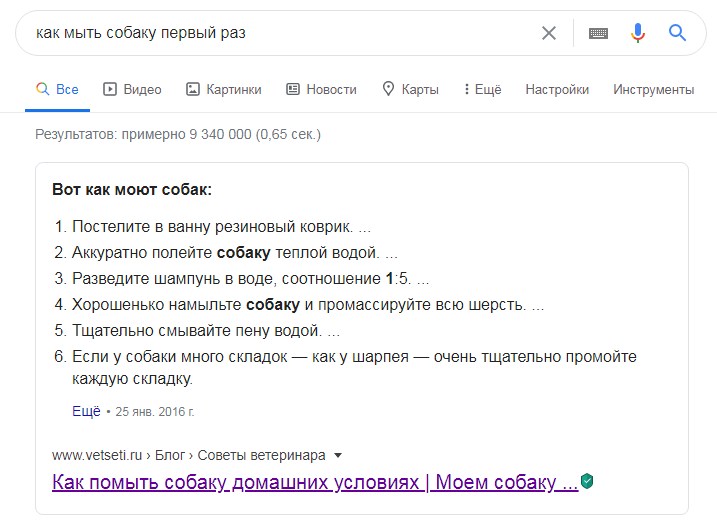 Сниппет на запрос «как помыть собаку»
Сниппет на запрос «как помыть собаку»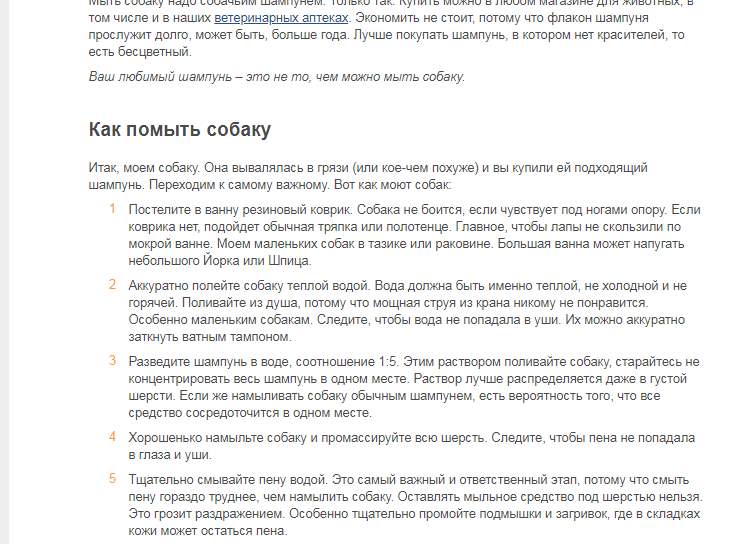 Список в тексте
Список в тексте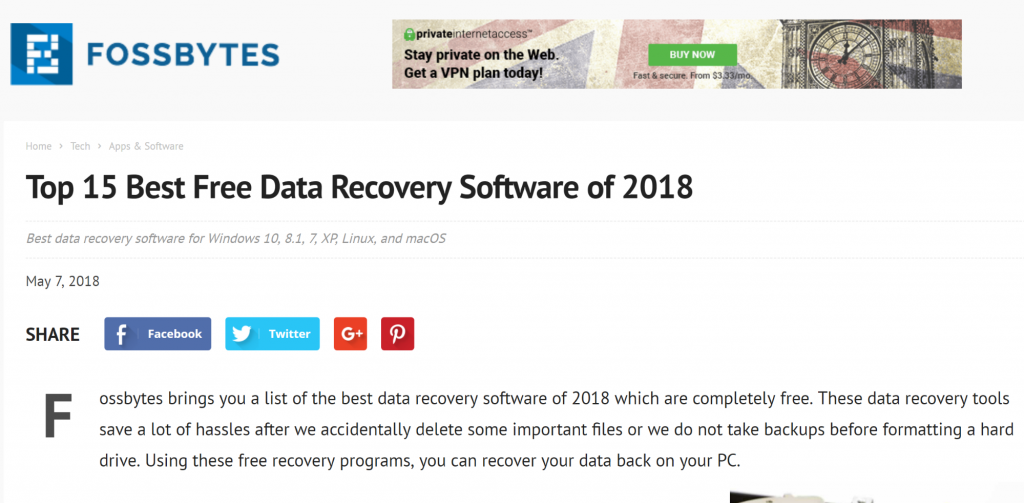 Статья на сайте
Статья на сайте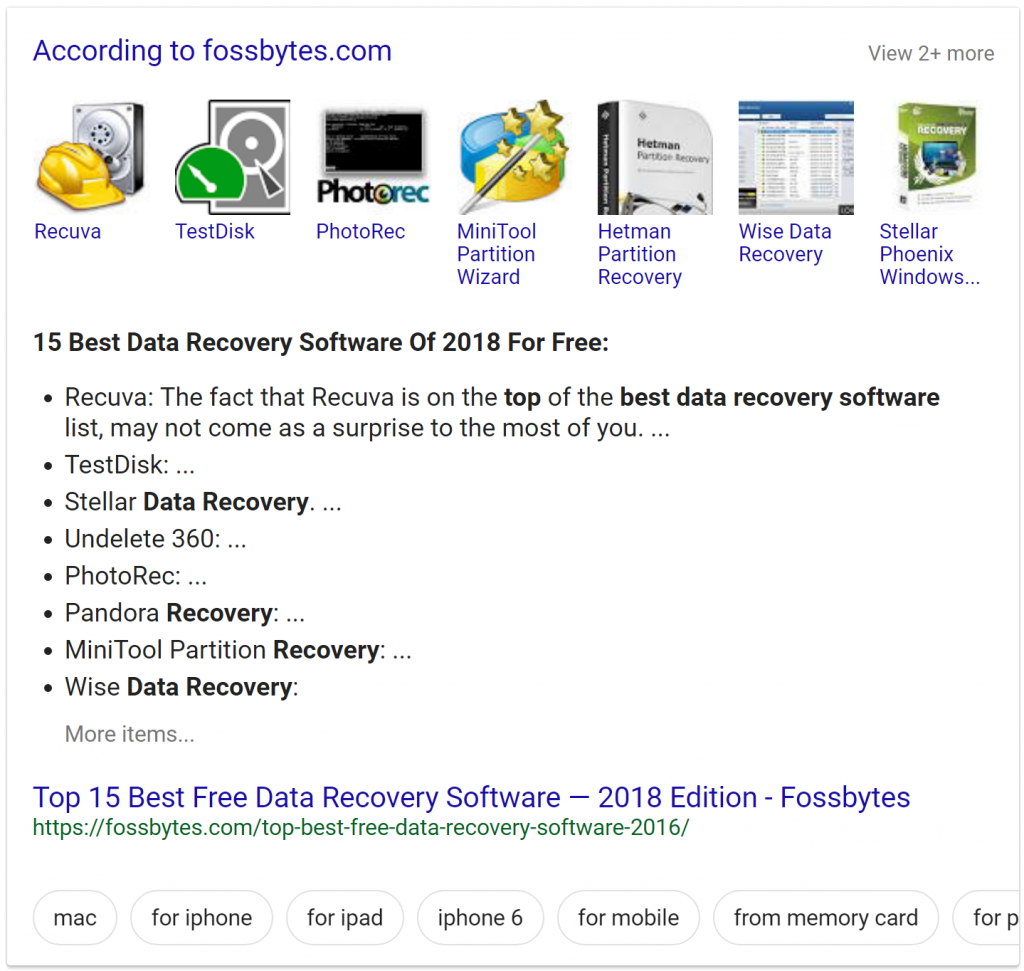 Расширенный сниппет со списком
Расширенный сниппет со списком Сниппет со ссылкой на Википедию
Сниппет со ссылкой на Википедию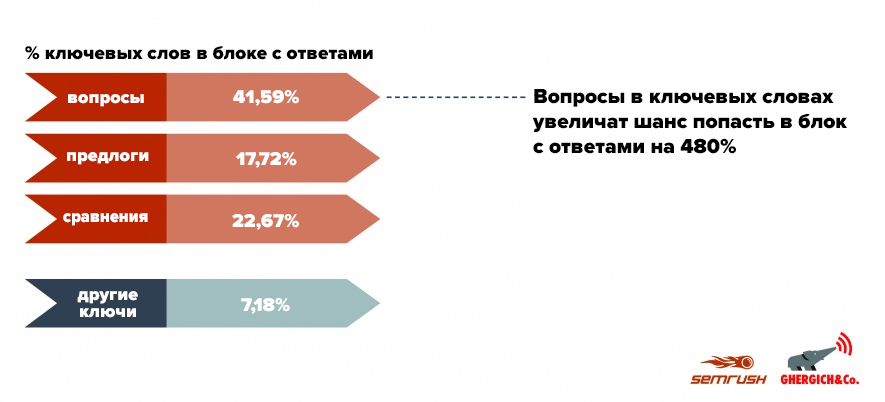 Составляющие блоков с ответами
Составляющие блоков с ответами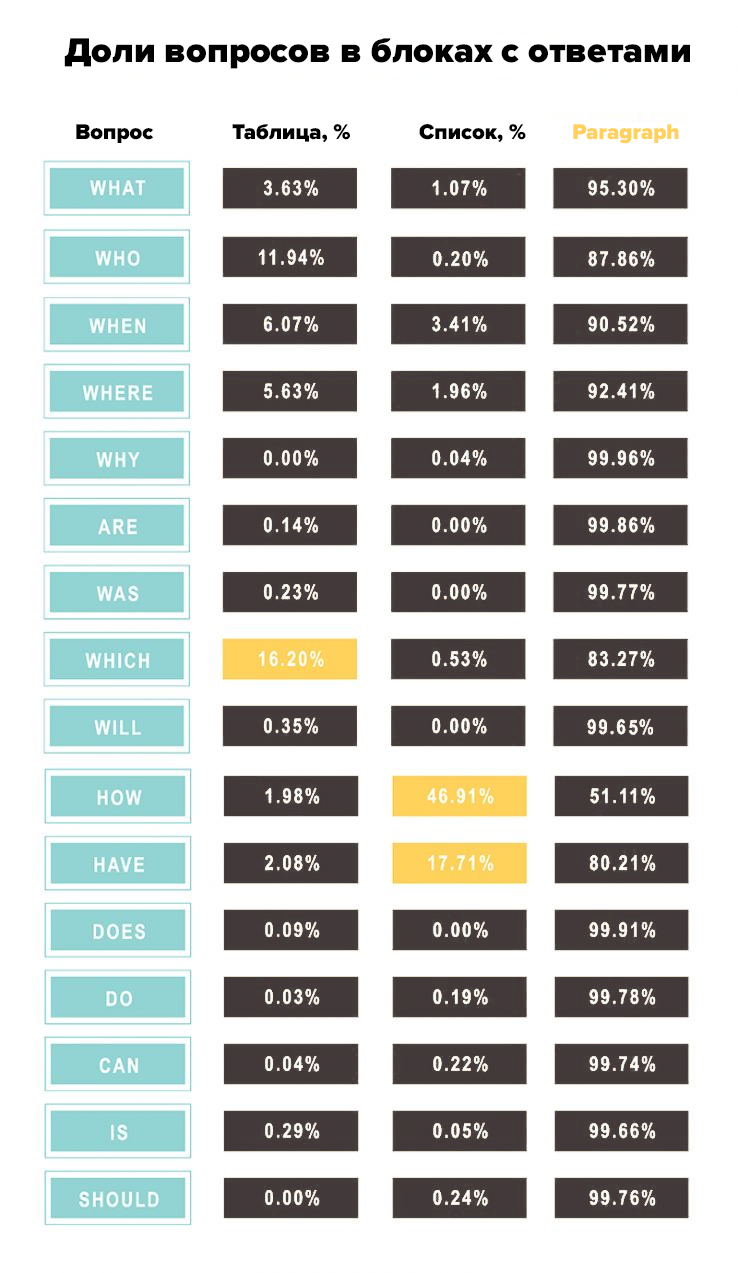 Доли вопросов в расширенных сниппетах
Доли вопросов в расширенных сниппетах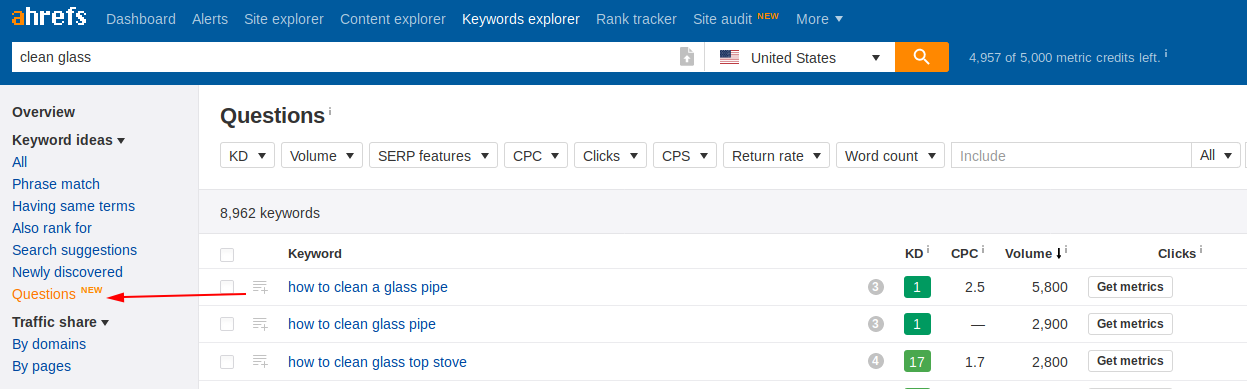 Панель сервиса
Панель сервиса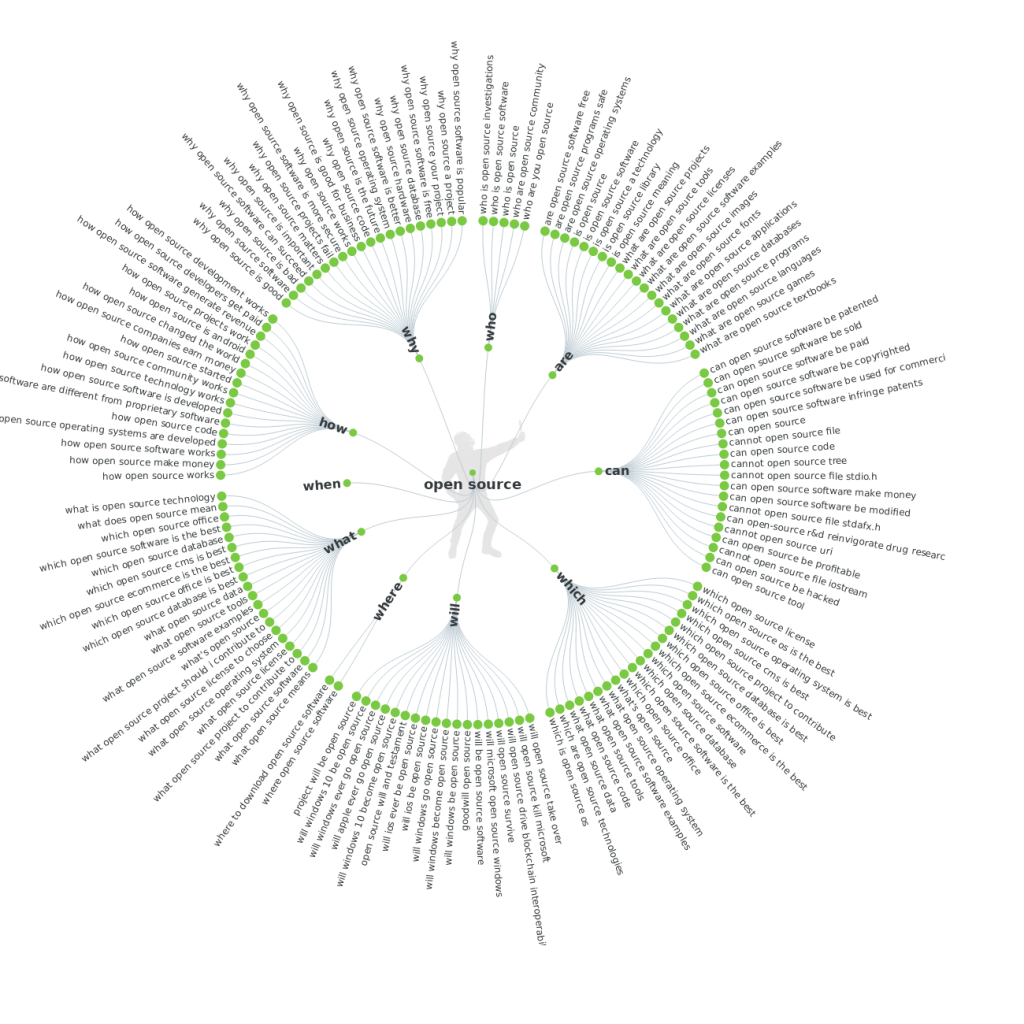 Визуальная карта ключевых слов по запросу «open source»
Визуальная карта ключевых слов по запросу «open source»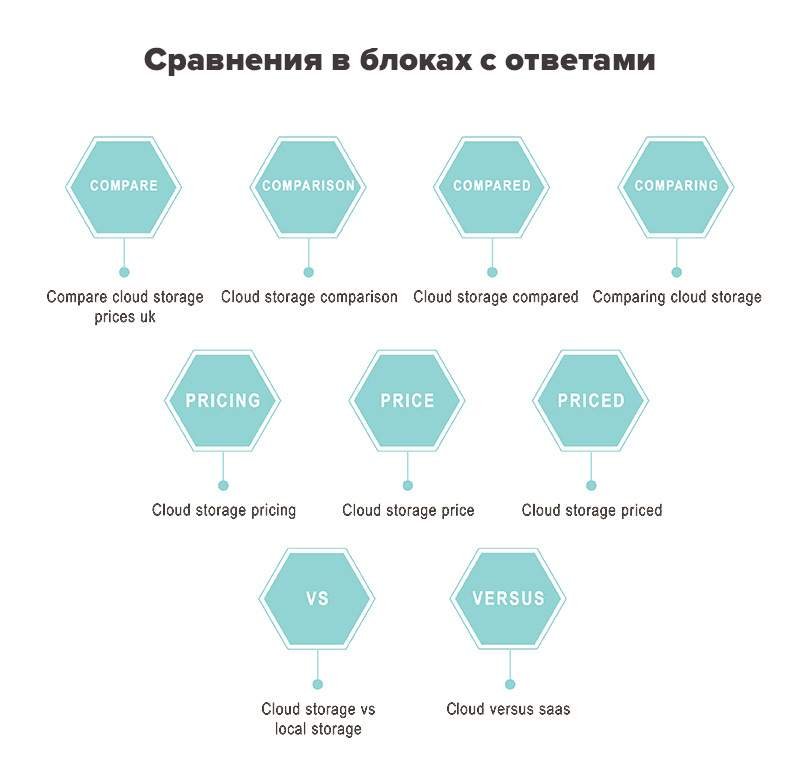 Примеры использования слов для сравнения
Примеры использования слов для сравнения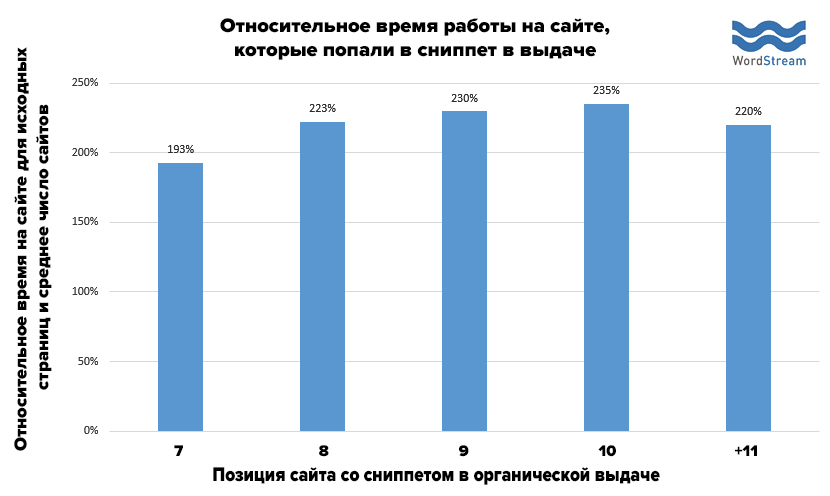 Зависимость времени посещения сайта
Зависимость времени посещения сайта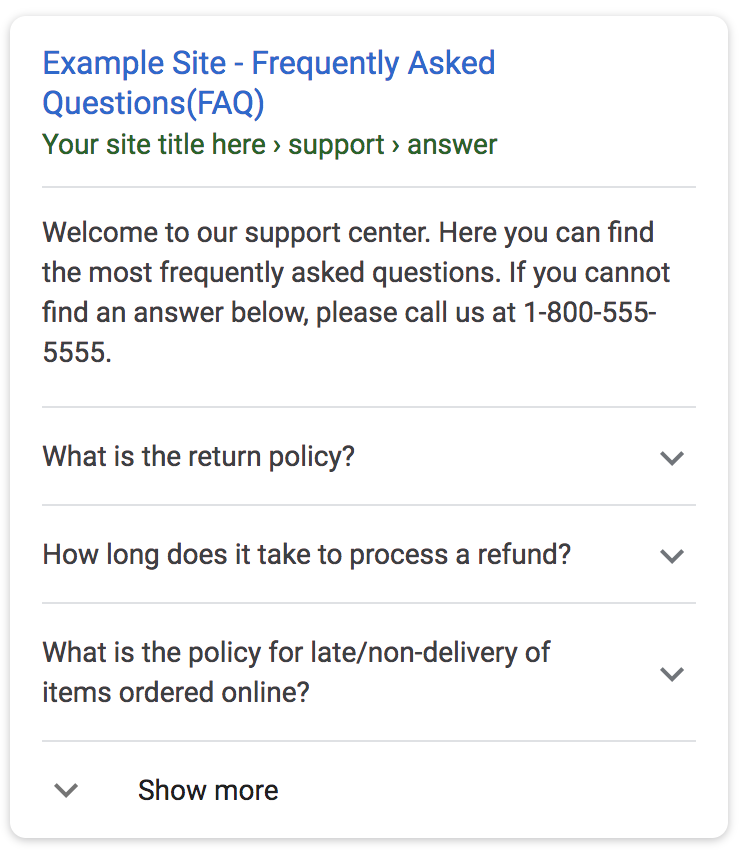 Пример размеченного FAQ
Пример размеченного FAQ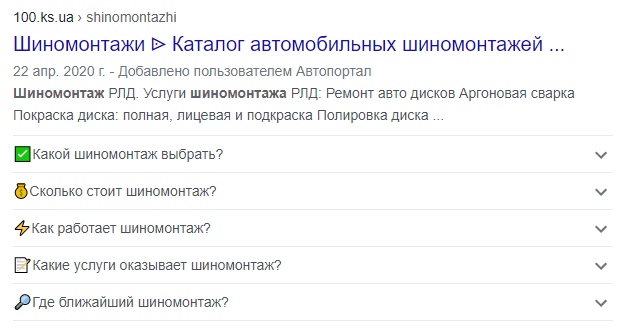 Сниппет с вопросами и ответами в выдаче
Сниппет с вопросами и ответами в выдаче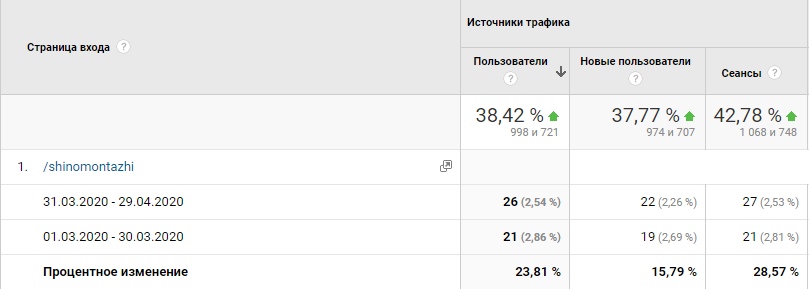 CTR сниппета вырос
CTR сниппета вырос Разметка под пошаговые действия
Разметка под пошаговые действия Пример разметки QA
Пример разметки QA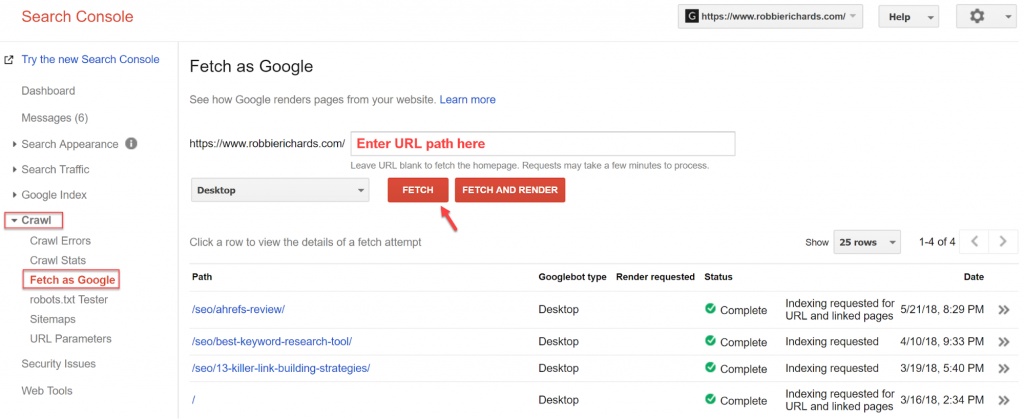 Search Console
Search Console
 Наличие seo-текста на сайте
Наличие seo-текста на сайте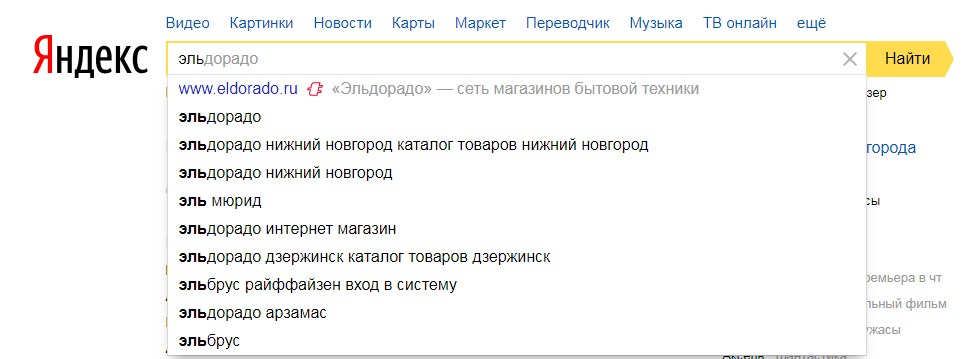 Ввод в Яндексе
Ввод в Яндексе Наличие seo-текста на сайте
Наличие seo-текста на сайте Деление каталога смартфонов на множество разделов
Деление каталога смартфонов на множество разделов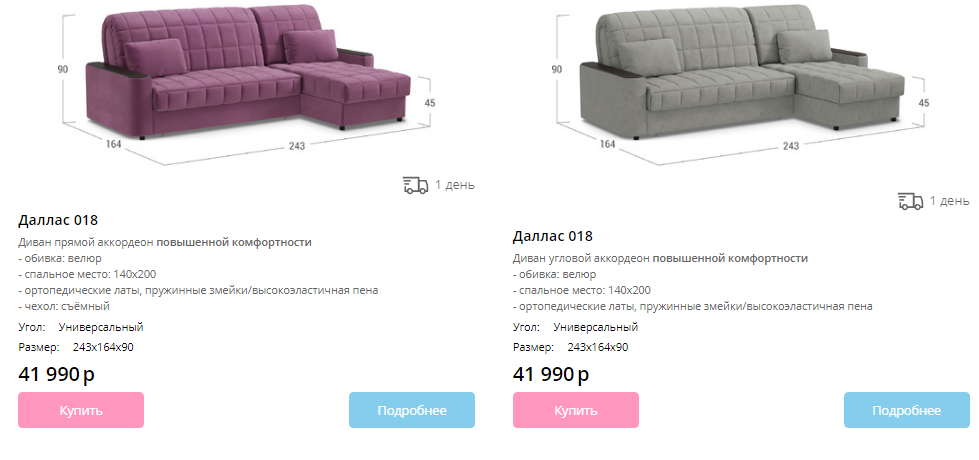 Деление одинаковых товаров по цвету
Деление одинаковых товаров по цвету Текст над каталогом
Текст над каталогом Текст под каталогом
Текст под каталогом Часть текста скрыта под «читать полностью»
Часть текста скрыта под «читать полностью» Карточка товара с отдельными вкладками
Карточка товара с отдельными вкладками Разные URL для вкладок
Разные URL для вкладок Региональный субдомен
Региональный субдомен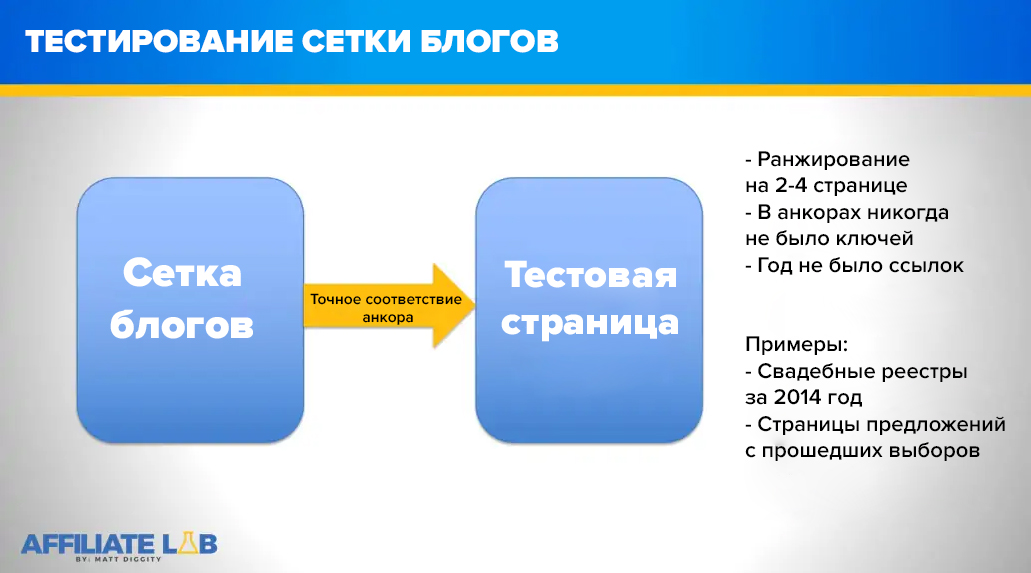
 Схема от affiliatelab.im
Схема от affiliatelab.im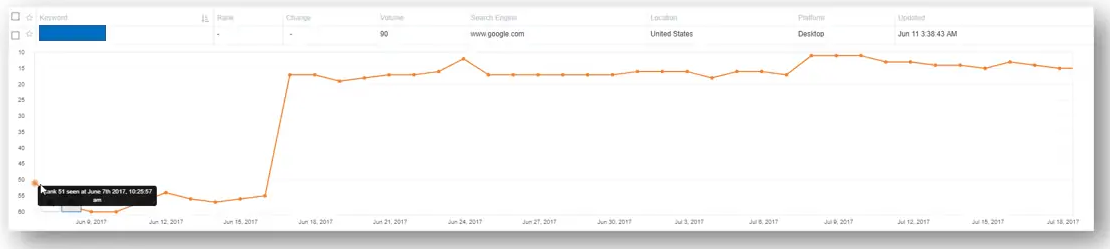 График положительных результатов
График положительных результатов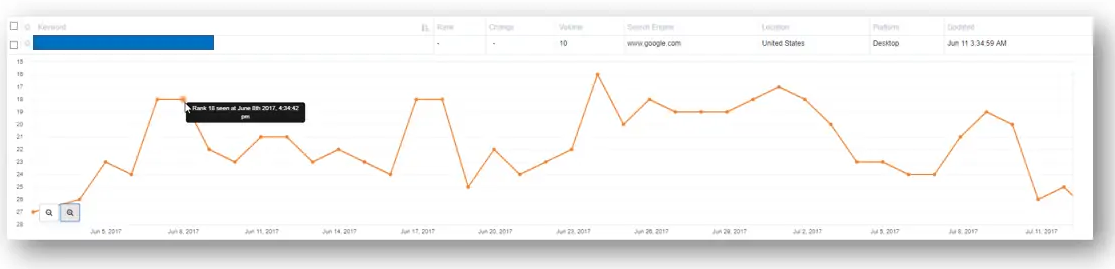 График нейтральных результатов
График нейтральных результатов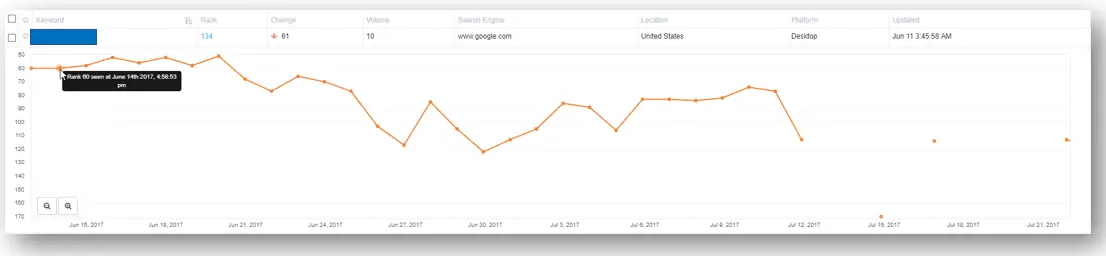 График негативных результатов
График негативных результатов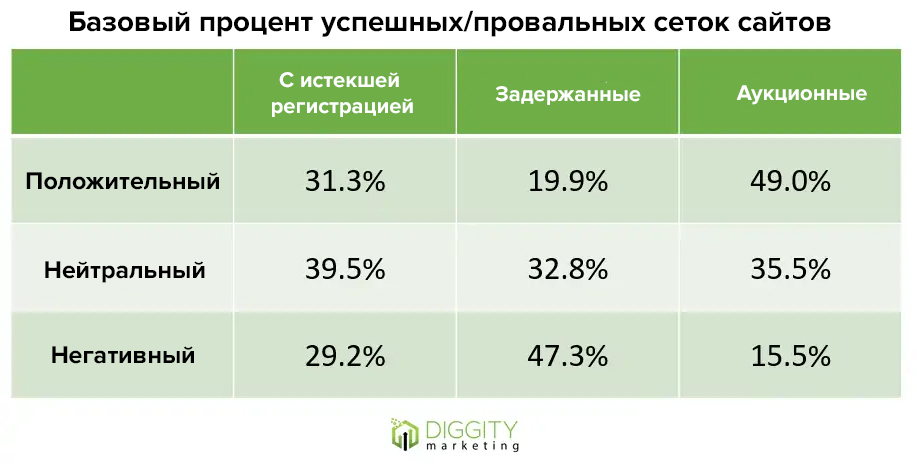 Влияние по видам доменов
Влияние по видам доменов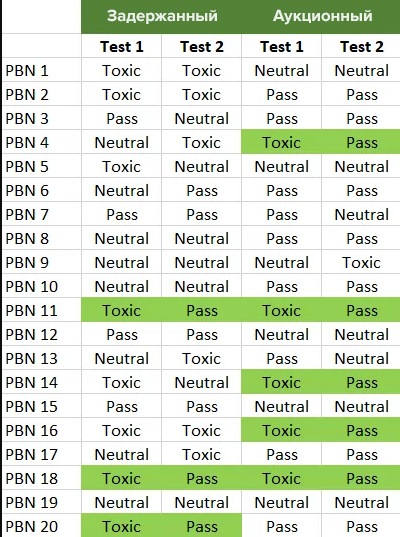 Таблица влияния
Таблица влияния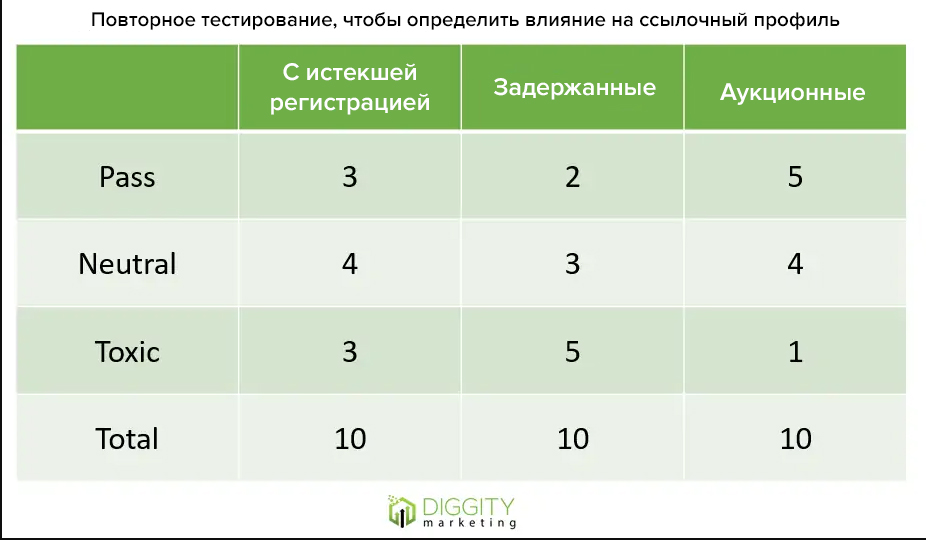 Итоги теста
Итоги теста Сайт с монетизацией
Сайт с монетизацией Диаграмма результатов
Диаграмма результатов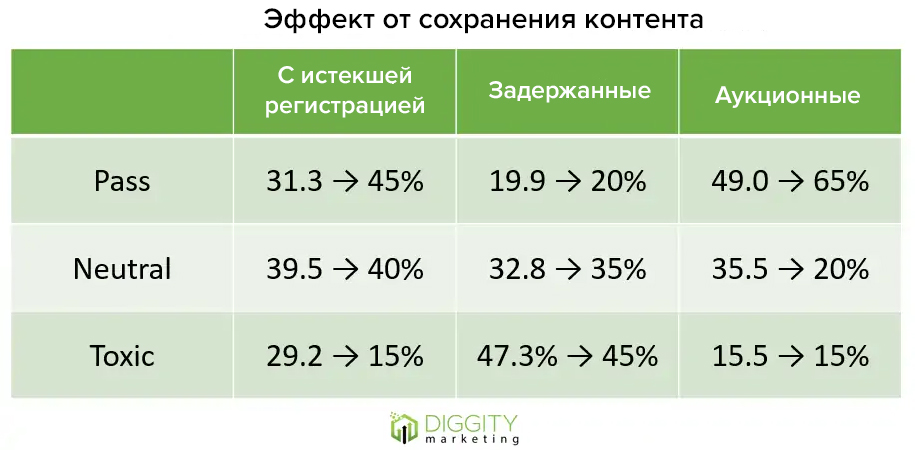 Результаты теста
Результаты теста Итоги тестов
Итоги тестов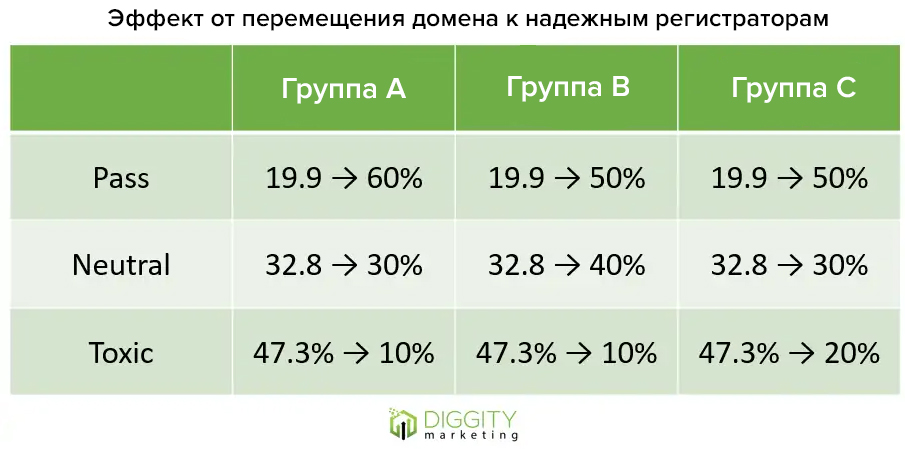
 Результаты теста
Результаты теста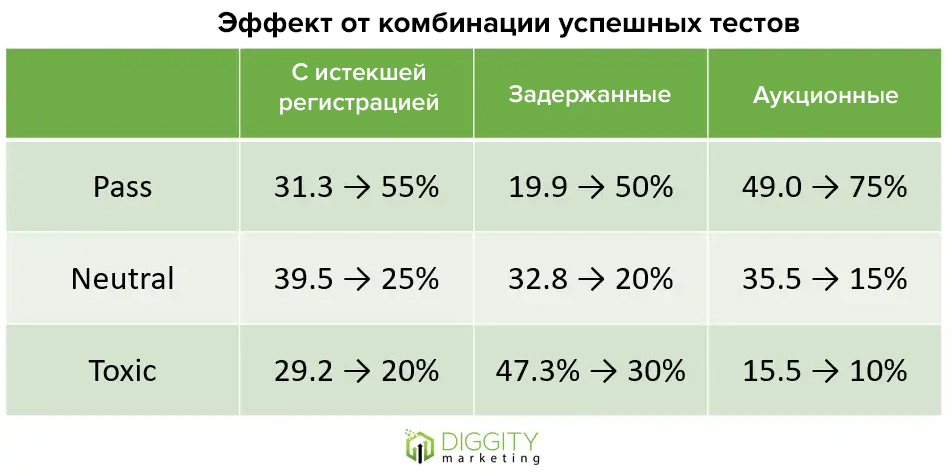 Результаты итогового теста
Результаты итогового теста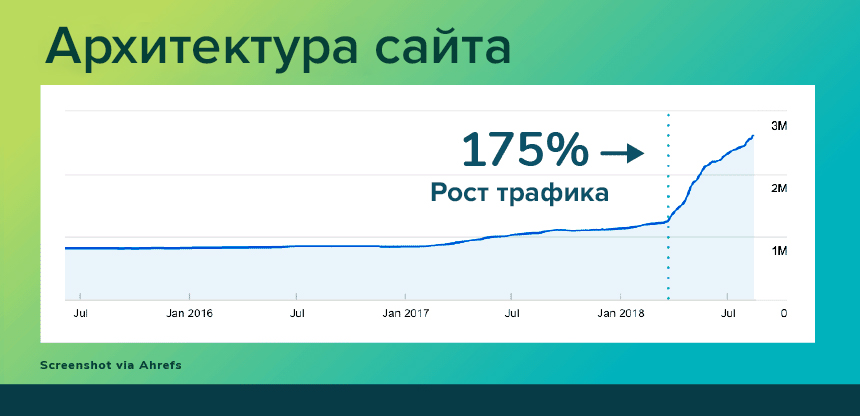
 Рост трафика после доработки архитектуры
Рост трафика после доработки архитектуры
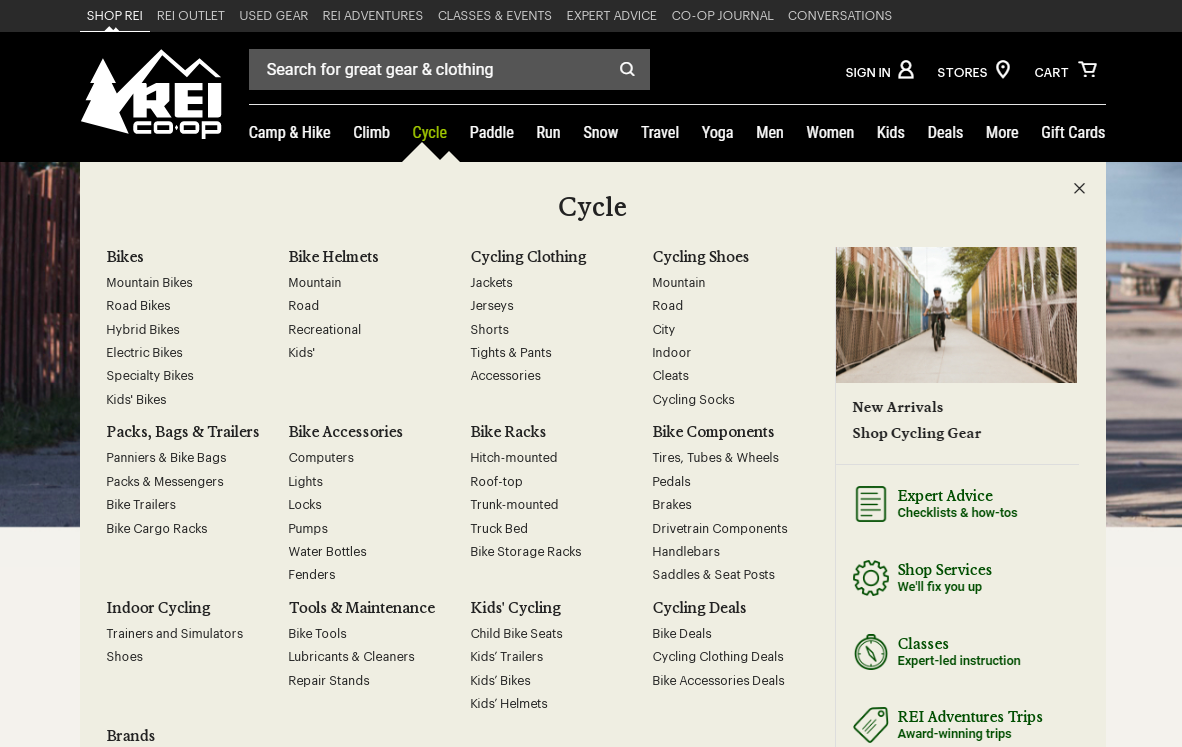 Пример хорошо построенной структуры для большого сайта rei.com
Пример хорошо построенной структуры для большого сайта rei.com
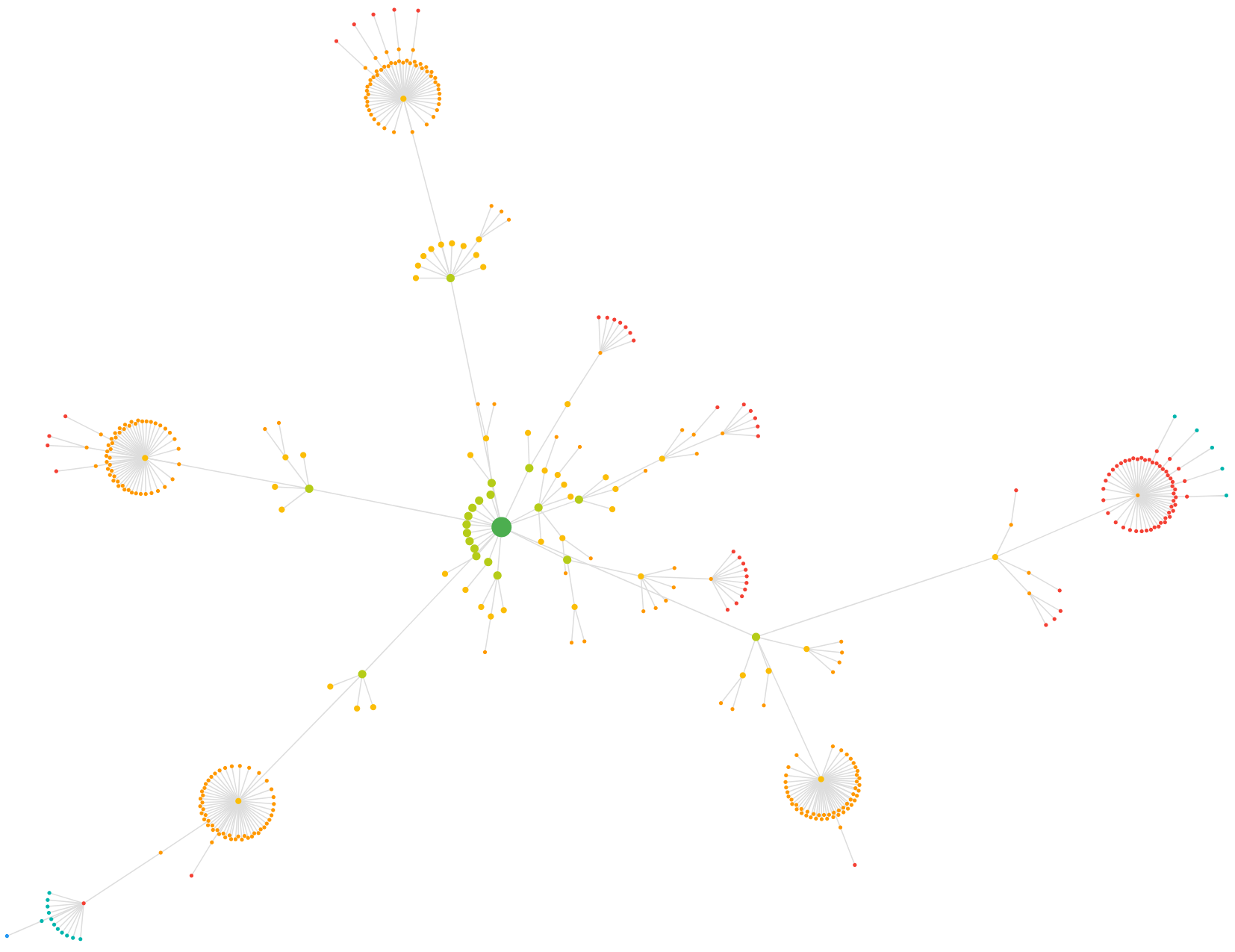 Визуализация структуры сайта от Sitebulb
Визуализация структуры сайта от Sitebulb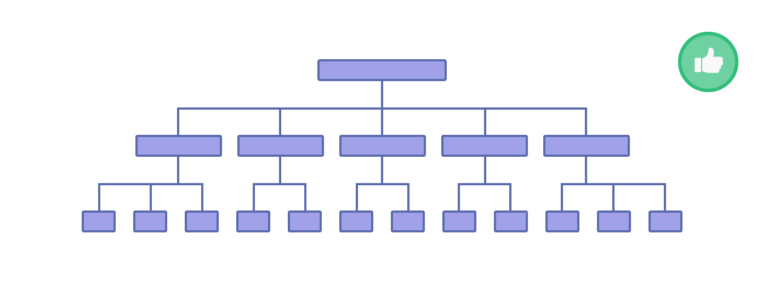 Плоская структура сайта. Источник backlinko.com
Плоская структура сайта. Источник backlinko.com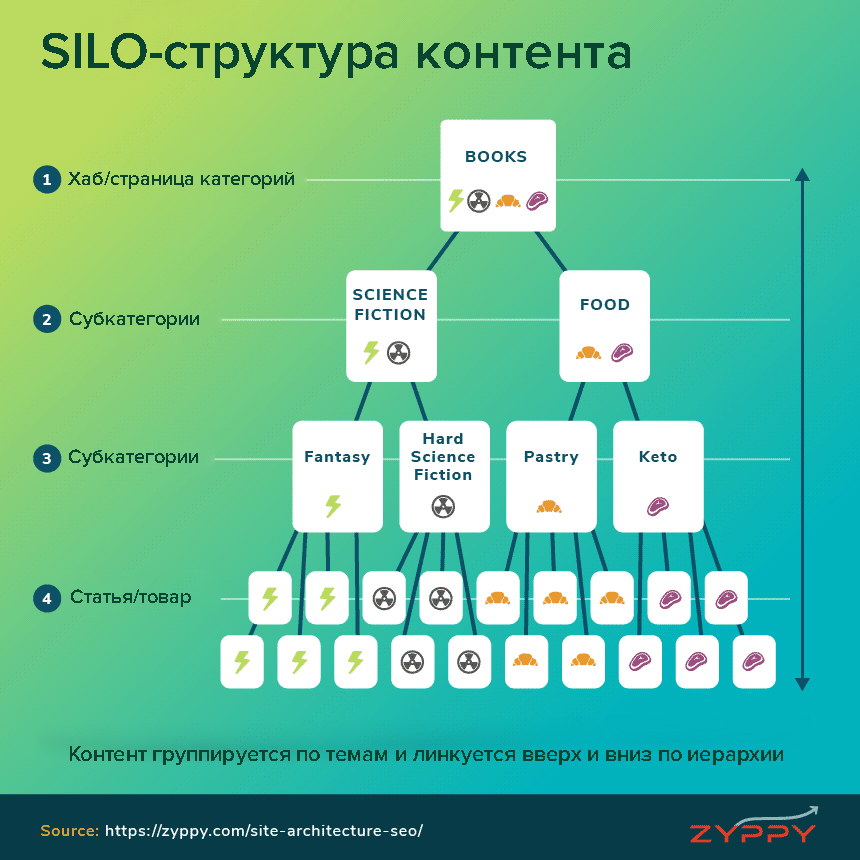 Схема SILO
Схема SILO
 Страница вне структуры. Источник backlinko.com
Страница вне структуры. Источник backlinko.com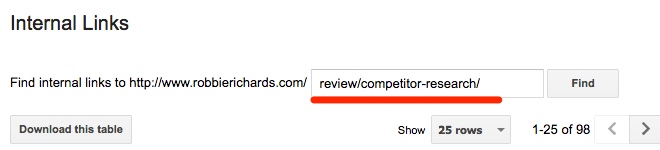 Проверка по консоли
Проверка по консоли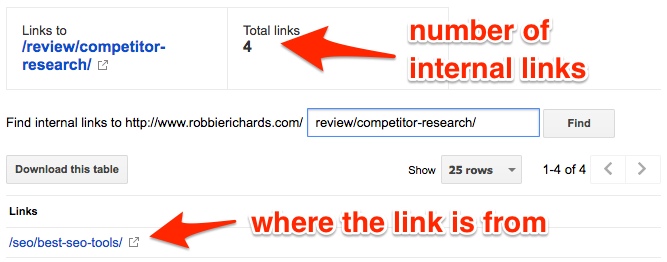 Ссылки на страницу
Ссылки на страницу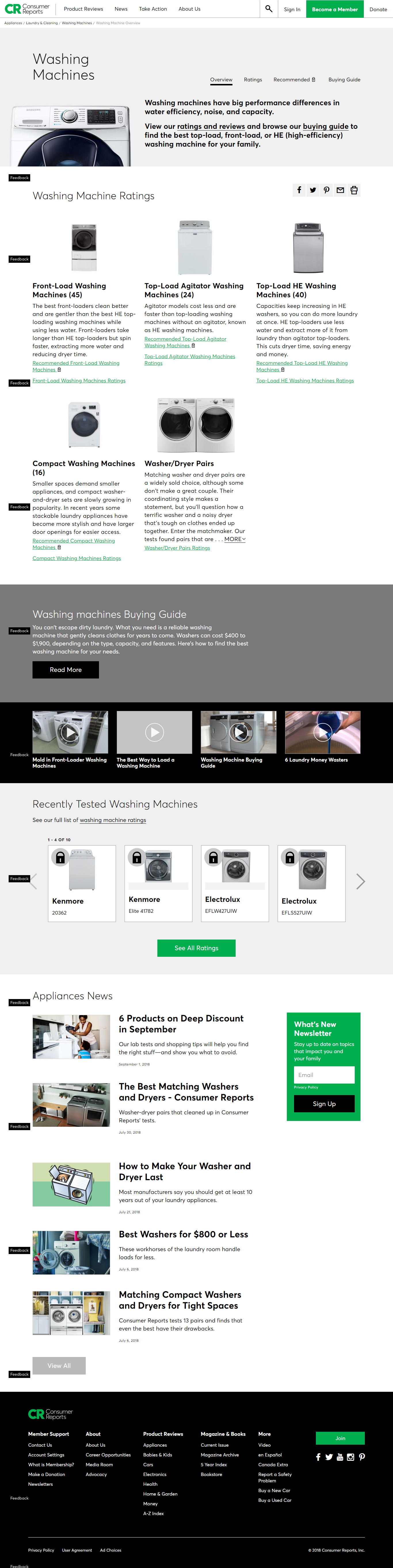 Страница-хаб
Страница-хаб  Структура URL страницы
Структура URL страницы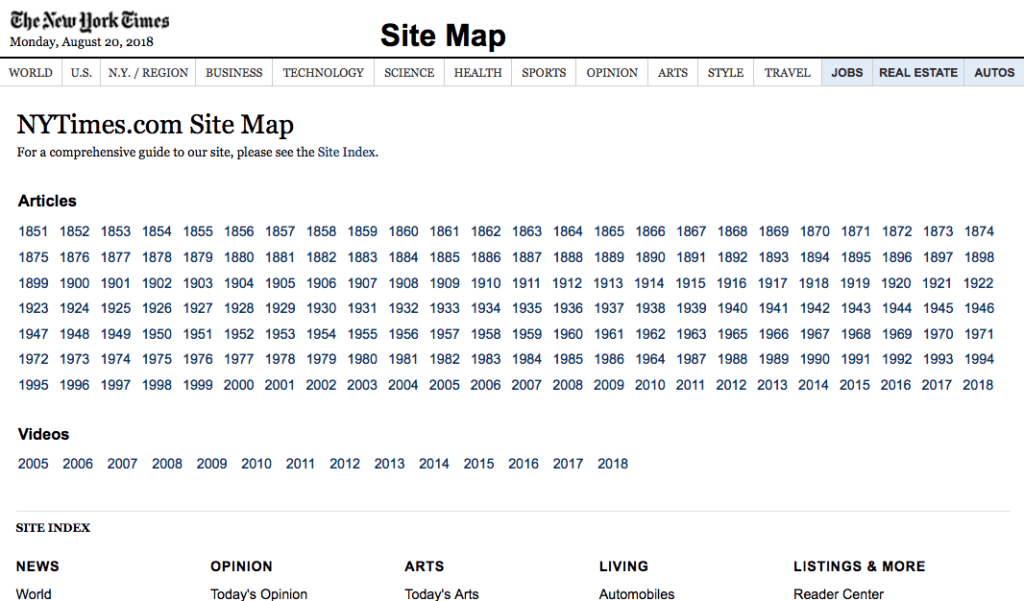 HTML-карта New York Times
HTML-карта New York Times 