При работе с сайтом веб-мастеры ориентируются на данные статистики по трафику, ссылкам, конверсиям и другим параметрам. Если полагаться на неверные данные из Google Analytics, есть риск принять решения, которые навредят сайту.
К примеру, у падения трафика в аккаунте системы Google Analytics может быть много причин. Возможно, ваши SEO-работы не приносят ожидаемого результата: что делать в этом случае, разбирали в посте «SEO не работает: что делать, когда все сделано, а результатов нет».
Но может быть, что веб-мастер все делает правильно, с сайтом порядок, а Google Analytics ошибается и искажает картину. Этот материал поможет разобраться, как минимизировать факторы перекоса данных и не допускать ошибок в настройке. В статье не разбирали очевидные ошибки, к примеру, некорректное время или несовпадение ID ресурса в коде и настройках GA. Часть ошибок мы подсмотрели в статье Ahrefs «13 Google Analytics Tracking Mistakes (and How to Fix Them)».
Итак, в чем можно ошибиться при настройке Google Analytics?
Неправильно настроить события взаимодействия
Отказы на сайте — это нормально, пользователи уходят с сайта по разным причинам, не всегда это вина сайта. Если Google Analytics показывает неестественно низкие отказы, скорее всего они есть, но из-за настройки считаются неправильно.
Покупки, отправка форм — это примеры действий пользователей на сайте, они отмечаются как события взаимодействия. Они конверсионные и важны для бизнеса. Обычно если пользователь выполнил какое-то целевое действие на странице, а потом ушел с нее, это не засчитывается в системе статистики как отказ.
Но если настраивать любые события как события взаимодействия, и не засчитывать их как отказы, отказов будет неестественно мало. К примеру, автовоспроизведение видео или клик по поп-апу не стоит относить к событиям взаимодействия.
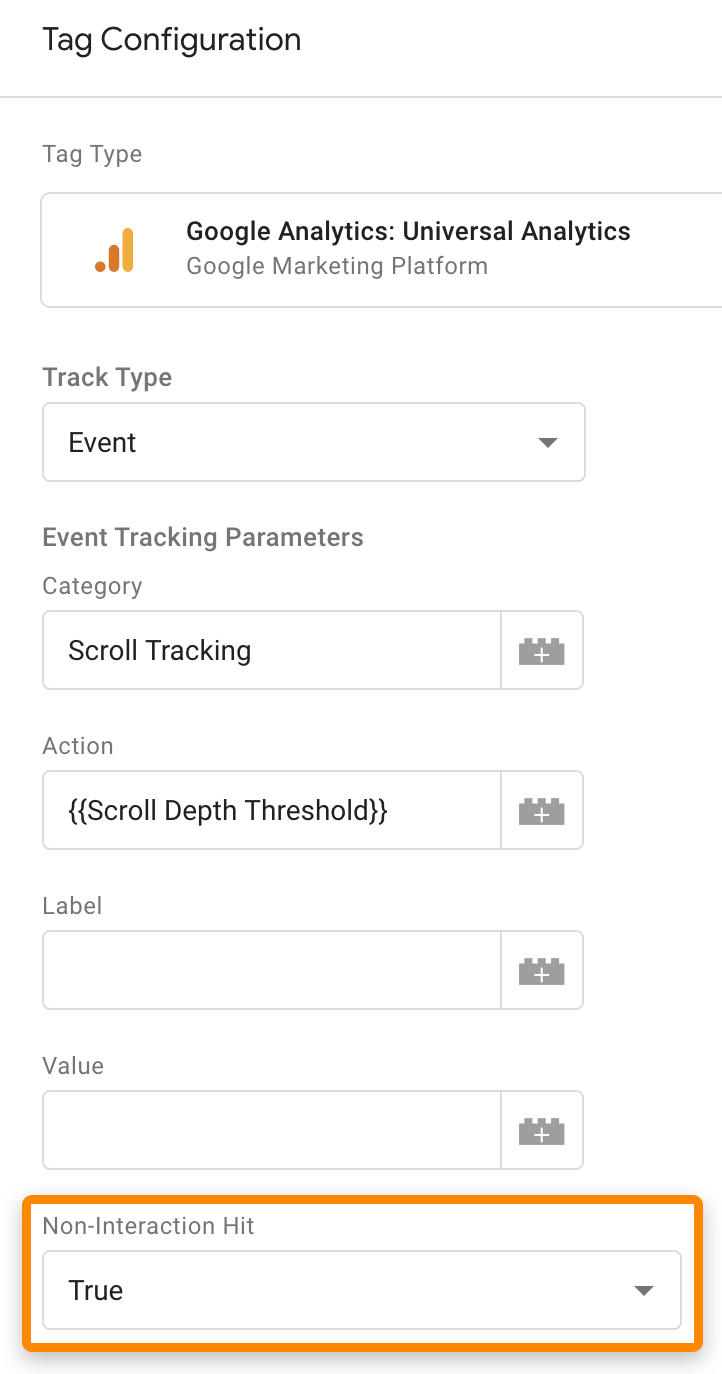
Если отказов подозрительно мало, добавьте еще одну строку кода во фрагмент события GA. Для этого в объекте fieldsObject команды send присвойте полю nonInteraction значение true. Пример для видео:
Если вы используете Google Tag Manager, измените настройку «Событие без взаимодействия» с false на true:
Изменение настройки в Google Tag Manager
Почитать по теме: Руководство по Google Tag Manager
Отслеживать статистику с других доменов
Код отслеживания Google Analytics и Google Tag Manager виден любому, кто открывает ваш исходный код. Если не настроить фильтр просмотра, кто-то может использовать ваш код отслеживания и испортить вам сбор данных.
Настроить фильтр просмотра можно в Пользовательских фильтрах. Не соответствующие настройке обращения система будет игнорировать, информация по ним не появится в отчетах.
С помощью этого фильтра можно отобрать трафик для определенного имени хоста:
Настройка фильтра
Шаблон фильтра регулярных выражений имени хоста: (^|.)example.com.
Отслеживать ваши собственные сессии
С сайтом компании может работать большая команда специалистов — сотрудников компании. Они не входят в аудиторию покупателей, так что их отслеживать не нужно, чтобы не смещать результаты статистики. Для этого нужно настроить фильтр по IP, исключающий внутренний трафик.
Настройка фильтра по IP
Если вам нужно исключить больше IP-адресов, обратитесь к руководству от Google.
Не отфильтровывать ботов
Значительная часть трафика может приходиться на ботов, которых тоже не нужно отслеживать. Все, что нужно сделать — установить один флажок в настройках представления:
Настройка фильтрации ботов
Отслеживать спамеров
Популярные сайты привлекают спамные ссылки. Посмотрите на трафик, если вы увидите резкий скачок, которому нет причины, скорее всего это наплыв ботов с сайтов спама.
Нужно отсечь ботов из статистики, чтобы анализировать реальные показатели. У ботов обычно нулевое время пребывания на странице, так что настройте отсечение трафика по времени пребывания и 100% отказов.
Теневые домены с большим количеством рефералов можно найти в разделе с реферальным трафиком:
Домены с большим количеством рефералов, скриншот ahrefs.com
Лучше не переходить по ссылкам, могут быть вирусы. Создайте список с такими доменами и исключите их с помощью фильтрации: установите поле фильтра как «Источник кампании», затем перечислите домены в поле «Шаблон фильтра», разделив символом «|»
Настройка фильтров
Под фильтрами есть кнопка, которая позволяет увидеть, как фильтры влияют на ваши данные.
Неправильно настроить соответствие цели
В настройке целей выбирают тип соответствия, их три: «равно», «начинается с» и «регулярное выражение». Если ошибиться и указать не тот тип, данные будут собираться некорректно.
Равно — цель соответствует конкретному адресу ссылки.
Начинается с — при выполнении действия к URL добавляется параметр, ID сессии или транзакция.
Регулярное выражение — нужно учесть условия.
Выбор соответствия цели
Небрежно настраивать параметры UTM
Параметры UTM — это теги, которые добавляют к URL-адресам, чтобы обозначить конкретные источники трафика и удобно отслеживать переходы в Аналитике. В основном эти метки используют с платной рекламой, покупными и партнерскими ссылками.
При составлении ссылки с меткой обязательно нужно указать поля:
utm_source — источник трафика, рекламная площадка (рекламодатель, сайт, социальная сеть);
utm_medium — тип трафика (соцсети, баннерная реклама или другой);
utm_campaign — обозначение рекламной кампании, продукта или предложения.
Составлять ссылки с UTM вручную неудобно, быстрее использовать сервисы:
URL кампании в Google Analytics для ссылок на сайты;
URL для приложений Google Play;
URL для отслеживания кампаний для iOS в Apple App Store.
Допустим, запускаем рекламу в Twitter. По умолчанию трафик попадает под «twitter.com / referral», кампанию отслеживать неудобно. Поэтому можно добавить параметры UTM к URL-адресам, которые используем в рекламе.
Заполнение UTM-меток
Эти параметры UTM затем отправляются на серверы GA и используются в соответствующих измерениях.
Отслеживание ссылок с UTM
Если вы связали аккаунт Google Аналитики с активным аккаунтом Google Рекламы и включили функцию автоматической пометки ссылок, то дополнительно прописывать UTM не нужно.
Почитать по теме: Настройка и анализ UTM меток: полное руководство
С отслеживанием ссылок с метками могут быть проблемы, на которые сложно повлиять. К примеру, если пользователь сохранил ссылку с UTM и открывает ее из закладок, переход засчитается рекламному источнику, хотя это будет прямой заход.
Не исключать параметры страницы
В URL страницы могут быть параметры и уникальные идентификаторы сеансов как sessionid, yclid, _openstat и другие. Из-за того, что Google Analytics распознает ссылки с параметрами как разные URL, одна страница будет занимать несколько строк в отчете:
Одна страница и несколько URL с параметрами в Аналитике, скриншот ahrefs.com
Исключите из отчетов параметры и идентификаторы, чтобы GA воспринимала одну страницу.
Найдите страницы с параметрами:
Используйте ? в поиске
В Google Analytics отобразите все URL с параметрами и в настройках просмотра исключите параметры, которые вы не хотите видеть в своих отчетах.
Исключение параметров
Убедитесь, что вы не исключили:
параметры поискового запроса, иначе система заблокирует данные по внутреннему поиску;
параметры UTM;
отдельные параметры, которые вы хотите отслеживать, к примеру, для разных продуктов интернет-магазина.
Не объединять одни и те же источники трафика
Некоторые из каналов трафика повторяются, потому что система распознает их как разные источники. Частый пример — реферальный трафик с Facebook:
Повторяющиеся источники, скриншот ahrefs.com
Эти реферальные ссылки Facebook использует в целях безопасности и конфиденциальности, но они усложняют аналитику трафика по источникам.
Это можно исправить фильтрами, этот объединяет реферальный трафик с разных каналов, относящихся к Facebook:
Настройка фильтра
Ниже есть проверка фильтра, убедитесь, что он работает правильно:
Работа фильтра, скриншот ahrefs.com
Google Analytics не применяет фильтры задним числом, поэтому вам все равно придется иметь дело со старыми данными без объединения источников.
Почитать по теме: Колдуем над Google Analytics: как настроить учет реферального трафика
Не пользоваться списком исключений
Некоторые домены стоит внести в список исключаемых источников перехода, чтобы трафик из них не отмечался отдельно в качестве новых пользовательских сеансов.
Это особенно полезно в трех случаях:
Сторонние платежные системы Если вы используете сторонние платежные системы, клиенты с сайта перенаправляются в систему для оплаты и обратно на сайт по завершению платежа. Если не исключить платежную систему из источников, система засчитает возвращение клиента на сайт как новую сессию.
Отслеживание поддоменов С помощью списка исключаемых источников перехода можно исключить трафик с доменов и их поддоменов. В списке используют вариант соответствия «содержит»: если добавить example.com, трафик с поддомена sales.example.com также будет исключен, потому что доменное имя содержит example.com.
Междоменное отслеживание Междоменное отслеживание Google Analytics позволяет объединить данные с нескольких доменов. Это бывает нужно, если веб-мастер хочет объединить несколько сайтов в рамках одного бизнеса.
Список исключаемых источников перехода находится в разделе Отслеживание. Укажите домены, которые вы не хотите видеть как источники переходов в отчете. Введите домены в формате example.com, чтобы охватить все субдомены.
Добавление доменов в исключения
Настройка Google Analytics зависит от сложности ваших требований к предоставляемой информации. Если вы видите что-то неладное в статистике, возможно, дело не в сайте, а в сборе данных, так что советуем проверить, как у вас настроен сервис аналитики.
Разбор ошибок настройки Метрики есть в отдельном материале «Популярные ошибки настройки Яндекс.Метрики»
В конце прошлого года Workspace (тендеры, работа и фриланс-биржа в сфере digital) провел опрос компаний — заказчиков digital-услуг с целью выявить основные критерии выбора подрядчиков и сценарии их поиска.
В статье мы хотим обратить ваше внимание на несколько ключевых моментов опроса, рассказать, чем может быть полезен сервис Workspace для привлечения новых клиентов, и дать несколько советов о том, как их получить.
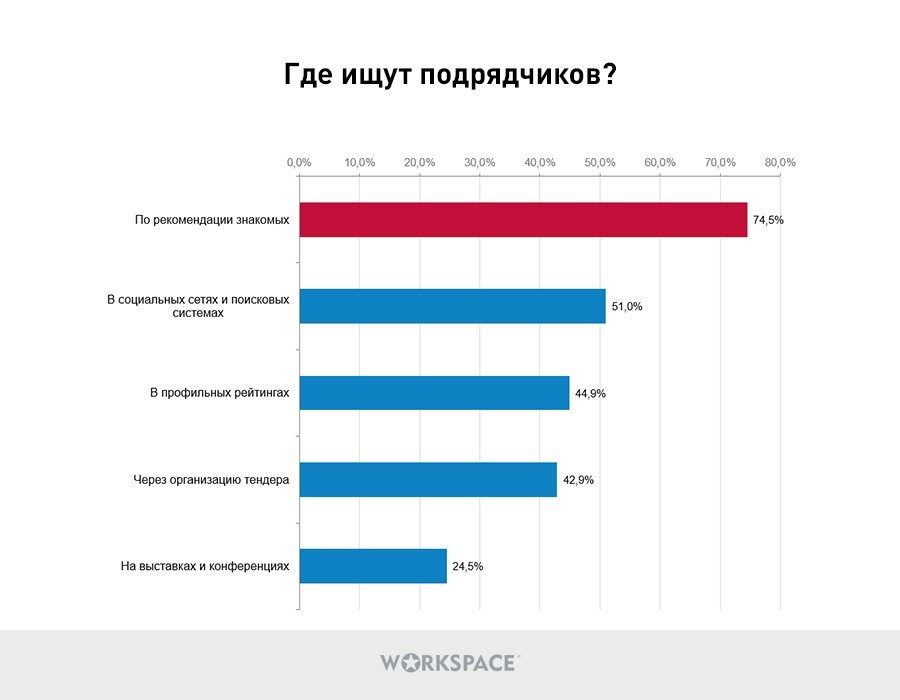
Как и где заказчики поискового продвижения ищут подрядчиков
Начнем с обзора основных каналов поиска. Как показал опрос, подавляющее большинство заказчиков практически любых digital-услуг предпочитают отталкиваться от рекомендаций знакомых (74,5%). Казалось бы, это настоящий приговор молодым компаниям, еще не имеющим большую клиентскую базу. Однако по факту, далеко не всегда у заказчиков есть знакомые, которые остались довольны сотрудничеством со своим подрядчиком. Плюс, специализация SEO-подрядчиков из «сарафанного радио» не всегда соответствует требуемой. Поэтому даже молодым агентствам или начинающим фрилансерам есть за что побороться. Особенно, учитывая, что востребованность таких каналов как рейтинги (44,9%), тендеры (42,9%) и социальные сети/поисковики (51%).
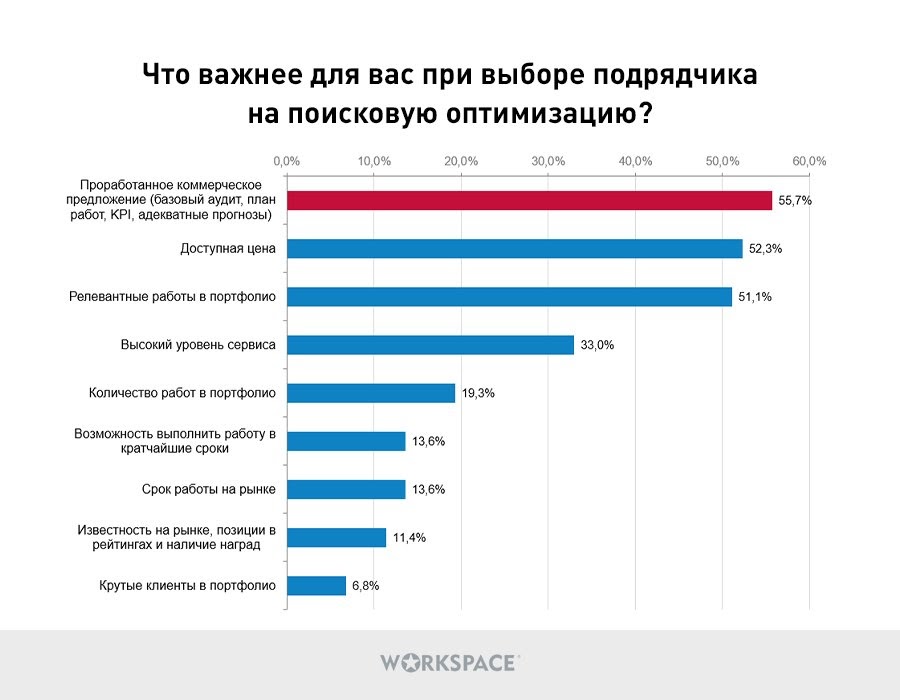
Каковы критерии выбора SEO-подрядчиков? ТОП-3:
качество коммерческого предложения (55,7%);
доступная цена (52,3%);
наличие в портфолио исполнителя кейсов, максимально похожих на проект заказчика (51,1%).
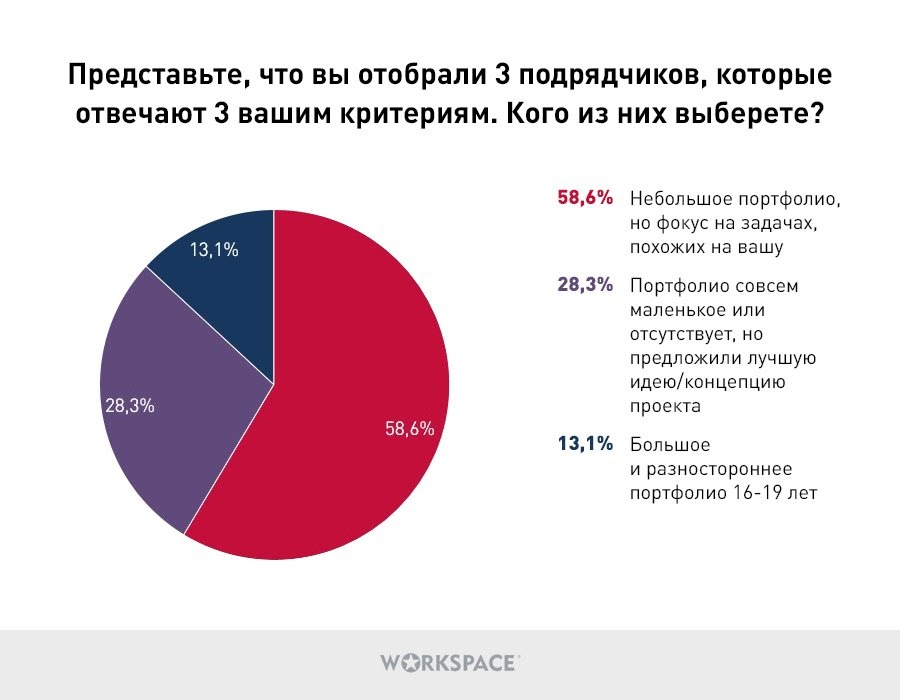
Что касается портфолио, пока сами исполнители спорят, по какому принципу лучше всего их составлять, заказчики уже давно определились: его размер не имеет такого же мощного значения, как специализация. Это значит, что если клиент представляет медицинскую отрасль, он, скорее всего обратится к подрядчикам, которые уже работали с данной тематикой и так далее.
Как получать заявки с помощью Workspace
Как видно на первой диаграмме, около 42,9% участников опроса используют тендеры. Это хороший показатель. Для тех, кто хочет использовать данный канал, мы расскажем, как участвовать в тендерах на Workspace.
Каждый день здесь появляется 5-10 открытых тендеров на digital-услуги. Так как Workspace имеет общую базу данных с проектами CMS Magazine & Рейтинг Рунета, чтобы работать на Workspace в качестве исполнителя, необходимо воспользоваться логином и паролем от личного кабинета CMS Magazine.
Все агентства вначале получают возможность бесплатно откликнуться на 3 объявления каждой из 5 основных услуг (веб-разработка, мобильная разработка, SEO, маркетинг/PR и контекстная реклама). После завершения лимита бесплатных откликов, при желании, агентства могут приобрести платные опции — Дополнительные отклики или PRO-аккаунт.
Дополнительные отклики продаются пакетами от 10 штук и не имеют привязки к временным диапазонам. PRO-аккаунты приобретаются на фиксированный срок (один, три, шесть месяцев) и включают следующие возможности:
Размещение на верхних позициях каталогов (например, в каталоге SEO-агентств);
Приоритетный подбор в приватные и публичные тендеры;
Размещение вверху списка исполнителей в личном кабинете заказчиков.
Кстати, зарегистрированное агентство может одновременно выступать как в роли исполнителя, так и заказчика (на случай желания отдать часть работы на субподряд).
Аналогичным образом устроена и фриланс-биржа Workspace. Здесь так же предусмотрена лента новых задач и каталог специалистов. Однако в этом случае отклик на заявки бесплатен (как и их создание) — фрилансерам нужно только зарегистрироваться, мониторить появление новых задач и реагировать на приглашения заказчиков к сотрудничеству.
Для тех, кто ищет работу, есть соответствующий бесплатный раздел — Работа для digital-специалистов. Здесь находится лента резюме и лента вакансий. Что примечательно, многие из вакансий — удаленные.
Советы тем, кому нужны новые клиенты
На основе результатов опроса и нашего опыта позволим дать себе несколько советов тем, кто заинтересован в получении новых клиентов на поисковое продвижение:
Акцент в портфолио стоит делать именно на те проекты, которыми вы хотите заниматься и далее. В идеале это такие отрасли и тематики, в которых есть деньги, в которых вы неплохо разбираетесь и у вас уже есть эффектные кейсы. В кейсах важно демонстрировать не только список проведенных работ и результаты, но и ход вашей мысли, аргументацию принимаемых решений. Именно такие вещи и демонстрируют имидж экспертов.
Главный ключ к сердцу клиента — коммерческое предложение. Чем тщательней оно будет проработано, чем точнее в нем будут отражены потребности и специфика бизнеса заказчика — тем выше шансы на успех. В идеале стоит тщательно курировать работу специалиста, отвечающего за подготовку КП и анализировать обратную связь. Иногда она дает большую базу для размышлений и позволяет в дальнейшем делать свои КП наиболее привлекательными для заказчиков.
Реальные отзывы клиентов сегодня актуальны как никогда, особенно на фоне массы фейковых. Собирая их на своем сайте, идеально давать не только ссылку на сайт заказчиков, но и прикреплять фото авторов и другие социальные доказательства вашей экспертизы. Также продажам помогает размещение отзывов довольными клиентами на лидогенерирующих площадках типа Workspace, где оставлять отзывы могут только организаторы тендеров, выбравшие победителя. Клиенты понимают, что на своих собственных сайтах подрядчики просто не будут публиковать негативные отзывы, поэтому они больше ориентируются на сторонние ресурсы.
Чем крупнее компания, тем больше вероятность, что выбор подрядчика будет осуществляться путем проведения тендера. То есть агентства, заинтересованные в регулярном получении крупных клиентов, должны научиться работать с тендерами. К тому же тендеры для новых или небольших компаний, зачастую — чуть ли не единственный способ заполучить первого крупного клиента. Впрочем, тут нельзя забывать о различных партнерских программах от лидеров digital-рынка. Среди минусов первого варианта — придется двигаться путем проб и ошибок, а второго — придется пожертвовать самодостаточностью агентства и возможностью выстраивать клиентскую и ценовую политику самостоятельно.
Самая большая боязнь для клиентов фрилансеров — что таковые могут просто пропасть и не отвечать на звонки и письма. Поэтому для этой категории подрядчиков особенно важно показать свою благонадежность, например, за счет демонстрации активных страниц в соцсетях или на таких профильных ресурсах как habr или vc.
Катерина Логвинова, директор по коммуникациям CMS Magazine
Об этом в ходе SEO-вебинара рассказал Джон Мюллер. Диалог с представителем Google начал веб-мастер:
«На моем сайте обвалился трафик. Ресурс посвящен рингтонам. Он предлагает для скачивания 60 тысяч аудиофайлов.
В декабре прошлого года позиции сайта в SERP рухнули. После этого я попытался проверить мой веб-проект в индексе Google c помощью команды «site:». К сожалению, таким образом я обнаружил лишь семь проиндексированных страниц. При этом никаких сообщений о применении к моему сайту ручных санкций от ваших специалистов я не получал.
Подскажите, может это поисковые алгоритмы наложили на меня какие-то фильтры, что привело к выпадению страниц из Google SERP? Что нужно сделать, чтобы вернуть трафик на сайт?»
Сперва сотрудник Google засомневался в способе проверки индексации:
«Если говорить в общем, то используемая вами команда не позволяет обнаружить все проиндексированные нами страницы. Безусловно, с ее помощью можно получить грубое представление об индексации страниц в Google, но этот список будет далеко не самым полным. Поисковый оператор «site:» не для этого создавался.
Получить более исчерпывающую информацию об индексации URL-адресов сайта можно в соответствующем отчете в Панели веб-мастера Google».
Затем Мюллер коснулся вопроса падения посещаемости:
«Что касается обвала трафика, то тут все довольно сложно. Говоря о сайте, который специализируется на рингтонах, то помочь ему будет не так и просто. Дело в том, что наши алгоритмы стремятся находить по-настоящему уникальный и качественный контент.
И вот тут вырисовывается дилемма, когда ваш ресурс предлагает пользователям контент, который представлен на множестве других сайтов интернета. Честно, я не думаю, что в таком случае наши алгоритмы посчитают ваш проект очень важным и захотят лучше представлять его в результатах поиска».
В конце спикер поисковой системы высказал мнение, как помочь веб-мастеру с типовым контентом:
«Учитывая сказанное выше, вы должны искать пути, как выделить себя среди множества однотипных конкурентов. Вам необходимо дать понять целевой аудитории, что именно вы предлагаете рингтоны, которые выгодно отличаются от аналогичных на миллионах других подобных сайтов.
Как этого достичь? Во-первых, можно попытаться добиться такого эффекта за счет вспомогательного контента для каждого рингтона. Во-вторых, можно попробовать улучшить функциональность сайта для ЦА. Но главное, вы должны убедить наши алгоритмы в том, что именно вас мы должны индексировать и ставить на лучшие позиции в SERP, а не тысячи других площадок с банальными списками рингтонов для скачивания.
Я понимаю, что советовать – это одно, а добиться таких качественных изменений – совсем другое. Однако ничего не поделаешь, необходимо стремиться. Причем такой подход мы рекомендуем для всех сайтов, которые распространяют типовый контент. Рингтоны тут всего лишь яркий пример».
Ответы Гуглмена разумны, а потому в большинстве ожидаемы. Вместе с тем он не смог или не захотел объяснить, почему до определенного момента поисковик закрывал глаза на однотипность контента, размещая ресурс довольно высоко в выдаче, но потом вдруг передумал, обрушив позиции сайта в Google SERP.
А вам приходилось уникализировать типовый контент на страницах своих сайтов? Поделитесь опытом с нашими читателями – будем признательны.
Рубрика «Спроси PR-CY»: новый шестнадцатый выпуск!
В рубрику мы приглашаем экспертов из разных сфер, связанных с продвижением сайта, чтобы они отвечали на вопросы наших читателей. До конца рабочей недели в комментариях к этому посту принимаем ваши вопросы к эксперту, а в субботу передадим их ему в работу. Как только эксперт ответит на вопросы, мы выложим с ними отдельный пост в блоге. Если вопросов слишком много, эксперт выберет самые интересные.
На вопросы этой недели отвечает
Игорь Рудник
Специалист с восьмилетним опытом в линкбилдинге, маркетинге и SEO, руководитель биржи прямой рекламы и размещения гостевых статей Collaborator и сервиса крауд-маркетинга Referr, автор курса по линкбилдингу.
Автор Телеграм-канала Igor Rudnyk и спикер профильных конференций Webpromoexperts Seo Day, РИФ+КИБ, RIW, SEMPRO.
Вопросы к Игорю принимаем в комментариях к этому посту до пятницы включительно. Ответы будут не в комментариях, а в отдельном посте в блоге на следующей неделе, когда эксперт поработает над вашими вопросами.
Ждем любые вопросы по SEO, ссылочному продвижению, маркетингу и всему, что вам интересно в сфере работы над проектами в интернете! Эксперт не сможет разобрать вопросы, где нужно детально вдаваться в статистику конкретного сайта, не сможет разобрать общие темы, требующие огромных статей и пропустит простые вопросы, которые гуглятся за минуту.
Приятный бонус за интересный вопрос
Автору самого интересного вопроса мы подарим промокод на бесплатный месяц тарифа «Профи» в Анализе сайтов!
Спроси PR-CY#15: ответы эксперта прошлого выпуска — SEO-TeamLead Siteclinic Ксении Песковой.
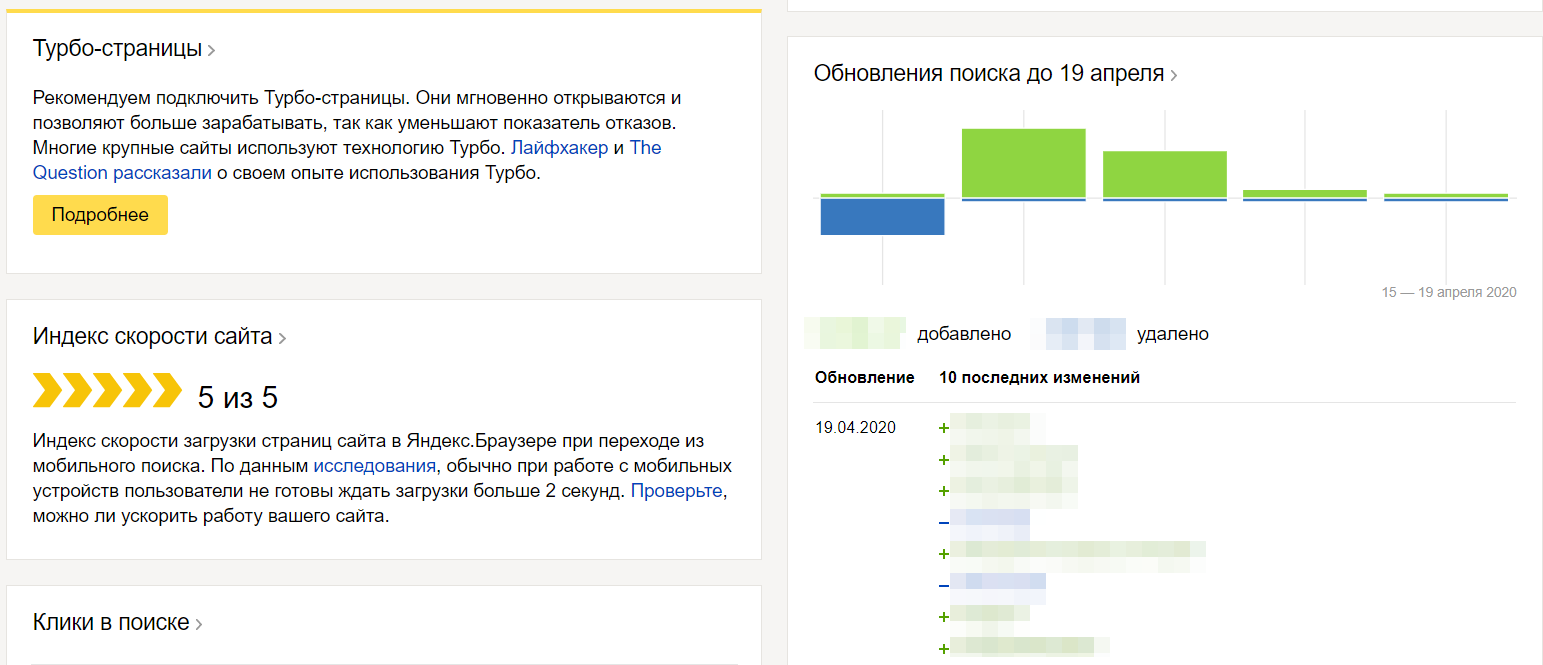
Напомним, в этом блоке отображается актуальная информация об успехах в продвижении ресурса. Новым элементом блока стал «Индекс скорости сайта»:
Индекс скорости рассчитывается на основе перехода пользователей на сайт из мобильного поиска через Яндекс.Браузер. Непосредственный расчет показателя ведется с учетом обезличенных (анонимизированных) данных этого браузера.
Для удобства пользователей «Индекс скорости сайта» также добавлен в «Сводку»:
Индекс будет рассчитываться для сайтов с достаточным трафиком для отображения. Если посещаемость сайта невысокая, то индекс скорости определен не будет. В таком случае заполненные деления на шкале отсутствуют.
Обновление показателя будет регулярным – не реже одного раза в месяц. В настоящий момент новый отчет находится на этапе бета-тестирования.
В Яндексе допускают существенные отличия в результатах измерений скорости сайта разными сервисами, но не видят в этом ничего страшного.
Ранее стало известно, что Яндекс.Вебмастер будет автоматически мониторить ключевые страницы ресурса.
Мы приглашаем экспертов из разных сфер продвижения, чтобы читатели блога PR-CY могли задать им свои вопросы, узнать мнение о каком-то событии в SEO или поделиться проблемой с сайтом.
Вопросы для эксперта мы собирали всю рабочую неделю в комментариях к анонсу. Эксперт этого выпуска
Игорь Рудник
Руководитель биржи прямой рекламы и размещения гостевых статей Collaborator и сервиса крауд-маркетинга Referr, автор курса по линкбилдингу.
Автор Телеграм-канала Igor Rudnyk и спикер профильных конференций Webpromoexperts Seo Day, РИФ+КИБ, RIW, SEMPRO.
Эксперт выбрал интересные вопросы, на которые он может развернуто ответить.
Elena_Zhmurina спрашивает:
«Что вы можете посоветовать фрилансерам-сеошникам, которые сейчас теряют заказчиков? Как им держаться на плаву, чем удерживать оставшихся клиентов?»
Любого клиента в любое время можно удержать качественным решением его потребности.
Что делать, если клиент не готов сейчас инвестировать в SEO?
Постараться донести клиенту, что маркетинг и в частности SEO, это то, что поможет ему максимально быстро восстановиться после кризиса.
Если клиент не внимает вашим аргументам или ситуация действительно такая, что нет возможности сейчас инвестировать в SEO, ваша задача — удержать связь с клиентом. Кризис — время, когда вы можете выстроить более близкие отношения с клиентом.
Для того, чтобы компенсировать клиентов, которые стали на паузу — развивайте существующих клиентов. Предлагайте им максимально персональные и эффективные решения, которые принесут им деньги сейчас или после ослабления кризиса.
Что предлагать клиентам, которые готовы сейчас продолжать работы?
Инвестиции в вечнозеленый контент и страницы, которые будут актуальны и после кризиса.
Запуск новых продуктов и рынков — многие предприниматели готовы сейчас стартовать новые направления, чтобы не терять время.
Нестандартные решения — это уже третий раз, когда я об этом говорю, но это действительно то, что сейчас ждет от вас бизнес.
И рекомендую посмотреть вебинар о SEO в кризис.
AlexPsp спрашивает:
«Как Google лучше рассказать про регион сайта (город)? Особенно если есть разные поддомены по городам, как у Билайна, но нет оффлайн точек (организаций) в городах».
Убедитесь в том, что эти поддомены вам необходимы. Возможно, можно продвигаться без них? Учитывая, что нет оффлайн точек.
Если нет региональных представительств, то я бы использовал региональные номера телефонов. Арендовать их на сегодняшний день не проблема.
Для того, чтобы Google не склеил поддомены, необходимо уникализировать контент:
тайтлы, дескрипшины;
цены;
время работы;
отзывы;
и так далее.
Но фундаментально, вам, конечно, нужно решать вопрос с локальными представительствами и регистрировать поддомены в Google My Business.
Рекомендую изучить abakan.zoon.ru, arkhangelsk.zoon.ru, astrakhan.zoon.ru и другие поддомены.
Иван Недурак спрашивает:
«Разгружаю фуру с вопросами:
Усиление ссылок средствами бирж. Есть ли смысл? Вроде как хорошо, если по ссылкам кликают, но насколько это работает через функционал бирж? Или это пустая трата денег и лучше самому сделать несколько переходов, оставить коммент в статье?»
Иван, саму идею, что трафиковые ссылки — это хорошо, я полностью поддерживаю.
То, что каким-либо образом можно эмулировать естественные переходы по ссылкам — не верю. Потому что еще ни разу не видел качественной эмуляции.
Когда мне предлагали налить ботов на сайт, я всегда мог легко по поведенческим увидеть, что это боты. Если я вижу это, то как поисковая система с самым большим объемом данных в мире может этого не увидеть?
Не исключаю, что есть те, кто достигли в этом мастерства, просто я о них не знаю.
Ваши пару кликов по ссылке также не окажут никакого влияния. Поэтому я сторонник того, чтобы использовать нормальные маркетинговые механики следствием которых будут переходы на ваш сайт:
Размещайте статьи на трафиковых сайтах — да, это самая очевидная и самая действенная рекомендация.
Дистрибутируйте — организовывайте посевы в социальных сетях, каналах, email-рассылках. Это приведет трафик в вашу статью и как следствие переходы по ссылкам.
Оптимизируйте статью — если ваша статья будет собирать поисковой трафик, то она будет давать вам длинный хвост переходов по ссылкам.
И так далее.
Успехов!
«На некоторых биржах можно разместить сразу несколько ссылок в статье. Нужно по возможности больше ссылок размещать в статье или одна статья — одна ссылка? Есть ли тут нюансы?»
Я предпочитаю использовать возможности по максимуму. Если в статье можно поставить 2-3 ссылки, то я так и сделаю. При этом я также предпочитаю, чтобы в статье были и другие ссылки.
Давайте будем честны, большинство все еще размещает статью на 2-3 тысячи знаков и с 2-3 ссылками на свой сайт. Это естественно? Нет.
Хорошая публикация — это:
5-10 тысяч знаков текста;
2-3 ссылки на продвигаемый сайт (главную ссылку ставим в первом/втором абзаце, чтобы получить больше переходов);
качественная верстка: списки, таблицы и т.д.;
картинки;
видео;
! ссылки на другие сайты — да, не нужно бояться их ставить.
Когда в статье есть ссылки на другие сайты, то вы:
Участвуете в экосистеме интернета.
Маскируете ссылки на продвигаемый сайт.
Делаете контент полезней.
Поэтому нет никакой проблемы поставить 2-3 ссылки при условии, что вы делаете достойный контент.
«Есть ли смысл закупать ссылки, если у конкурентов ссылочной массы нет/очень мало ссылок? Для примера тематика: продажа тротуарной плитки в Самаре».
Ссылки — не панацея. Это один из инструментов для продвижения сайта. Давайте посмотрим выдачу по вашему запросу.
Давайте посмотрим ТОП-10 Яндекса по этому запросу и их ссылочный профиль:
Маркетплейсы/агрегаторы и сайты с очень весомым брендом.
Локальные игроки.
У вторых сайтов весьма слабый ссылочный профиль, поэтому мы можем сделать вывод, что вы можете соревноваться с ними за счет качества сайта и коммерческих факторов.
Однако отсутствие ссылочного профиля делает вас более уязвимым перед действиями конкурентов и поисковых систем. Поэтому рекомендую инвестировать по мере возможностей в ссылочный профиль и траст сайта.
«Продвижение лендингов/одностраничников ссылками. Насколько важна ссылочная масса для таких сайтов? Когда на большом сайте (интернет-магазин одежды) много ссылок — это выглядит нормально, но когда на лендосе (например, онлайн-курсах для HR) много ссылок — не будет ли это странно?»
Нет, это нормально.
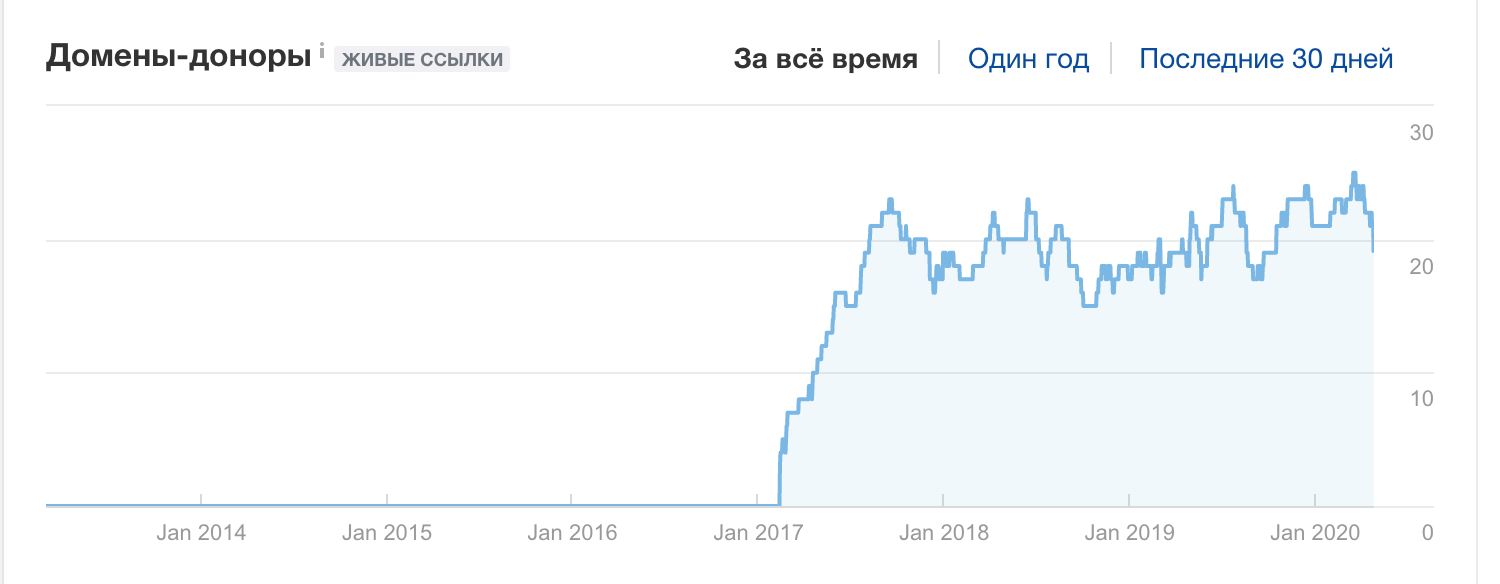
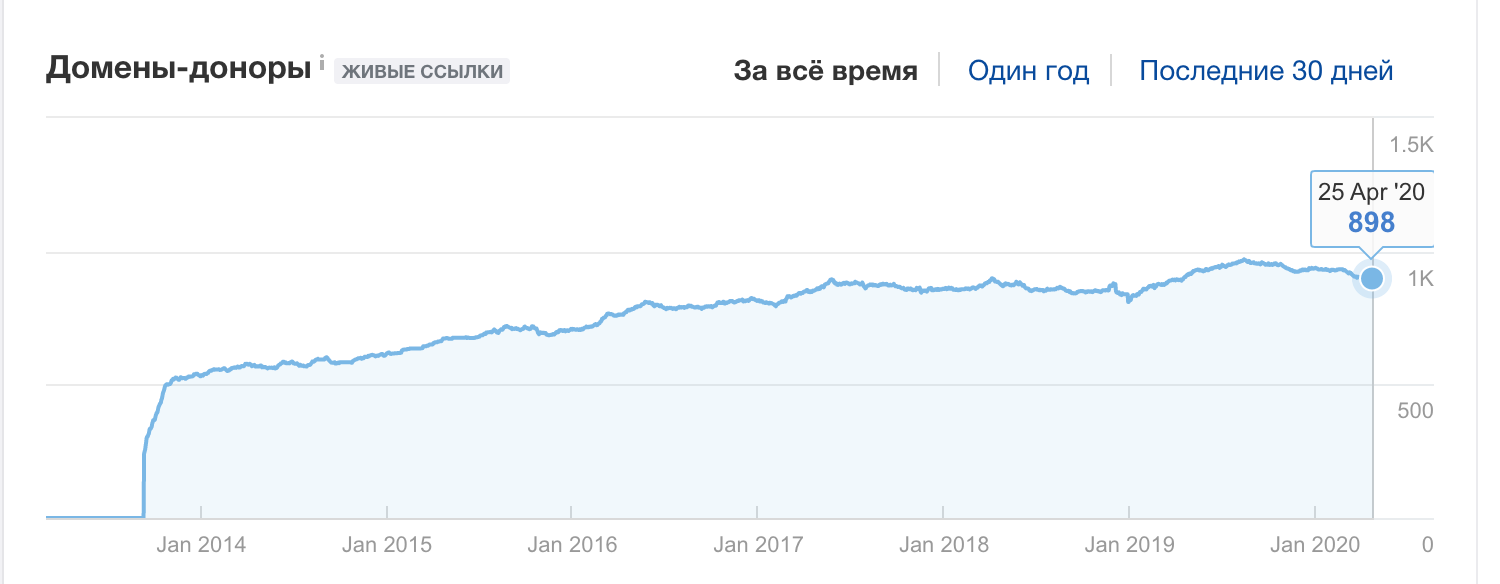
Мы с Сергеем Кокшаровым запускал курс по семантическому проектированию на поддомене, на него появилось несколько десятков ссылок:
Другой пример. Сайт одностраничник:
900 ссылающихся доменов:
Вопрос реализации.
Давайте разберем ваш пример «Онлайн курс для HR». Теоретически, такие курсы запускают эксперты в своей области и это вызывает некий резонанс в индустрии и люди распространяют этот сайт.
Кроме того, запуск курса сопровождается различными пресс-релизами, анонсами и так далее, и в этом нет ничего необычного. Наоборот, подозрительно, когда это не происходит.
Поэтому убирайте все ограничения и мифы. Только вперед!
«Качество или количество? Что делать, если у конкурента постоянный рост ссылок и нет возможности закупать в таком же темпе? Сделать упор на количество или покупать меньше, но более авторитетные?»
Фокусируйтесь на качестве. Долгосрочно это всегда поможет вам выйти сильней. А также оцените заново свои возможности стоит ли продолжать эту гонку. Так как если у вас недостаточно бюджета для борьбы в конкурентной нише, возможно, лучше взять более узкую нишу, сфокусироваться на ней, получить там результат, увеличить ваши ресурсы и затем сделать новый рывок в борьбе с конкурентами.
Капитолина Филиппова спрашивает:
«Вопрос по размещению английской версии сайта: поддомен, папка или отдельный сайт в зоне .com?»
Однозначно в папке, если это позволяет архитектура сайта. Папки лучше тем, что у вас будет общий траст домена и вам не нужно будет развивать несколько сайтов.
Вот пример, когда с поддомена перенесли в папку и трафик сразу вырос:
Источник — teleg.run/devakatalk/2226
При этом, бывают случаи, когда архитектурно невозможно расположить в папке. Например:
сайты реализованы на разных технологиях;
по каким-то причинам вы не хотите соединять русскую и английскую версию на одном домене, например, по причине разных брендов;
и другие примеры.
Еще может возникнуть интересная дилемма, если у вас русская версия сайта на домене .ru, то располагать английскую версию в папку domain.ru/en/ не совсем хорошее решение. Ру домен не будет хорошо ранжироваться в англоязычном сегменте.
В таком случае, варианты:
поднимать второй сайт в доменной зоне .com/org и т.д.;
полностью переехать на com, англоязычную версию сделать основной, а русскую расположить в папку ru, но для принятия такого решения нужно очень хорошо все взвесить и оценить риски.
Но если есть возможность расположить языковую версию в папке — обязательно это делайте.
Если вы затрудняетесь самостоятельно ответить на этот вопрос, рекомендую обратиться за консультацией к специалисту или агентству, которому вы доверяете, так как это фундаментальный вопрос с большим количеством последствий.
Пользователь ytrainer спрашивает:
«Есть сайт с фотографиями вокзалов и ж/д станций. Одно и то же может быть снято в совершенно разные даты, но подписывается одинаково, скажем “Вокзал, ст. Брянск-Орловский”. Подпись идёт и в alt, и в title. Все сеошные руководства советуют делать уникальные страницы. Но вокзал он и есть вокзал. Подписывать одно и то же, снятое в разное время с разных ракурсов, как-то нелогично. Как разумнее поступить в плане SEO?»
Да, с точки зрения SEO нет смысла делать 10 страниц, которые посвящены одному вопросу. Иначе получается каннибализация, то есть поисковая система не понимает какую из этих страниц ранжировать по ключевой фразе и просто будет ранжировать страницу с другого сайта.
Варианты решения
Идеальный вариант Сделать так, чтобы все фотографии «Вокзал, ст. Брянск-Орловский» были на одной странице, и эта страница была оптимизирована под поисковой запрос, а фотографии были расположены просто в хронологическом порядке.
Это еще и хорошо тем, что страница будет постоянно обновляться, а поисковые системы, как и люди, очень любят, когда страницы постоянно обновляются.
Просто вариант Если вы хотите уникализировать страницы, то вы можете в тайтл добавлять переменные: год, дата, номер фото. Тогда у вас будут уникальные страницы, но это не убережет вас от каннибализации.
Надеюсь ответил, но возможно, неправильно понял вопрос, можем обсудить в комментариях.
Vasyl Tsyktor спрашивает:
«После смены тематики интернет-магазина (с одного вида продукта на другой) уже полгода из индекса не исчезают страницы, которых нет на сайте. Эти страницы отдают 404. При использовании инструмента для удаления они исчезают всего на несколько дней, а затем снова появляются со статусом “срок удаления истек” в сёрч консоли. Сколько бы не добавлял в GSC на удаление, они снова появляются. Старая карта сайта удалена и закрыта на всякий случай в роботс. Подскажите, пожалуйста, что можно предпринять, чтобы они выпали из индекса?»
Василий, есть несколько вопросов:
Сколько таких страниц?
Реально ли нужно этому вопросу уделять столько внимания?
Если вас эта проблема все же беспокоит, то надо убедиться, что страницы действительно отдают 404 ответ, так как бывают случаи, когда вы видите 404ю страницу, но при этом ответ сервера не 404, а другой. Можно проверить, например, через collaborator.pro/tools/urlchecker или любой другой инструмент.
Если робот повторно добавляет страницы в индекс, то нужно разобраться, откуда он о них узнает:
Есть ли ссылки внутри сайта на эти страницы? Если да, нужно их убрать.
Также возможен переход по внешним ссылкам на эти страницы.
Один из вариантов, с несуществующих страниц можно поставить 301 редирект на страницу категории или на главную. Это позволит передать вес и скорее всего повлияет на то, чтобы эти страницы не возвращались в индекс.
Но еще раз скажу, что возможно, это вовсе не проблема и пару десятков страниц, которые в индексе никак не влияют на сайт в целом и не нужно бороться с этой проблемой. А стоит сфокусироваться на развитии сайта.
Александр Бортняк спрашивает:
«Посоветуйте, пожалуйста, порядок действий для выхода из под Баден-Бадена».
Александр, Баден-Баден Яндекс накладывает за SEO-тексты, следовательно с ними и нужно разбираться.
Алгоритм:
Пересмотреть все тексты в категориях товаров.
Проверьте наличие генерированных текстов в карточках товаров.
Обратите внимание где еще может быть текстовый спам: перелинковка, заголовки и так далее.
При необходимости обратитесь к поддержке Яндекса, чтобы получить пример страниц с проблемой. Рекомендую статью.
Пользователь mechman спрашивает:
«В Яндексе трафик есть, а из Google крохи. Какие первые пять вещей нужно сделать в этом случае? Чтобы трафик из Google появился».
В контексте последующих вопросов, то предположу, что речь идет о молодом блоге с еще не развитым ссылочным профилем. Скорее всего в этом и проблема, так как Google гораздо больше, чем Яндекс, обращает внимание на ссылочный траст сайта.
«Если никогда не занимался покупкой ссылок, то что и как можно сделать из серии “точно не навредит”? И какого результата стоит ожидать?»
Вы задали абсолютно верный вопрос 🙂 Если вы только начинаете постигать линкбилдинг, то первое на чем нужно сфокусироваться, это безопасность:
используйте брендовые анкоры и не используйте коммерческие;
наращивайте ссылки постоянно, а не ситуативно;
используйте только вечные ссылки;
придерживайтесь принципа лучше меньше, но лучше;
комбинируйте разные методы линкбилдинга: гостевые статьи, крауд-маркетинг, сабмиты;
и посмотрите мое видео о построение ссылочного профиля.
«Если есть блог с посещаемостью 1000 в месяц, то как его можно монетизировать безопасно, чтобы не прекратился рост?»
Понимаю ваши опасения. Монетизация далеко не обязательно должна быть риском прекращения развития блога. Главное — продолжать выпускать материалы.
Давайте разберем основные методы монетизации блога.
Объективно, 1000 аудитории в месяц это очень мало. И я бы фокусировался в первую очередь на увеличение аудитории до 1000 в сутки, а затем переходил к монетизации.
Но, отвечаю на ваш вопрос:
Контекстная реклама и рекламные сети
Это самый простой метод. Рекламные сети от поисковых систем:
https://www.google.com/adsense/
https://partner2.yandex.ru/
Вы просто ставите рекламные блоки и начинаете зарабатывать с просмотров и переходов по рекламе. С 1000 просмотров вы будете зарабатывать 0.5-3$.
Спонсорские посты
Размещение рекламных постов в блоге — это хороший метод монетизации. Вы делаете обзор продукта заказчика и зарабатываете на публикации.
Рекомендую помечать такие посты как Реклама, чтобы не вводить читателей в заблуждение, а также выработать политику частоты размещения рекламных публикаций. Заказы на такие публикации вы можете получать в бирже Коллаборатор, либо напрямую с вашего блога.
Также есть и более сложные форматы сотрудничества, которые вам могут пригодиться в будущем. Перечислю кратко:
cпецпроекты — подразумевают плотное взаимодействие с рекламодателем и создание неких креативных материалов;
баннеры — продажа баннеров напрямую рекламодателям более выгодна, чем рекламные сети;
емейл-рассылки — собирайте емейл базу сразу, это ваш актив;
вебинары — редко используемый формат, но эффективный;
образовательные материалы, курсы — если вы ведете экспертный блог, то можете сделать закрытые обучающие материалы и продавать;
сервисы — создание микросервисов, также может быть хорошим способом монетизации;
услуги — снова же, если у вас экспертный контент, то к вам будет формироваться уровень доверия и вы можете оказывать услуги;
консалтинг — хороший способ монетизации экспертного блога, но занимает ваше время;
контент по подписке — за исследования и глубокие материалы люди готовы платить.
Удачи в развитии блога!
Сергей Шинкарев спрашивает:
«Общеизвестна рекомендация насчёт количества внутренних ссылок на странице — не больше сотни. Однако, практически все магазины на Битриксе значительно превышают этот лимит. Простые решения не подходят, приходится для каждого клиента выдумывать свои индивидуальные костыли. Вместе с тем, у меня есть клиенты, уверенно занимающие ТОП10, у которых «на морде» — 400 внутренних. Есть ли смысл сейчас обращать внимание на этот параметр?»
Нет, это устаревшая рекомендация и нет смысла на этом фокусироваться.
Откуда возникла эта рекомендация
Есть такое понятие «краулинговый бюджет сайта» — это объем страниц, который краулер поисковых систем, просматривает на вашем сайте.
Ранее когда ресурсы поисковых систем были значительно меньше, нужно было стараться не создавать лишних внутренних ссылок, чтобы не тратить ресурсы краулера впустую и он мог пройтись по всем ссылкам и страницам сайта.
На сегодняшний день, нет необходимости стараться уменьшить количество внутренних ссылок до 100 на страницу. 200-400 внутренних ссылок — это нормальное количество. Чтобы убедиться в моих словах — посмотрите количество внутренних ссылок на любом крупном интернет-магазине или маркетплейсе.
О внутренней перелинковке рекомендую посмотреть вебинар с Сергеем Безбородовым. Это самый дельный доклад по этой теме, который я видел. Да, я тут слегка ангажирован, так как мы были его организатором, но поверьте мне на слово.
Elena_Zhmurina спрашивает:
«Есть ли такие ниши, где компаниям нет смысла вкладываться в конкуренцию в органике, потому что это выйдет суперсложно и дорого, и нужно только тратить на рекламу?»
Конечно, есть ниши с очень высокой конкуренцией в поисковой выдаче и если у вашей команды недостаточно экспертизы и бюджета, то нет никакого смысла рассчитывать на SEO, лучше сфокусироваться на других каналах привлечения клиентов.
Пример ниш:
окна;
многие категории классической бытовой техники: холодильники, стиралки и т.д.
цифровая техника;
и так далее.
Высококонкурентных ниш очень много, поэтому для молодого бизнеса с небольшим бюджетом нужно уделить очень много внимания именно поиску ниши, а затем способу продвижения.
В зависимости от ниши бизнеса вы можете продвинуть бизнес через:
Ютуб;
инфлюэнс маркетинг;
персональный бренд;
контекстную рекламу;
Инстаграм (для многих ниш это сильный канал продаж);
и так далее.
Успехов!
Пользователь alff спрашивает:
«Вопросы по поводу новостных сайтов.
Стоит ли перепубликовывать новости без рерайта, чистый копипаст, для того, чтобы на сайте были постоянные обновления? Или лучше убрать копипаст, даже если обновлений не будет тогда вообще (например, выходные, праздники)? Важнее обновления на сайте или уникальность контента?»
На копипасте сайт не построить, но если это делаете, то всегда ставьте ссылку на источник. На новостном сайте, конечно, более важна регулярность обновлений.
С другой стороны, многие редакции не публикуют новости в воскресенье и гораздо меньше материалов выпускают в субботу.
Лично я работаю только с уникальным контентом. Копипаст — всегда риск.
«Какой свежести должны быть новости? Допустим, вышла новость в ТАСС, стоит ли про нее писать (рерайт, копирайт), если прошло уже 3 часа? Если прошло 6 часов?»
Зависит от того, на какой трафик вы рассчитываете. Если у вас есть ядро аудитории и они заходят читать только к вам, то имеет смысл.
Если вы рассчитываете на трафик из поиска, то нет, так как основной трафик на новость уже получат другие издательства и лучше сфокусироваться сейчас на свежих новостях.
«Некоторые новости хорошо попадают в быстроиндекс, приносят трафик с Яндекса и Google. Но чаще новости вообще не приносят никакого трафика, хотя попадают в быстроиндекс, но потом также незамеченные вылетают. Это проблема контента? Или это может быть проблемой сайта?»
Думаю, это вопрос исключительно конкуренции. Новостных сайтов очень много и основной трафик забирают именитые издательства. Я бы на вашем месте сделал основной упор именно на скорость появления новостей и на то, как быстро они попадают в Google и Яндекс Новости.
Alex5860557 спрашивает:
«Оба мои вопроса интересны именно с позиции поисковых систем. Как они к этому отнесутся:
У нас на сайте 2000 товаров. Характеристики указаны, но нет описания. Есть ли смысл добавлять шаблонное описание “Купить (название подкатегории товара) выгодно и удобно на site.by” или лучше вообще без описания?»
С точки зрения текстовой оптимизации ваша задача — добиться того, чтобы на странице присутствовали нужные ключевые слова. Как правило, это можно сделать и без использования шаблонного текста.
Но есть другой более важный момент. Полнота информации и поведенческие факторы по сравнению с конкурентами. Если в вашей карточке присутствуют только характеристики, а у конкурента:
подробное описание;
авторские фотографии;
отзывы от покупателей;
видео-обзор;
история изменения цены;
и так далее.
То карточка вашего конкурента будет гораздо полезней и интересней для пользователя и вы просто не сможете конкурировать.
Поэтому очень важно о каких товарах мы говорим. Об айфоне или о карточке шурупа.
В любом случае:
лучше постараться не использовать шаблонные тексты;
постараться сделать карточку лучше, чем у конкурентов по полноте информации.
«Мы добавляем текст на продвигаемую страницу. Надо ли выделять жирным шрифтом ключевые слова? Или наоборот это хуже?»
Нет, не нужно. Этот метод оптимизации работал лет 7-8 назад и на сегодняшний день не работает и является спамной механикой. Выделять жирным стоит только те фрагменты текста, на которых вы хотите сфокусировать внимание читателя и сделать акценты.
Elena_Zhmurina спрашивает:
«Для архитектуры сайта обычно советуют использовать SILO-структуру со страницами-хабами. Она действительно так идеальна или все-таки подходит не всем сайтам? Есть ли решения еще лучше?»
Если кратко — ничего лучше SILO-структуры нет.
SILO-структура — это в первую очередь про логику для пользователя, чтобы товары или статьи на сайте было легко найти. Конечно, в первую очередь это важно для интернет-магазинов и маркетплейсов, где большое количество позиций.
При этом, если структура сайта выстроена логично, то это дает вам следующие преимущества:
масштабируемость — вы сможете без проблем добавлять новые товарные категории, новые товары и ваш сайт все также будет оставаться понятным для людей и поисковых систем;
«дружба» с поисковыми системами — они смогут легко краулить, индексировать ваш сайт; это очень важно, когда у вас хотя бы десятки тысяч товаров, а тем более сотни тысяч и миллионы SKU;
легкая организация внутренней перелинковки — для логичной структуры легко организовать внутреннюю перелинковку.
У нас с Сергеем Кокшаровым есть платный курс по семантическому проектированию, который вскоре мы сделаем бесплатным, анонс будет в моем телеграм канале.
Юрий Глинский спрашивает:
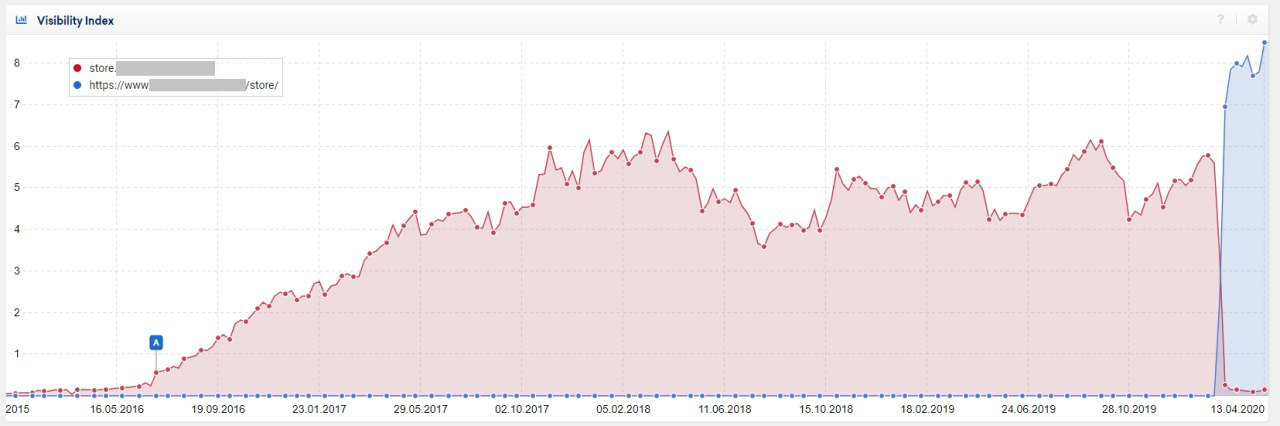
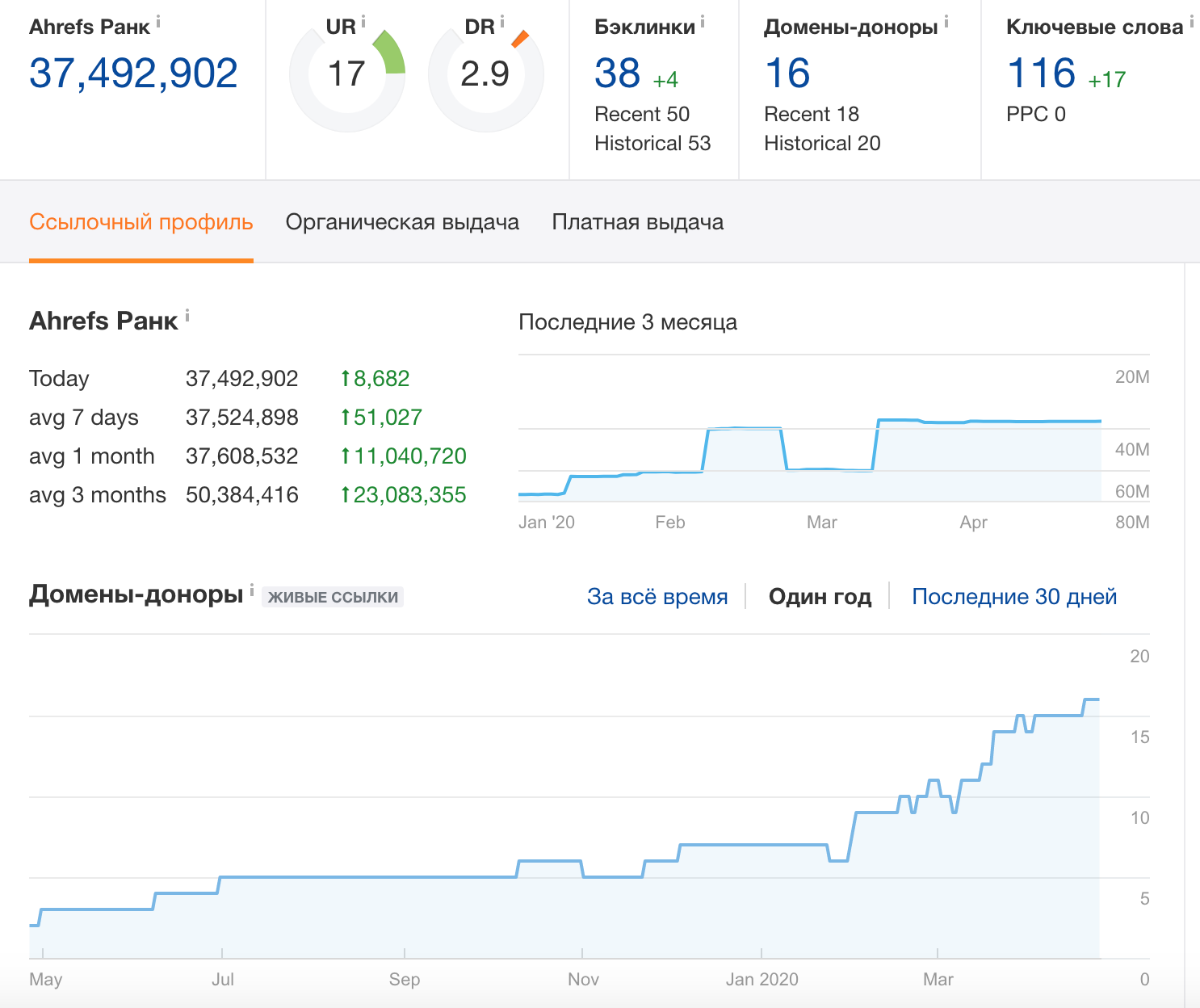
«Игорь, дайте, пожалуйста, рекомендацию, как вогнать в топ-10 запрос «ритуальные услуги минск» и «ритуальные услуги» сайт: pohoronim.by . Буду крайне признателен, если поможете».
Юрий, сайт у вас молодой, поэтому фронт работ достаточно большой. При этом сайт уже неплохо ранжируется по некоторым ключевым запросам, в первую очередь я рекомендовал бы сфокусироваться именно на тех запросах, по которым ваш сайт уже положительно воспринимается поисковыми системами.
Основные рекомендации
1. Увеличить траст сайта и задать динамику ссылочному профилю
Сейчас ссылочный профиль сайта очень слабый и без какие-либо работы не проводятся:
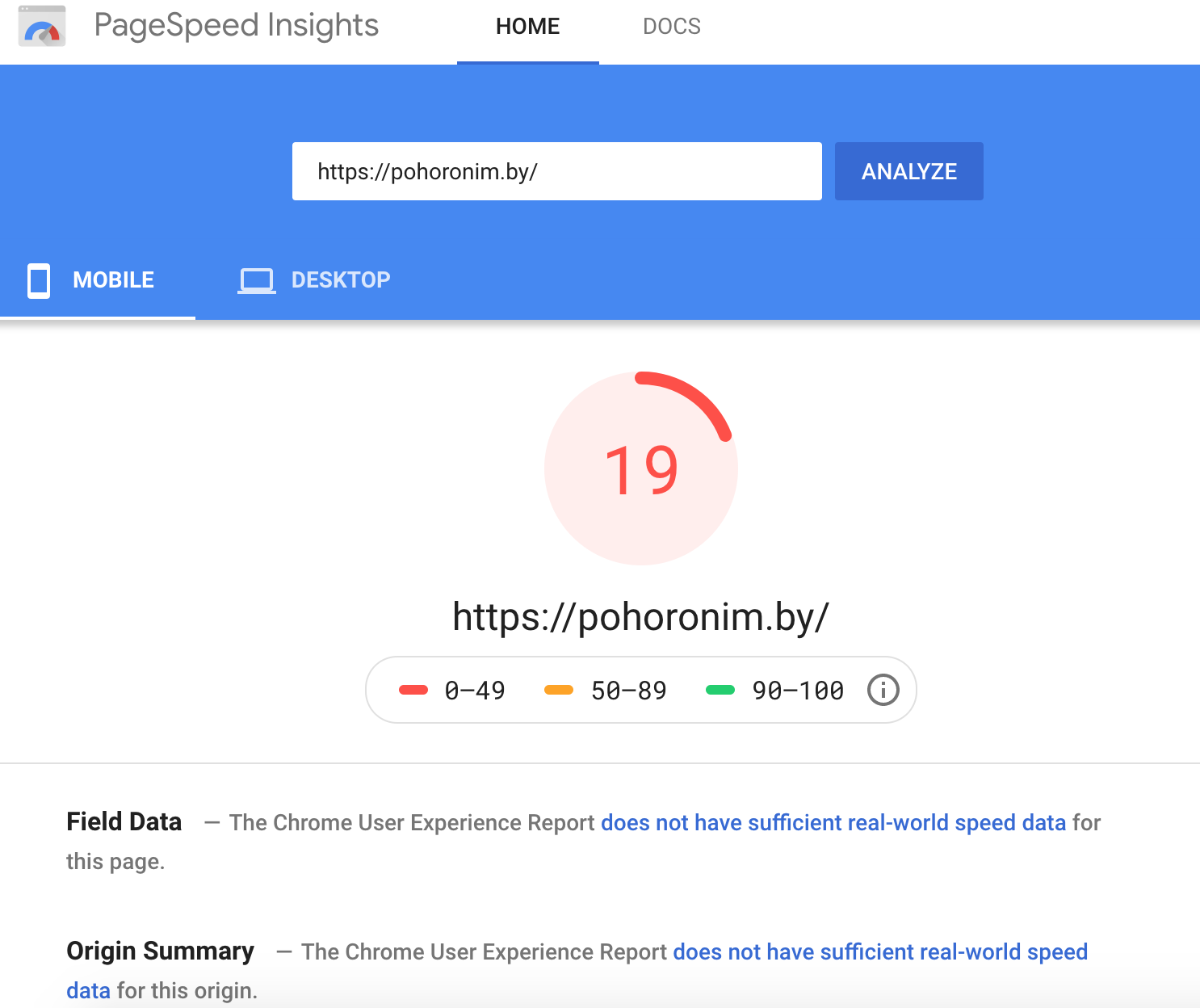
2. Увеличить скорость сайта
Используйте PageSpeed Insights для проверки. Сейчас скорость загрузки сайта на мобильных устройствах неудовлетворительная, это нужно исправить.
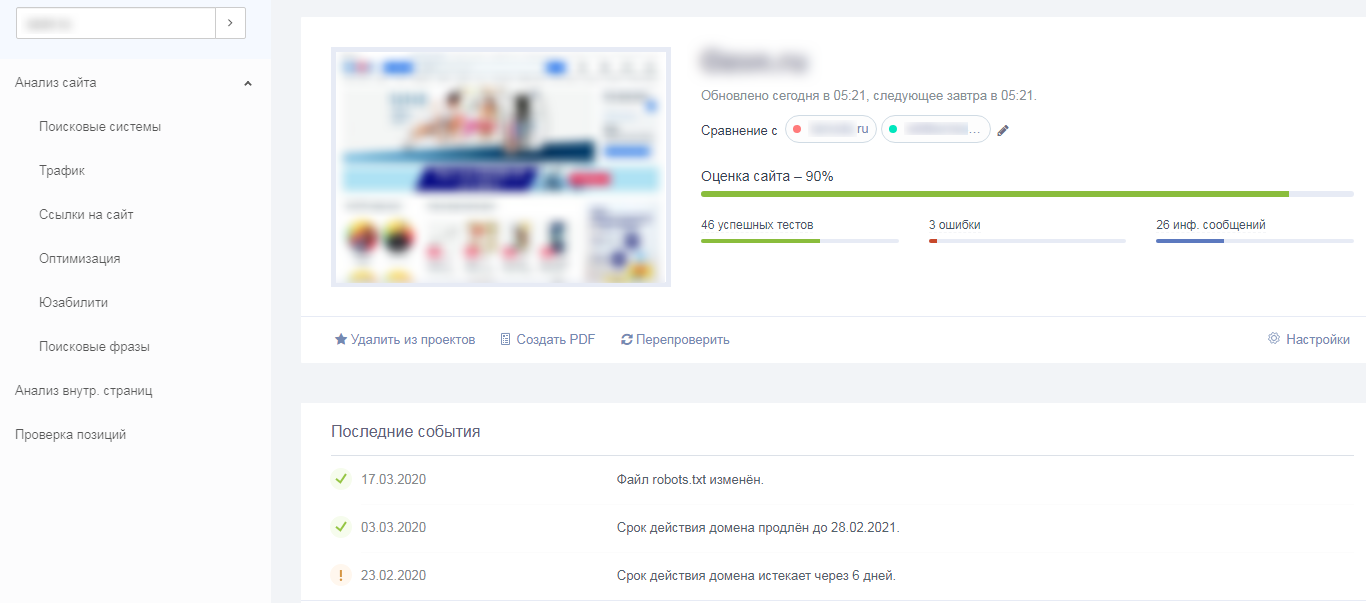
3. Устранить ошибки внутренней оптимизации сайта
Присутствуют ошибки внутренней оптимизации. Рекомендую проверить сайт и устранить проблемы.
В дополнение рекомендую воспользоваться:
SEO-чеклистом — чтобы убедиться, что ваш сайт соответствует самым важным пунктам оптимизации;
ознакомьтесь с моим руководством для молодых сайтов .
Фокусируйтесь на том, чтобы получать больше трафика по широкому спектру целевых запросов. Гонка за единым запросом — не совсем верная цель с точки зрения получения заказов и прибыли.
Совет от редакции PR-CY:
Проверить сайт и найти ошибки поможет сервис Анализ сайта от PR-CY: он проверит сайт по 70+ параметрам, оценит главную и внутренние страницы, сравнит с конкурентами, покажет ошибки и даст советы по исправлению со ссылками на полезные статьи.
Есть бесплатный режим проверок, на платном больше функций и графиков. Неделю тестируйте эти функции бесплатно и оставайтесь, если понравится.
Пользователь seoiddqd спрашивает:
«Подскажите, что делать с товарами, которые не в наличии?
Если они не выводятся в листингах, нужно ли их оставлять в сайтмапе, чтобы они индексировались и находились в поиске?
С одной стороны, человек, даже если попадает на страницу товара из поиска, то купить не сможет и, вероятно, закроет страницу сразу. Может плохо сказаться на поведенческих, особенно если это, например, электронные компоненты и аналога нет, нужен именно этот товар. С другой стороны, пользователь может пойти по «Рекомендуем», «Похожие товары» и дальше по каталогу».
Солидарен с вашими рассуждениями, но лучше не удалять карточки, а сделать следующее:
Переносить такие товары вниз категории;
В карточке выводить кнопку для заявки «Уведомить когда появится».
Показывать похожие. Если нет похожих, показывать наиболее популярные.
Спасибо всем за вопросы. Успехов в развитии!
Бонус за интересный вопрос
Автор самого интересного вопроса — пользователь Иван Недурак, ждите письмо с промокодом на бесплатный месяц тарифа «Профи» в Анализе сайтов!
Мнение редакции PR-CY может не совпадать с мнением приглашенного эксперта.
 Изменение настройки в Google Tag Manager
Изменение настройки в Google Tag Manager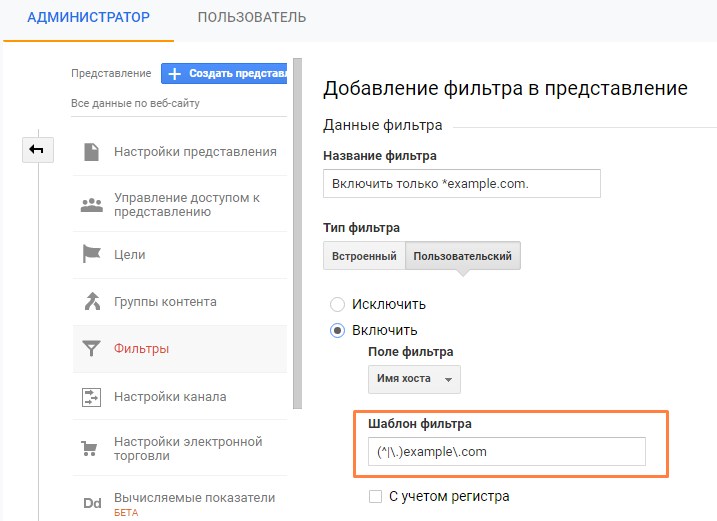 Настройка фильтра
Настройка фильтра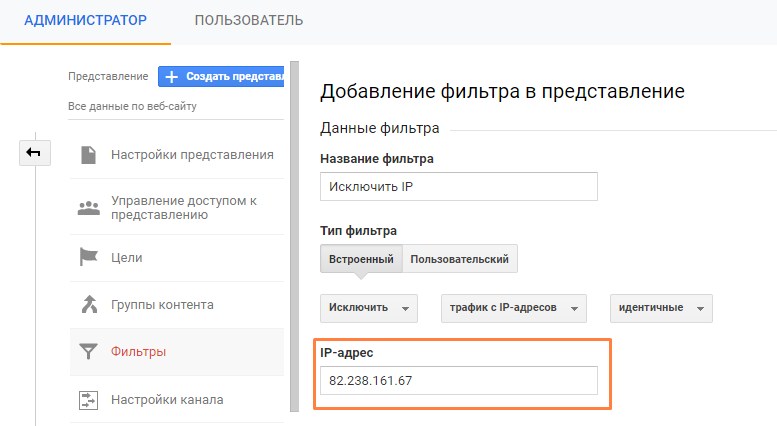 Настройка фильтра по IP
Настройка фильтра по IP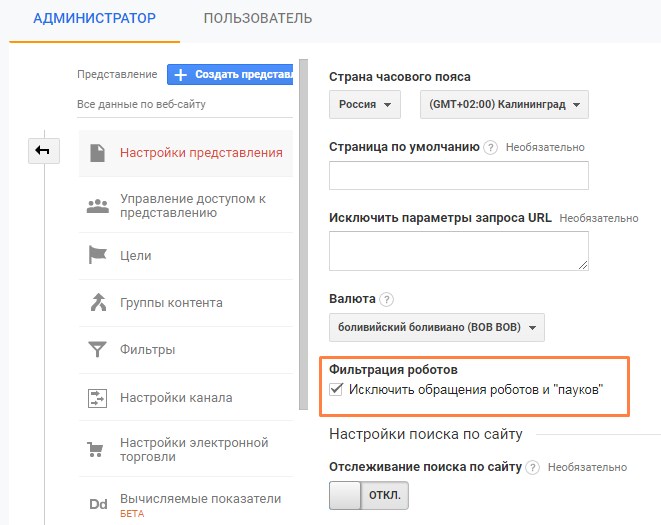 Настройка фильтрации ботов
Настройка фильтрации ботов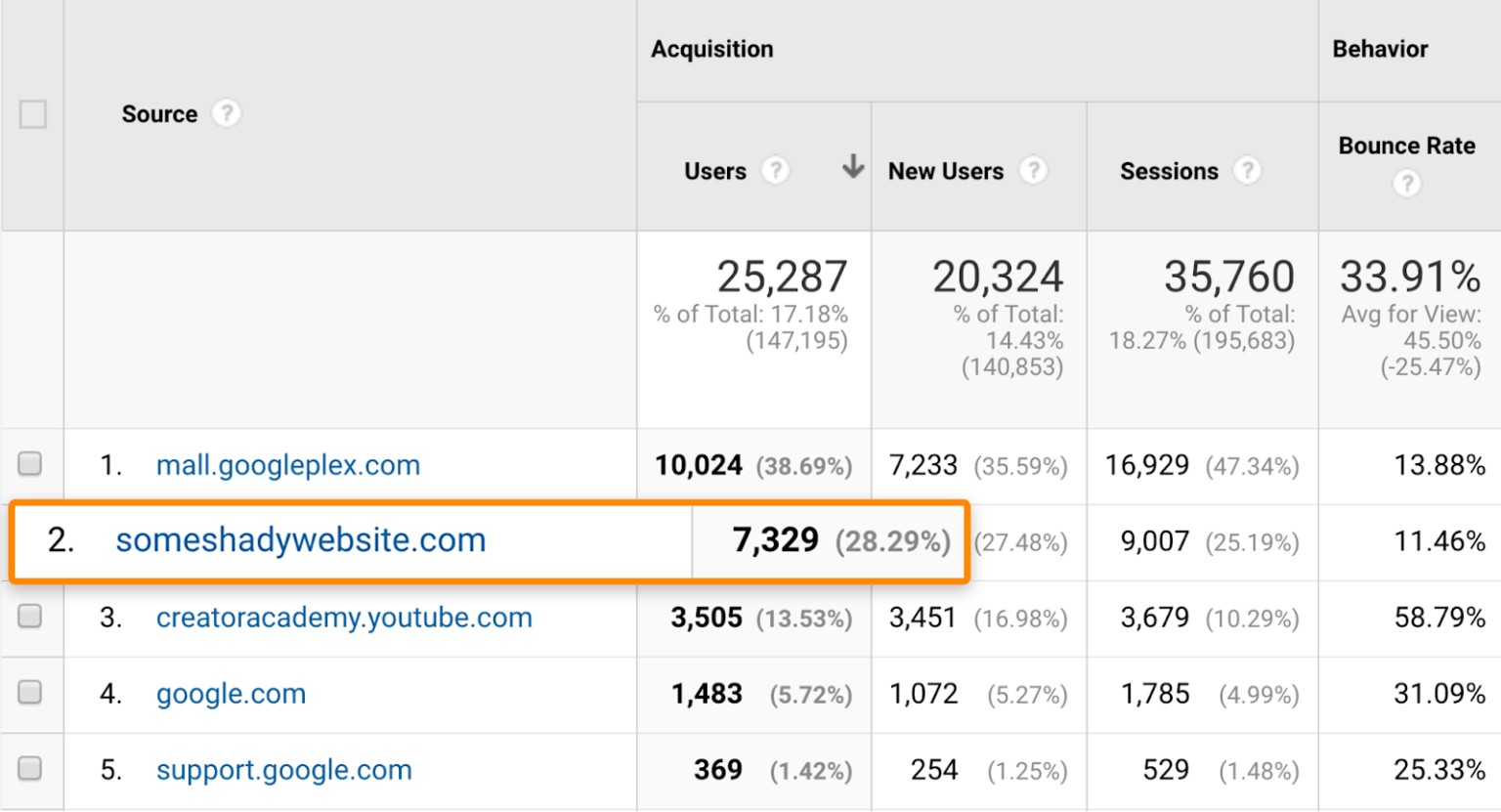 Домены с большим количеством рефералов, скриншот ahrefs.com
Домены с большим количеством рефералов, скриншот ahrefs.com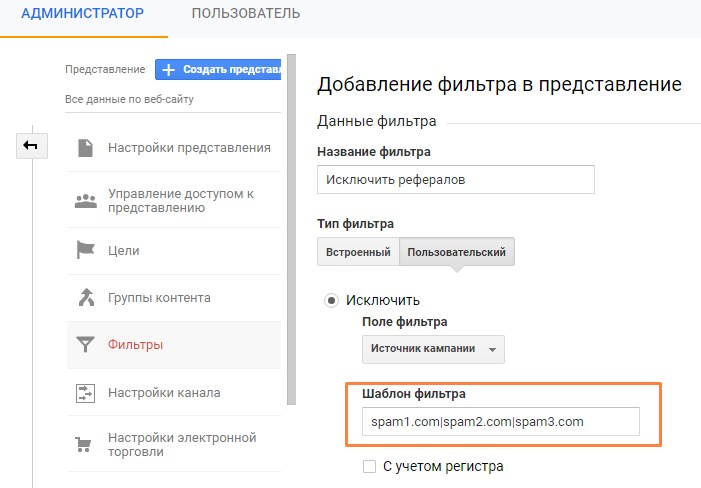 Настройка фильтров
Настройка фильтров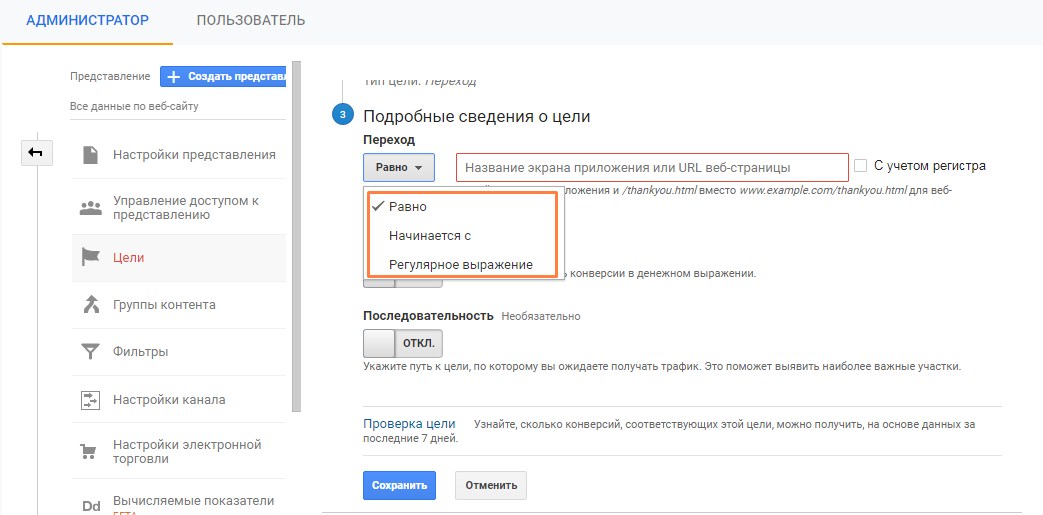 Выбор соответствия цели
Выбор соответствия цели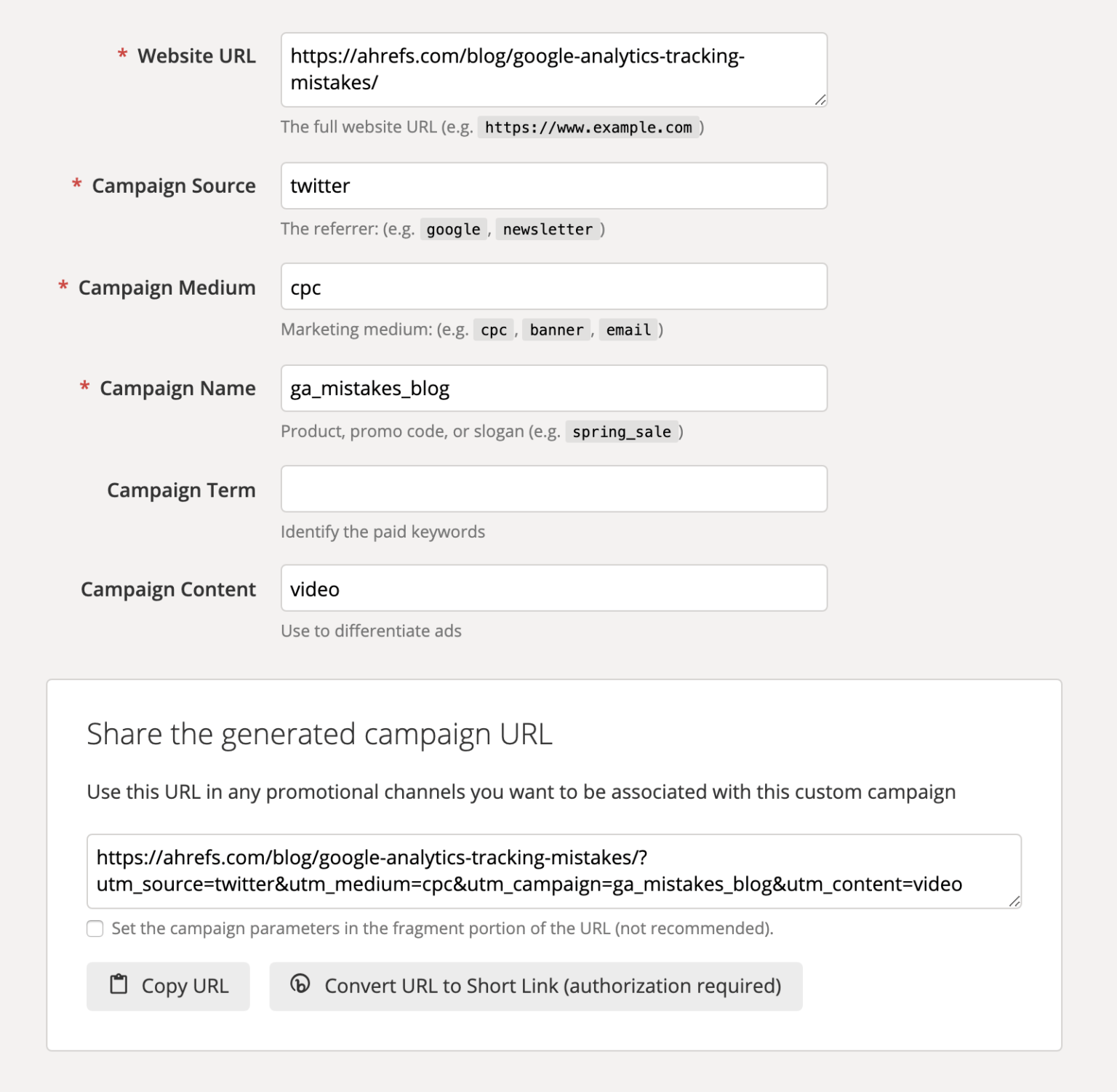 Заполнение UTM-меток
Заполнение UTM-меток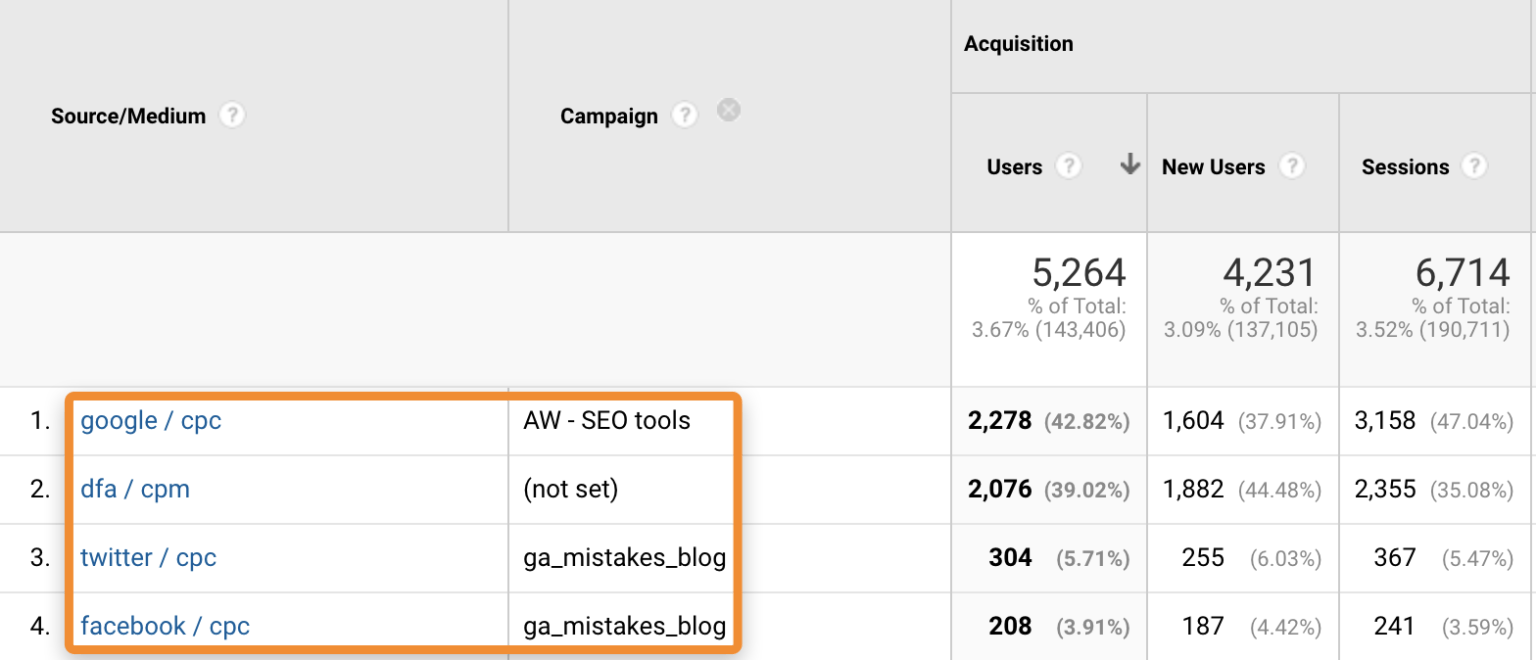 Отслеживание ссылок с UTM
Отслеживание ссылок с UTM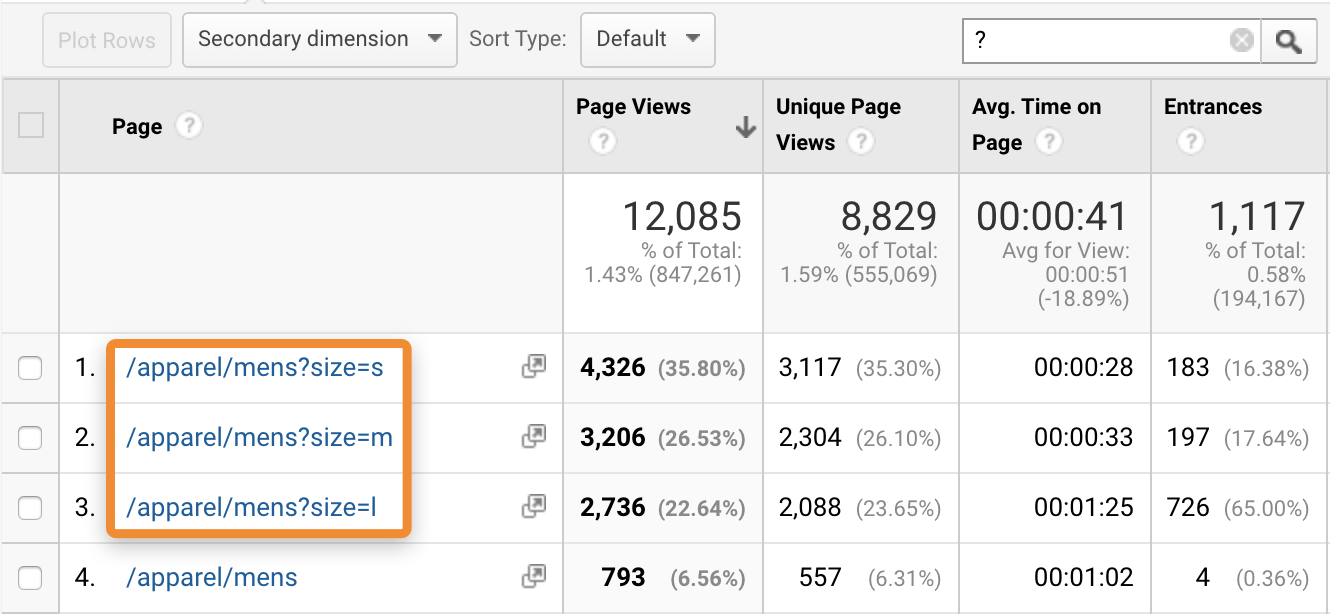 Одна страница и несколько URL с параметрами в Аналитике, скриншот ahrefs.com
Одна страница и несколько URL с параметрами в Аналитике, скриншот ahrefs.com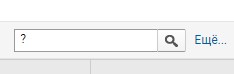 Используйте ? в поиске
Используйте ? в поиске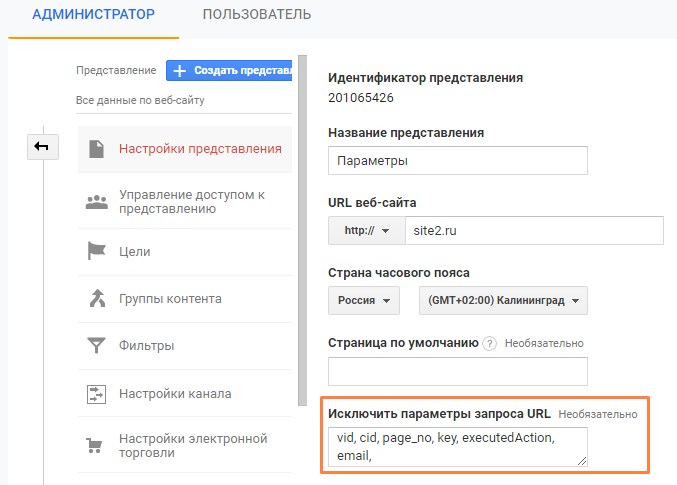 Исключение параметров
Исключение параметров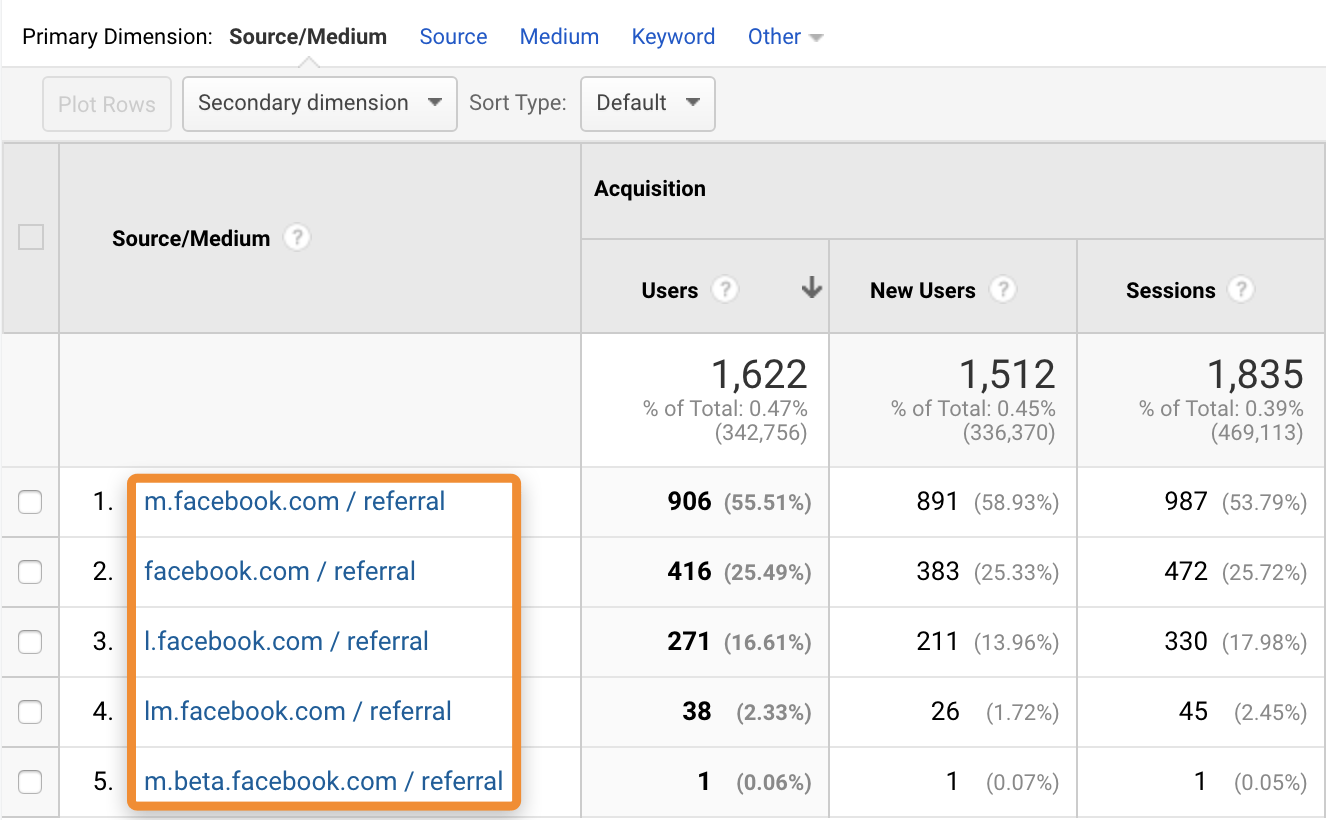 Повторяющиеся источники, скриншот ahrefs.com
Повторяющиеся источники, скриншот ahrefs.com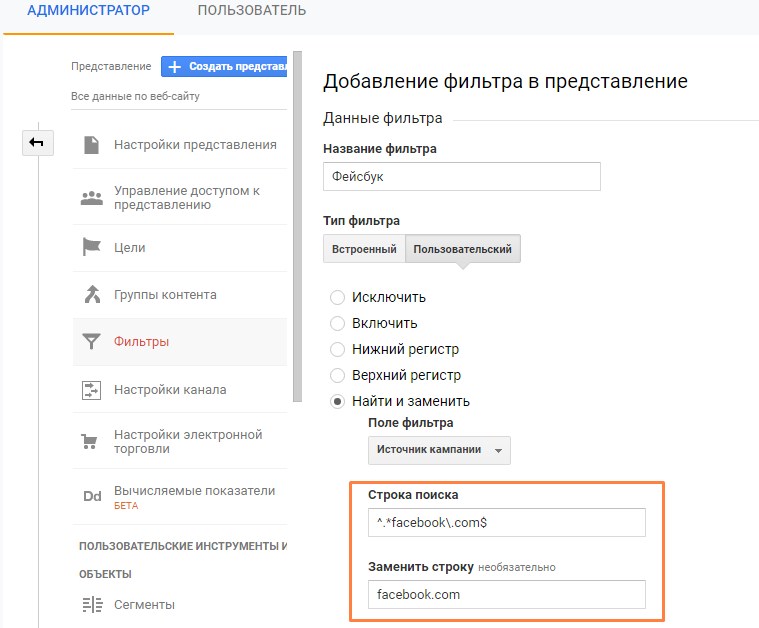 Настройка фильтра
Настройка фильтра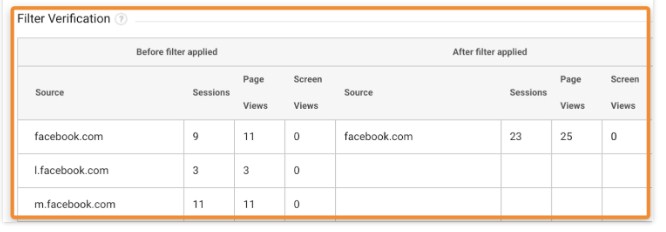 Работа фильтра, скриншот ahrefs.com
Работа фильтра, скриншот ahrefs.com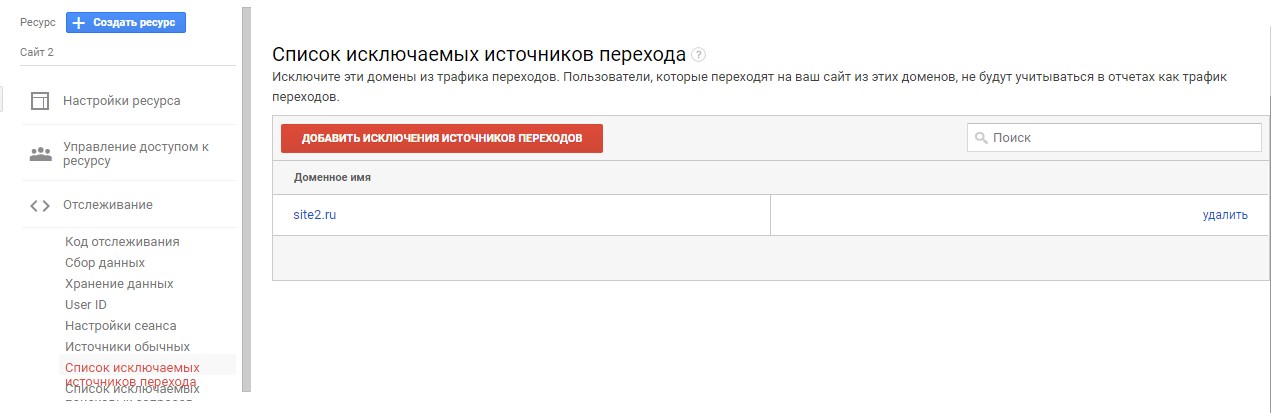 Добавление доменов в исключения
Добавление доменов в исключения