Этот материал не связан с продвижением или технической работой с сайтом. Мы решили иногда разбирать интересные темы из области саморазвития, которые помогли бы веб-мастерам и другим коллегам из сферы SEO работать эффективнее. Если вам нравятся такие материалы, дайте знать в комментариях!
Почитать по теме: Секреты эффективности для тех, кто работает мозгом [Научный подход]
Сегодня на страницах блога PR-CY мы решили поделиться интересным способом вести список дел, который применим к личным и рабочим задачам.
В статье
Вести ежедневник сложнее, чем кажется
Что такое система Bullet journal
Какой блокнот выбрать
Структура ежедневника
Условные обозначения для списка дел
Как вести Bullet journal ежедневник
Содержание
План на год
План на месяц
Ежедневный план
Коллекции
Оформление страниц
Вести Bullet journal ежедневник или нет: плюсы и минусы
Вести ежедневник сложнее, чем кажется
Идея вести ежедневник со списком задач многими воспринимается в штыки: не хочется тратить на это время. Так было и у нашего автора из блога PR-CY, но потом позиция «я и так всё помню» дала сбой. Какие-то дела приходилось откладывать, а потом они забывались. Вечером вместо ощущения продуктивного дня оставалась тревога — всё ли сделано? Что нужно сделать завтра?
В ход пошли стикеры с напоминалками над рабочим столом, но ворохом клейких бумажек не очень удобно пользоваться. К тому же коту стало интересно сдергивать записки, так что «собрать письмо для внеплановой рассылки» и «передать показания счетчика» полетели на пол и были уничтожены.
Нападение на список дел
Обычно в таких случаях советуют вести ежедневник, причем именно от руки, потому что это полезно для мозга. О пользе рукописных заметок говорит медик Ульям Клемм в своей статье «Почему письмо от руки может сделать вас умнее» («Why Writing by Hand Could Make You Smarter»), где он собрал результаты исследований по теме. При письме от руки активируются несколько областей мозга, которые не задействованы во время печати на клавиатуре, мозг развивает ощущение управления движением и мышление. Также исследования показывают, что упражнения в скорописи развивают визуальное распознавание и память.
Записям дел и целей тоже нужна система, чтобы план помогал, а не запутывал. Каждый может придумать для себя удобный способ организации заметок, а мы решили не изобретать велосипед, а попробовать Bullet journal и рассказать о нем читателям.
Что такое система Bullet journal
Систему Bullet Journal или BuJo создал Райдер Кэрролл, дизайнер цифровых продуктов из Нью-Йорка. Проблемы с обучением и концентрацией сподвигли Райдера придумать способ, который помог бы ему сосредоточиться на задачах.
«Вместо того, чтобы вести записи, как другие люди, я выяснил, как организовать и сортировать информацию так, как работает мой разум».
Bullet journal — система организации записей с помощью пунктов и блоков, от английского «bullet» — пуля, пункт. Оформление Bullet journal поможет создать удобную карту целей, оформить список идей и мыслей, вести ежедневник с задачами, составлять подборки.
Какой блокнот выбрать для Bullet journal
Есть специальные размеченные BuJo-ежедневники, но можно взять любой блокнот, которым удобно пользоваться. Будет проще, если он будет с нумерованными страницами.
Размер нужен такой, чтобы вам было удобно носить его с собой, но лучше, чтобы на странице помещалось около 30 строк — по числу дней в месяце. Если планируете брать блокнот с собой и делать пометки в транспорте, выбирайте жесткую обложку.
Сначала разберем, из чего состоит блокнот в системе BuJo, а потом объясним процесс его заполнения на разворотах Bullet journal.
Структура ежедневника
BuJo состоит из связанных модулей:
Индекс — содержание со списком модулей и указанием страниц, где они расположены. Его заполняют по мере ведения.
Планы и цели на год — несколько страниц, обычно разделенных по месяцам.
Ежемесячный журнал — календарь месяца и страница для итогов и планов.
Ежедневник для планов и задач на каждый день, обычно заполняют с вечера или утром.
Коллекции — подборки со списком книг, идей, фильмов, инсайтов.
Ведение BuJo подразумевает тезисное описание задач, чтобы можно было на ходу взглянуть на список и понять, что осталось сделать. Для этого есть система условных обозначений.
Условные обозначения для списка дел
Создатель BuJo придумал значки, которые визуально разделяют пункты:
задачи — точка;
события — кружок;
заметки — тире.
Оформление заметок
Для каждой задачи указывают состояние, знаки подобраны так, чтобы исходное обозначение задачи — точку — можно было бы легко переправить на другой знак;
задачу поставили — точка;
задачу выполнили — зачеркнутая точка;
перенесли в список дел на ближайший день— знак >, похож на стрелку вправо;
отправили в долгосрочные планы в список дел на месяц — знак <, стрелка влево;
добавили приоритетность важной задаче — ! или *.
Оформление статуса задач
Если эти обозначения кажутся вам непривычными или непонятными, придумайте свои. К примеру, как это сделал пользователь @_c.ti_:
Посмотреть эту публикацию в Instagram
Публикация от ⠀⠀⠀⠀⠀⠀⠀Cristina Golovina (@_c.ti_) 29 Мар 2018 в 2:56 PDT
Как вести Bullet journal ежедневник
Посмотрите обучающее видео от автора методики (на английском) или ознакомьтесь с нашими рекомендациями:
Приступаем к оформлению Bullet journal. Рассмотрим каждый из модулей.
Содержание
Первый разворот — это содержание. Здесь вы будете отмечать, на какой странице искать коллекцию, план на нужный месяц или на весь год. Оформили модуль — указали страницы в содержании.
Как выглядит содержание
План на год
Обычно берут два разворота и каждый делят на шесть отсеков — каждому месяцу свой. Как только вы разметили модуль с планами, пронумеруйте страницы и занесите их в содержание.
Разметка планов на год
План на месяц
Следующий разворот — план дел на месяц. Укажите страницы и внесите их в содержание.
Левая страница — календарь, напишите в один столбик числа месяца с указанием дня недели. В строчки подпишите значимые события, привязанные к дате, например, дни рождения или поездки.
Правая страница — список дел, которые вы хотите сделать именно в этом месяце, события, покупки, проекты, встречи и прочее.
Разворот месяца
Ежедневный план
Открываем новый разворот и переходим к планам на конкретный день: записываем все задачи, которые нужно сделать сегодня, события и важные заметки для размышлений.
Визуально разделить события, задачи и заметки помогают условные обозначения — точка, кружок, тире. Задача может состоять из нескольких подпунктов, для них увеличьте отступ от края. К важным задачам добавьте свое обозначение — «!» или «*».
Выполненную задачу отмечаем крестиком. Если задача стала неактуальной, зачеркиваем. Если сегодня не успели что-то выполнить, перенесите задачу на другой день и отметьте знаком > или отправьте ее в план на другой месяц со знаком <.
В идеале не должно остаться ни одной задачи без отметки о ее статусе.
Пример плана с отметками о выполнении
Коллекции
В Bullet journal удобно не только разбираться с планами, но и составлять списки книг, фильмов для будущего просмотра, идей подарков, инсайтов с лекций. Благодаря содержанию список не потеряется, а еще в плане на день можно поставить ссылку на нужную страницу с подборкой фильмов.
Пример страницы со списком
Оформление страниц
Страницы ежедневника можно просто заполнить планами или интересно оформить, как позволит фантазия. Многие любители рисовать выкладывают красочные страницы своих блокнотов в Инстаграм или Пинтерест:
Посмотреть эту публикацию в Instagram
Публикация от Лиза, твой любимый блогер (@lisa.summerland) 23 Ноя 2019 в 2:27 PST
Система Bullet journal — вести ежедневник или нет?
Такой способ заполнять ежедневник на первый взгляд кажется сложным из-за количества страниц с планами. Отмечать выполненное, переносить задачи из списка на следующий месяц, вычеркивать неактуальное — это все требует внимания и времени.
С другой стороны, ориентироваться в структурированной информации всегда проще, чем в хаосе заметок. Такой ежедневник позволяет контролировать шаги на пути к мечте, не пропускать важные события, формировать конкретные планы, отслеживать собственную продуктивность и расставлять приоритеты в задачах.
Мы советуем попробовать оформить ежедневник в системе Bullet journal. К структуризации задач нужно привыкнуть, тогда она перестанет казаться сложной. Во время ведения журнала станет понятно, как усовершенствовать систему под себя и сделать ее еще удобнее.
Bullet journal — один из способов организовать учет задач в ежедневнике. Вы пробовали этот метод? Расскажите, как отслеживаете планы вы?
Другого мнения придерживаются некоторые вебмастера. Так, владелица кулинарного блога Ребекка Айзенберг недавно получила в Google Search Console уведомление о необходимости добавления на страницы с рецептами разметки для подсчета калорий. Сообщение от Google, по словам Ребекки, выглядело весьма категорично:
«Добавьте подсчет калорий на свои карточки с рецептами или вы рискуете выпасть из результатов поиска!»
Me: *Trying to create a food blog that doesn’t participate in diet culture.*
Google: Enable calorie counts on your recipe cards or risk not appearing in search results! pic.twitter.com/XQVKo4ofXC
— Rebecca Eisenberg (@ryeisenberg) January 15, 2020
Испугавшись, блогерша сделала вывод – отказ от добавления таких структурированных данных может привести к потере позиций в Google SERP.
Твит веб-мастера получил небывалый резонанс в кругу SEO-специалистов. Опасения докатились и до Google, как итог Дэнни Салливан выступил с опровержением:
«Накануне сообщество сеошников было введено в заблуждение. Дескать, без разметки для калорий страницы с рецептами будут ранжироваться ниже или вообще выпадут из индекса Google. Это не соответствует действительности. Скажу больше, такого рода структурированные данные не влияют на позиции ресурса в результатах поиска.
Владельцы контента могут использовать структурированные данные в качестве дополнительной опции, которая улучшит вид их страниц. С такой разметкой страницы, которые и без нее хорошо ранжируются, станут более привлекательными для потенциальных посетителей».
Напоследок эксперт Google пообещал, что его коллеги поработают над тем, чтобы текст уведомлений в Панели веб-мастера впредь звучал более нейтрально, не вызывал таких переживаний и ошибочных предположений.
Как Google определяет рейтинг компании в локальном поиске
Как улучшить карточку компании в Google Мой бизнес: советы и примеры
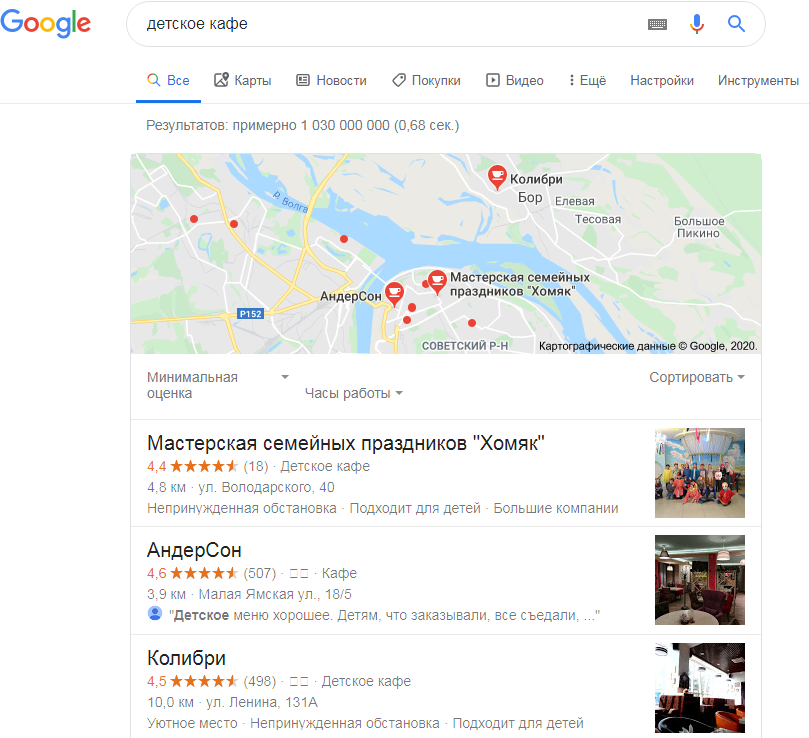
Google Мой бизнес (Google My Business, GMB)— сервис с информацией о компаниях, которая появляется в Google Поиске и на Картах в локальной выдаче. Пользователи получают интересующие их данные о магазинах и заведениях, а компании — преимущество в локальном поиске и еще один канал для трафика на сайт и клиентов.
Список компаний в выдаче
Список компаний на карте
Профиль компании нельзя создать для бренда, персоны или интернет-магазина, бизнес должен контактировать с клиентами на физической точке, если это доставка, то должна быть зона обслуживания. Правила описаны на странице Помощи.
Зарегистрировать карточку компании в Google Мой бизнес бесплатно и несложно. Разберем, как конкурировать в сервисе с другими компаниями и на что важно обратить внимание при заполнении карточки.
Так ли нужен профиль компании в Google Мой бизнес
В официальной презентации представителя Google была информация о том, что 46% всех поисков в Google имеют «локальное намерение». То есть пользователи ищут компании по геоположению, рядом с собой или в нужном им районе. Об этом написал Ник Уилсдон в своем Твиттер-аккаунте.
По данным RankRanger, 29% результатов поисковой выдачи Google содержат локальные результаты.
Скриншот статистики RankRanger
Если пользователь ищет компанию, привязанную к геоположению, наверняка он будет смотреть на карту и выбирать по информации из карточки на Google Мой бизнес.
«Исследование факторов ранжирования локального поиска» Moz от 2018 года говорит, что профиль в Google My Business — главный фактор, влияющий на ранжирование компании на картах.
Даже если вы не регистрировали свою компанию в Google Мой бизнес и не заполняли карточку компании, информация о ней может появиться в сервисе от других пользователей. Там могут быть ошибки, устаревшие данные, а негативные отзывы останутся без ответа представителей бизнеса. Лучше взять карточку под свой контроль.
Часто владельцы бизнеса регистрируют компанию в сервисе и больше не возвращаются к профилю. Это неправильно: система Google Мой бизнес — дополнительный канал общения с аудиторией, нужно периодически заглядывать в аккаунт, отвечать на отзывы и вопросы, поддерживать актуальность данных и выкладывать сообщения об акциях.
Как Google определяет рейтинг компании в локальном поиске
Хоть пользователь и фильтрует компании по геоположению, все равно между несколькими карточками бизнеса есть конкуренция. При ранжировании карточек компаний Google обращает внимание на три фактора:
Релевантность — соответствие карточки запросу пользователя. С брендовыми запросами все понятно, но если пользователь ищет просто «кофейню», «массаж» или «магазин сантехники», карточка должна отвечать запросу.
Известность — показатель связан с репутацией и популярностью компании. Google анализирует это по количеству статей и ссылок о компании, записей в каталогах, отзывов пользователей, позиций сайта компании в поисковике. Еще влияет общая популярность объекта — достопримечательности, знаковые места, известные музеи будут в приоритете.
Расстояние — в локальных запросах важно, насколько близко заведение к пользователю, так что выдача может различаться вплоть до километра.
О том, как добавить компанию в Google My Business, мы писали в статье «Список сервисов Google для бизнеса: где регистрировать сайт компании?»
Есть параметры, на которые невозможно повлиять, но работать над сайтом, известностью бренда и оптимизацией карточки в Google Мой бизнес веб-мастеру под силу.
Как улучшить карточку компании в Google Мой бизнес: советы и примеры
Разберем, что нужно не забыть при оформлении карточки. Все ограничения по заполнению есть в Справке Google.
Еще не открылись? Регистрируйтесь заранее!
По возможности компанию стоит зарегистрировать в сервисе еще до ее открытия, чтобы как можно больше будущих клиентов увидели карточку и узнали, что вы скоро откроетесь.
Дату открытия указывают при редактировании сведений.
Указать дату открытия компании
Зарегистрировать компанию можно не раньше, чем за год до открытия. Но для пользователей карточка откроется за 90 дней до предполагаемой даты начала работы. За это время вы успеете продумать описание, выбрать фото и заполнить данные во всех подробностях.
Укажите все подходящие категории
Есть одна основная категория бизнеса и можно выбрать несколько вспомогательных. От категорий зависит, по каким запросам будет ранжироваться компания, так что внимательно посмотрите предложенные и подберите максимально подходящие, по которым вас будут искать клиенты.
Выбор категорий
Не стоит указывать сторонние категории в надежде охватить больше аудитории: это снизит релевантность показов вашей карточки, а значит ухудшит поведенческие показатели. Если вы косметология, не ставьте «спа-салон» основной категорией, но если у вас есть и услуги спа, добавьте эту категорию в дополнительные.
Проверьте совпадение всех контактов
Везде, где вы регистрируете компанию, указывайте номера телефонов и адреса. Это дополнительный способ получить клиентов и сигнал для Google. Обычно такая бизнес-информация встречается на сайте, в тематических каталогах, в профилях отзовиков и на карточке в GMB.
Для Google важно предоставить пользователям точные данные, поэтому он сверяет контакты на разных площадках. Плохой знак для репутации компании, если они не будут совпадать — возможно, это мошенники.
Эксперты Backlinko считают, что контакты, которые вы указываете на разных площадках, должны не просто быть одинаковыми, а совпадать дословно. К примеру, если вы пишете «проспект», то «пр-кт» на другом сайте может запутать поисковик. Мы не можем проверить эти данные, но сообщаем вам, что такое мнение есть.
Если вы давно ведете бизнес, меняли адреса регистрировали компанию на многих площадках и уже не уверены, что контакты и адреса совпадают, лучше найти эти данные и проверить.
Заведите табличку с адресами сайтов, где указывали контакты. Если вы, к примеру, закроете филиал или переедете, то сможете быстро найти площадки, где нужно отредактировать информацию. Если вы уже меняли контакты или адреса своего бизнеса, придется проверить все ресурсы, где упоминается компания, и обновить информацию.
Укажите название и ориентиры для филиалов
По правилам Google Мой бизнес в названии может быть только само название компании без преимуществ, слоганов и категорий. Не «Лучшее в городе кафе “Огонек”» или «Комфортабельная гостиница “Sleep”», а названия «Огонек» и «Sleep».
Если у вашей компании несколько филиалов, в их названиях можно обозначить ориентиры. К примеру, добавить географическую привязку, чтобы пользователям было проще найти нужный филиал.
Есть гостиницы «Людмила» по другим адресам
На примере указали локацию, но не добавили название салона и нигде не написали, чем они занимаются. В итоге по карточке компании непонятно, что это за салон.
Салон без названия
Кейсы по теме: Как переезд компании в новый офис повлиял на локальное ранжирование [2 кейса]
Можно ли добавить ключи в название в Google Мой бизнес
По правилам площадки нельзя, в рекомендациях Google есть такая фраза: «Включение ненужной информации в название вашей компании недопустимо и может привести к приостановке вашего размещения».
Но, как выяснила команда SterlingSky, ключевые слова в названии сильно влияют на позицию в локальной выдаче. Исследователи провели тест: создали профиль компании в Google My Business и добавили «салат-бар» к названию. Эта компания нигде не упоминалась в интернете и сайта у нее не было. Несколько дней спустя они удалили ключевые слова из названия, а через неделю снова добавили. Что происходило с ранжированием для поискового запроса «салат-бар [город] [штат]»:
График локального ранжирования
В другом случае для карточки адвоката удаление ключевых слов оказало такое влияние:
Эксперимент с ключевыми словами в названии карточки
SterlingSky не призывает нарушать правила Google и напротив советует жаловаться на конкурентов, которые преступают правила и используют ключи. Так они предлагают делать локальную выдачу удобной для пользователей и конкурентной для бизнеса. Мы тоже не станем советовать нарушать правила, действуйте на свой страх и риск.
Не забудьте про описание для компании. Доступно всего 750 символов, так что лаконично перечислите, чем компания может быть полезна. Сосредоточьтесь на том, что волнует ваших клиентов, и сформулируйте это проще. Не забудьте про ключевики для повышения релевантности карточки.
Покажите, как к вам добраться
Некоторые компании сложно найти: нет яркой вывески, вход в офис расположен со двора или в здании есть несколько входов, в которых все путаются. Если вход в ваше заведение не очевиден, лучше подробно объяснить, как к вам попасть.
Есть два способа:
сфотографировать часть улицы, чтобы было понятно, где находится вход;
использовать функцию «Просмотр улиц», чтобы пользователь мог виртуально походить по улице на найти вход на карте.
«Просмотр улиц»: вход в парикмахерскую
Если ваша компания может похвастаться красивым интерьером, вы можете заказать у специалистов виртуальный тур, чтобы пользователь мог понять, что его ждет внутри.
Виртуальный тур по магазину Купцов Елисеевых
Создание виртуального тура нужно заказывать у специалистов, у Google есть база фотографов, которые работают с Google Мой бизнес. Они имеют статус «доверенных проверяющих», поэтому могут ускорить подтверждение компании на Картах.
Залейте больше красочных фотографий
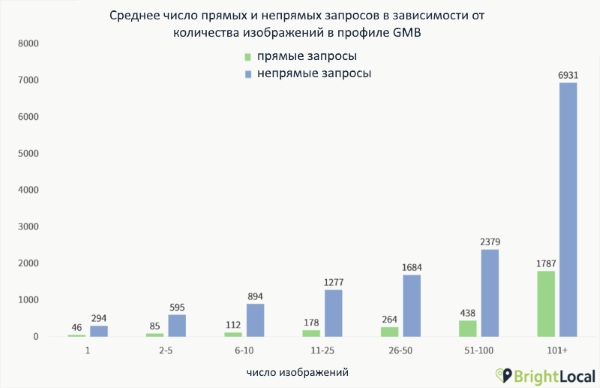
Исследование компании BrightLocal показывает, что количество фотографий в профиле Google Мой бизнес коррелирует с ранжированием компании в поиске. Если у компании больше сотни изображений, у нее на 960% больше поисковых запросов, и в Google.Maps ее смотрят на 3459% чаще.
Корреляцию обнаружили и с количеством целевых действий. Больше сотни фото — на 250% больше звонков и на 1065% больше кликов на сайт, чем другие компании в среднем.
Если у компании одна фотография в профиле, у нее на 71% звонков и 65% кликов меньше, чем у остальных в среднем.
Это не значит, что если вы добавите сто картинок, звонки и переходы увеличатся. Возможно, большое количество фото действительно влияет на целевые действия и показы, а может быть эти данные означают, что крупные компании с хорошими позициями выкладывают больше фото.
Тем не менее, фотографии однозначно полезны, ведь они помогают клиенту составить впечатление и определиться с выбором. Для фото на карточке компании есть несколько альбомов, они различаются в зависимости от категории. У кафе будут альбомы с фотографиями блюд, у гостиницы фото номеров.
Заполнение альбомов в сервисе
Кроме того, нужно загрузить логотип и обложку для карточки компании. Выберите самую красочную фотографию для обложки, чтобы она привлекала внимание и выглядела красиво, но и сообщала что-то полезное — показывала интерьер, блюдо, ассортимент или вход в офис, если его сложно найти.
Обложка показывает интерьер ресторана
Загруженные фотографии в альбомах будут под описанием и контактами. Учтите, что обложки довольно маленькие, так что подберите контрастные фото с крупными планами, на которых понятно, что происходит на фото.
Альбомы на карточке компании
В альбоме фотографии открываются крупно, на весь экран, поэтому выбирайте контрастные изображения в хорошем качестве. Желательно подобрать их по стилю и цветовой гамме, чтобы создать единое настроение, и по размеру, чтобы слева в слайдере они все ровно уместились. На примере фото с трубочками вертикальное, а с тарелкой горизонтальное, поэтому вертикальное не помещается и выглядит очень крупно.
Фотографии в альбоме
Видео убедительнее фотографии: можно показать процессы и звуки, быстро провести пользователя по помещениям, рассказать что-то приятным голосом. Если у вас есть презентационный видеоролик, который покажет, как уютно в вашей гостинице, салоне или кафе, какой большой ассортимент в вашем магазине или как весело в вашем музее наук, загрузите его в альбом с видео.
Обновляйте информацию
Когда в компании меняется что-то, что касается работы с клиентами, нужно сразу отражать это на карточке компании: изменился телефон, компания переехала, поменяли время работы, переделали меню, перестал работать Wi-Fi, убрали террасу и остальное, что влияет на получение услуг.
Если клиент изучил информацию в профиле, сформировал определенные ожидания, настроился закрыть какую-то задачу или хорошо провести вечер, а в итоге ожидания не оправдались, он вряд ли придет еще раз и скорее всего напишет плохой отзыв.
Следите за отзывами
Отзывы о компании отражают ее популярность и качество услуг, так что они влияют на ранжирование и рейтинг компании, а как следствие на количество клиентов.
Исследование факторов ранжирования от Moz также показало, что отзывы — третий по важности фактор, влияющий на локальное ранжирование.
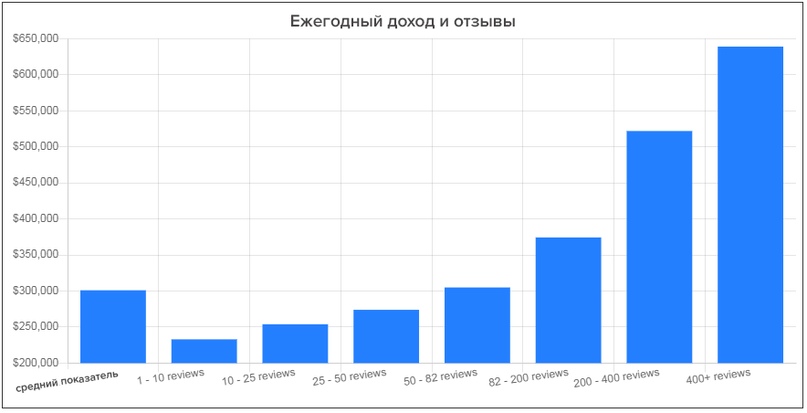
Все исследования о ранжировании в Google Мой бизнес и отзывах, которые мы встречали, говорили о том, что отзывов должно быть много. К примеру, исследование компании Womply «Как отзывы в интернете влияют на доход малого бизнеса» с выборкой 200 000 малых бизнесов разных отраслей показало интересные корреляции.
Если у компании от 82 отзывов, ее годовой доход выше среднего на 54%, при этом важно, чтобы постоянно появлялись новые отзывы.
Это корреляция, не исключено, что у крупных компаний много клиентов и как следствие много отзывов. Тем не менее, такое наблюдение есть и множество хороших отзывов никому не вредило.
Касательно оптимального рейтинга компании в GMB мы придерживаемся мнения, что идеальные оценки выглядят подозрительно — нельзя нравиться абсолютно всем. Сплошь восторженные отзывы наводят на мысль, что они покупные, а раз компания покупает отзывы, ей нельзя доверять.
Нейтральные и негативные отзывы тоже нужны, но нельзя оставлять их без внимания. О работе с негативом и пользе отрицательных комментариев мы писали отдельный большой материал.
Почитать по теме: «Зачем нужны отрицательные отзывы и как работать с негативом в комментариях»
Даже на положительные отзывы лучше отвечать, чтобы поблагодарить, показать свою заинтересованность и показать другим пользователям, что компании важно то, что пишут ее клиенты. Причем отвечать нужно быстро, так что придется следить за появлением новых отзывов, чтобы успевать реагировать.
Ответы от имени компании
Пользователи охотнее оставляют отзыв, если чем-то недовольны, тогда у них есть потребность высказаться и пристыдить компанию. Для хороших отзывов компании приходится напоминать клиентам оставить отзыв, придумывать активности или предлагать за это бонусы.
Чтобы клиент мог написать комментарий, ему нужно искать страницу компании, а это лишние действия. Веб-мастер может отправить ему ссылку для отзыва, тем самым упростить этот процесс и повысить вероятность, что клиент отзыв все-таки оставит.
Как получить ссылку для отзыва
Перейдите на эту страницу, введите название компании и найдите ее на карте. У компании появится Place ID.
Place ID на карте
Скопируйте это значение и добавьте в конец ссылки https://search.google.com/local/writereview?placeid=
К примеру, ссылка для барбершопа GANG выглядит так — https://search.google.com/local/writereview?placeid=ChIJIV6M7rPVUUER7cH26prerHA
Если перейти по этой ссылке, откроется окно для отзыва и оценки:
Форма для оценки и отзыва о компании
Регулярно проверяйте вопросы
Кроме отзывов, у пользователей есть возможность задать вопросы и получить на них ответы от представителей бизнеса или других пользователей.
По нашим наблюдениям, компании редко отвечают на такие вопросы, а зря — пользователи спрашивают что-то важное, что касается будущих заказов или их прошлого опыта сотрудничества. К примеру, ребенок забыл в кафе игрушку и родители спрашивали, не находил ли ее персонал. Если бы они нашли игрушку и связались с родителями или выразили сожаление, что не нашли, наверняка бы получили больше расположения от клиентов.
Ответ владельца кафе
Компании нужно отслеживать появление вопросов и отвечать на них, иначе на вопрос может ответить кто-то из пользователей, и ответ может быть не в вашу пользу.
Заполните профиль по-максимуму
По мере добавления информации Google отображает, какой процент данных вы уже заполнили. Это показатель того, что вы стремитесь дать пользователям полную информацию и закрыть как можно больше их вопросов, а заботу о клиентах Google ценит.
Процент заполнения информации
Проверьте все графы и заполните то, что пропустили. Даже если пункт кажется вам неважным, для клиентов наличие террасы или пандуса может стать решающим фактором при выборе. К примеру, клиент торопится и ищет кафе, где есть детское меню: у вас есть отметка о нем, у конкурентов нет, а звонить и узнавать у него нет времени — вероятнее, он выберет вас. Или клиент на машине выбирает гостиницу и ему обязательно нужна парковка.
Дополнительная информация на карточке гостиницы
Советы для карточки компании в сервисах Яндекса есть в статье «Как оптимизировать карточку компании в Яндекс.Справочнике и на Яндекс.Картах»
По каким принципам вы выбираете магазин, кафе или другую компанию, когда смотрите выдачу на карте?
Рубрика «Спроси PR-CY» дает пользователям возможность задать вопросы приглашенным экспертам по оптимизации, продвижению, контекстной рекламе и другим смежным областям. Всю неделю после анонса мы собираем вопросы, которые потом передаем эксперту в работу. Ответы выкладываем в отдельном большом посте.
На вопросы выпуска Спроси PR-CY#14 ответил
Сергей Кокшаров aka Devaka
SEO-аналитик, консультант, автор Devaka SEO Блог и телеграм-канала @devakatalk.
Эксперт выбрал интересные вопросы, на которые он может ответить развернуто.
Пользователь alff спрашивает:
«Как оптимизировать новостные сайты? Ведь у новостников нет семантического ядра — актуальность статей быстро меняется. Какие ключи прокачивать? И на какие страницы вести ссылки — на страницы рубрик?
Что учитывается в в первую очередь в новостниках — трафик, ПФ, контент, индексация, социальные сигналы? Если есть еще какие-то важные нюансы именно по раскрутке новостных сайтов, на что именно обратить внимание в первую очередь? Буду рад, если подскажете».
При работе с новостными сайтами нужен другой подход. Трафика из органики они получают минимум, а основной идет из новостных агрегаторов, а также из новостной карусели в поиске, из Яндекс.Дзена и Google-Дискавери. Здесь важны авторитет издания, количество редакторов, количество публикаций, длина новостей и наличие в ней фактов. Важно быть первоисточником новости и иметь цитирование из других новостников.
Здесь не будут работать обычные SEO стратегии — работа с семантикой и ссылками, например. Разве что самый минимум. Причины вы описали сами. Оптимизатор может лишь обеспечить оптимальное взаимодействие сайта с агрегаторами и писать инструкции для редакторов. На тему продвижения новостников есть ряд статей и кейсов, рекомендую поискать. А также детально ознакомиться с рекомендациями и хелпом поисковых систем.
Для Яндекс.Новостей: https://yandex.ru/support/news/
Для Google Новостей: https://support.google.com/news/publisher-center/?hl=ru#topic=9603441
Почитать по теме: Подробно о продвижении новостных сайтов
Пользователь ricoberd спрашивает:
«Как отслеживать позиции запросов у ИМ с большим семантическим ядром (десятки и сотни тысяч запросов)? Стоит ли этим вообще заниматься или для крупных проектов стоит смотреть на совсем другие метрики? Спасибо!»
Хороший вопрос. Для крупных интернет-магазинов и агрегаторов обычно не отслеживают позиции по большому ядру. А выбирают наиболее приоритетные запросы, чтобы понимать основную картину. Но если есть ресурсы, то компании разрабатывают инструменты для оценки видимости разделов. Более популярные метрики здесь это поисковый трафик по разделам, количество ключевых слов, по которым есть видимость и/или трафик.
Тут смотря что вы хотите понять с помощью анализа метрик. Можно также подключать бизнес-метрики, такие как звонки, продажи и прочие.
Пользователь wtf322 спрашивает:
«Может ли новостной сайт (статейник) занимать топ-10 позиции, если техническое SEO в условном идеале, а регулярность статей хромает, то есть у конкурентов (топ1) пять статей в день, а у меня на сайте одна в день или через день. Конечно, если получить хоть какой-то трафик, то в будущем можно поднимать регулярность публикаций. Интересует именно старт сайта».
Новостной сайт и статейник — это разные проекты, требующие разного подхода к продвижению. Скорее всего у вас просто информационный проект. Если у конкурентов статей в 5 раз больше, то у них и в 5 раз больше точек входа, а значит, скорей всего, в 5 раз больше трафика. Но конечно, ваш сайт может занимать топ-10 по каким-то запросам.
Почитать по теме: «Лучшие статьи о контентной стратегии. Знания, основанные на исследованиях»
Пользователь alastor73 спрашивает:
«Правда, что Google любит ссылки? Предположим, что есть сайт (5 лет с момента запуска) , есть вч запрос в топе Яндекса (информационный запрос ), но в Google сайт на второй странице. Помогут ли ссылки продвинуть этот запрос в топ Google? И не навредят ли ссылки на позиции в Яндексе? Цель — топ 3 в Яндекс и Google».
Все любят ссылки 🙂 И Яндекс тоже. Без запроса и сайта что-то порекомендовать сложно. Посмотрите, кто вас обгоняет в Google и попробуйте оценить, за счет чего они выше? Что они делают лучше? Просто сравнение позиций Яндекс-Google ни о чем не говорит. Обратите также внимание на последние апдейты Google. Там идет большой акцент на E-A-T факторы для информационных проектов, особенно если они как-то связаны с финансами, медициной или бесконечными советами от ноунеймов по улучшению качества жизни.
Пользователь vvcc спрашивает:
«Где брать хорошие ссылки? Как двигать сеть сайтов с минимальными затратами?»
Универсального рецепта тут нет. Нужно больше фигачить и больше вкладывать. Минимально потратиться не получится.
«При переносе веса сайта на молодой только что проиндексированный домен какая будет потеря, если технически все ок?»
«Технически все ок» — имеется в виду, что поисковик уже считает сайты зеркалами? В таком случае никаких потерь «веса» не будет.
Пользователь Амурский Огород спрашивает:
«Можете подсказать по монетизации блогов, какие новые методы есть? Не использую контекст, баннеры и пуши. Только рефссылки и прямую рекламу. Как еще можно заработать на качественном блоге?».
По монетизации, к сожалению, ничего подсказать не могу. Не занимаюсь этим. Может, предоставлять платные услуги своим посетителям или на базе своего блога сделать платный сервис.
Статья из блога PR-CY: 3 способа монетизировать сайт с минимальным количеством посетителей
«Что делать с блогом, который признан аффилированным? Как его по-хорошему переделать и достойно монетизировать?»
Если основной источник трафика на вашем блоге — поисковый трафик, то у меня для вас плохие новости. Диверсифицируйте источники трафика. Создавайте комьюнити. Повышайте экспертность.
Пользователь khomitch спрашивает:
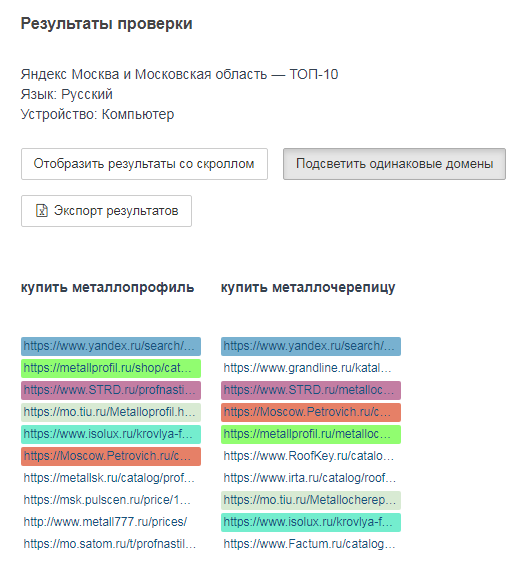
«Стоит ли в подзаголовки страницы (h2/h3/h4) добавлять в прямом вхождении ключевые запросы, релевантные странице, по которым мы также хотим быть в поиске в топ. Например: h1 — Металлочерепица Металлпрофиль, h2 — Формы волны металлочерепицы Металлпрофиль, h2 — Цвета металлочерепицы Металлпрофиль. Не будет ли это восприниматься как переспам?»
Это будет восприниматься как переспам. Используйте естественные конструкции фраз, тем более в заголовках. Также проверьте выдачу по запросам, которые вы хотите объединить на странице. Возможно, они несовместимы.
«купить металлочерепицу» и «купить металлопрофиль» — совсем разная выдача.
Вот хороший инструмент: arsenkin.ru/tools/check-top.
Или попробуйте инструмент от PR-CY — АнализТОП выдачи по ключам, он показывает список сайтов, занимающих топ 10, 20, 50 или 100 по каждому заданному запросу. Параметры проверки: две поисковые системы, регионы, язык, мобильная и десктопная выдачи.
Пользователь Mr_Smith спрашивает:
«Можете назвать 10-15 инструментов, без которых не представляете себе работу seo-специалиста? По возможности бесплатных или условно-бесплатных :)»
Из бесплатных инструментов могу порекомендовать только букмарклеты и различные скрипты, решающие узкие задачи. А если вам нужен более глубокий анализ каких-либо данных (ссылок, контента, конкурентов, …), то даже не знаю, что посоветовать. В любом случае на инструменты придется нормально тратиться. Тут из списка можете выбрать, какие вам подходят — devaka.ru/articles/best-seo-tools
Пользователь Ken спрашивает:
«Есть онлайн сервис на домене .РФ. в России уже давно в топе. Есть желание развиваться на запад. Понятное дело, что с РФ доменом там делать нечего. Если сделать англоязычную версию сайта на домене .com и ссылаться на нее с .РФ сайта, как на англоязычную версию, не будет ли санкций на .РФ сайт со стороны Яндекса или Google? Если нет, то можно ли на сайте .com использовать другой дизайн для сайта или стоит сайт .com отдельно развивать? Заранее спасибо за ответ!»
Если на разных доменах вы планируете разместить разные языковые версии сайта, то за это никто не дает санкций. Настройте на проектах тег hreflang и поисковики будут понимать, что .рф это русскоязычная версия и .com анлоязычная и показывать в поиске для каждого пользователя соответствующую версию. Дизайн при этом вы можете делать, какой посчитаете нужным.
Пользователь klovackdesign спрашивает:
«Какие доноры для размещения статей с линками лучше всего подойдут для сайта онлайн-справочника предприятий? Конкуренты, СМИ..? Как поступить, если локальные городские доноры все с относительно плохими показателями по трасту и спаму, разместить все же там или лучше рассмотреть СМИ, порталы?»
Использовать статьи в данном случае, как по мне, не очень хорошая идея. Обменивайтесь ссылками и трафиком с партнерами, покупайте медийную рекламу, ищите те площадки, где размещение ссылки на ваш сайт будет полезно и ожидаемо для той аудитории.
Пользователь Xitparad Uz спрашивает:
«Мой сайт https://kinogo.uz месяц назад получил штраф от Яндекса (причина — платные подписки без согласия подписчиков), и уже неделя как штраф снят. Сайт уже потерял много позиций в поиске Яндекса. Месяц назад было так: я загружаю какую-то новость на сайт и она сразу попадает в поиск и даже в топ. А после штрафа не так. Сайт получил +10 икс, но бесполезно. Что делать?»
Писать в техподдержку Яндекса, попросить у них рекомендаций. Ну и, занимаясь киносайтами, будьте готовы к разным исходам ситуации. У вас же нет авторских прав на показ фильмов?
«Как оптимизировать и продвигать музыкальный сайт в поиске?»
Анализируйте другие музыкальные сайты, в том числе в других странах. Перенимайте увиденные стратегии.
Алекс Косс спрашивает:
«Дают ли что-нибудь ссылки с профилей на форумах?»
Уже далеко не так, как раньше. Чаще даже дают минус, чем плюс.
Вопросы из соцсетей
Максим Мирошник спрашивает:
«Сколько оперативной памяти нужно в ПК SEO-специалиста для комфортной работы с проектами средней величины?
От топовых seo слышал, что 64 гига им мало, и при переходе на более новые платформы косо смотрят на 128, рассчитывая, что обновляться стоит сразу с запасом на 256, чтобы парсинг не останавливался неожиданно на самом важном месте, упершись в лимит памяти. Если SMM-специалисту нужно не менее 32 гиг оперативы, то сколько нужно SEO-специалисту для проектов средней величины?»
Хороший вопрос) Никогда об этом не задумывался. Но это мне напомнило пожелания жены к характеристикам своего телефона: сколько бы там не было памяти, фотки все равно не помещаются 🙂 Кстати, на моем компьютере 8 гб оперативки. Если с него какую-то задачу не могу выполнить, то использую онлайн-сервисы.
Edyan Nekrasov спрашивает:
«Где брать трафик? С Google у меня примерно 20% трафика, а Яндекс срезал из-за последнего алгоритма аж на 50%. Есть ли альтернативные источники? Сайт информационный».
У информационных сайтов сейчас перспективные источники трафика это Яндекс.Дзен и Google Discovery. Еще некоторые создают параллельно видео-проекты на Ютубе, там хороший трафик. Обратите также внимание на email-рассылки и Телеграм-каналы.
«У меня информационник с рубриками Технологии, Спорт, Путешествия, Бизнес, Здоровье, Секс и Отношения. И я хочу публиковать не только статьи, но и новости. Скажите, как лучше сделать: завести отдельную рубрику «новости» и в ней публиковать все новости из разных категорий, от технологий до секса? Или добавлять новости в определенные категории, смешивая их со статьями?»
Непростой вопрос. Вы хотите публиковать новости для получения доп. трафика? Трафика из органики или из новостных агрегаторов? Так как подход к работе с ними будет разный. Самым простым решением будет посмотреть структуру похожих проектов, как делают они.
Пользователь Tesline Services спрашивает:
«Как влияет наличие APM страниц на Яндекс, что нужно сделать, чтоб APM дружил с Яндексом? Сколько не искал внятного ответа, нигде не мог найти, или советы диаметрально противоположные».
Если технически AMP-страницы реализованы верно и чекеры не выдают ошибок, то Яндекс к ним нормально относится и не считает за дубли.
Алексей Дергач спрашивает:
«Как на ваш взгляд лучше разбивать очень похожие фразы на разных страницах сайта на коммерческие и информационные, если они синонимичны, но по факту разные? Например, керамика для облицовки и облицовочная керамика — это две разные страницы, одна — статья другая — страница каталога для покупки. Google их частенько путает в разных запросах SERP и сует не туда, куда нужно — инфостатью в коммерческие запросы, страницу каталога в инфозапросы. С Яндексом ситуация лучше, но не идеальна».
Если вам нужен коммерческий трафик, то работайте только с коммерческим разделом сайта. Не понимаю, зачем вы делаете лишнюю работу.
«Самые актуальные и сложные для веб-мастеров тренды на 2020 год в SEO по вашему мнению? В каком направлении стремиться улучшать свои скиллы (Яндекс/Google)? Спасибо за ответы и удачного вам года!»
Спасибо! Про тренды в этом вебинаре рассказывал, гляньте. Основное, к чему стоит стремиться — повышать авторитет и экспертность сайта, оптимизировать мобильную версию, оптимизировать представление на SERP, оптимизировать страницы под интент, а не под ключевые слова.
Почитать по теме: «Что такое интент запроса: оптимизируем контент под потребности пользователя»
Kom Serg спрашивает:
«Интересна ситуация, когда заголовок H — ссылка. Как на это смотрят ПС?»
Нормально, если речь о разделе.
Andrei Zubrytski спрашивает:
«Зачем SEO-специалистам работать на кого-то, когда они сами могут поднимать свои проекты и жить припеваючи?»
Многие так и делают.
Бонус за самый интересный вопрос
Автор самого интересного вопроса — пользователь Mr_Smith, он получает промокод на месяц тарифа «Профи» в Анализе сайтов! Промокод пришлем вам в личные сообщения.
Мнение редакции PR-CY может не совпадать с мнением приглашенного эксперта
Напомним, до недавних пор отдельные веб-мастера имели в ТОП-10 выдачи Google сразу два упоминания одной и той же страницы. Одно – в блоке с готовым ответом (англ. – featured snippet), другое – чуть ниже среди органических ссылок первой страницы SERP.
От такого дублирования поисковик решил отказаться. Комментирует Дэнни Салливан:
«Если веб-страница попадает в блок с ответом, то в этом случаемы мы больше не будем ее повторять в основных результатах поиска. Такое новшество призвано очистить результаты поиска и помочь пользователям быстрее находить релевантную информацию. Теперь блок с ответом можно считать одним из результатов в ТОП-10 на первой странице выдачи».
If a web page listing is elevated into the featured snippet position, we no longer repeat the listing in the search results. This declutters the results & helps users locate relevant information more easily. Featured snippets count as one of the ten web page listings we show.
— Danny Sullivan (@dannysullivan) January 22, 2020
К этому времени такое обновление запущено по всему миру и касается всех без исключения поисковых запросов.
Впервые о том, что готовые ответы выпадут из органической выдачи, стало известно в ноябре прошлого года.
Однажды с Джоном Мюллером произошел поучительный случай. Сайт последнего тайно атаковали хакеры:
«Как-то раз кто-то взломал мой сайт. После этого он начал ранжироваться и получать трафик по запросам, которые были нужны злоумышленникам. Я обнаружил факт взлома и исправил ситуацию весьма просто. Я банально заменил на атакованных страницах ссылки хакеров своими ссылками. На мой взгляд, решение не самое продуктивное, но его можно взять на вооружение, не правда ли?!»
В комментариях к твиту Джона сеошники благодарят его за подкинутую идею, которая может оказаться весьма полезной:
«А ведь это интересная бизнес-модель… Сперва позволить взломать свой контент, затем подождать, пока злоумышленники оптимизируют его вместо вас, чтобы после прикрыть лавочку и проставить свои ссылки в нужных местах».
Interesting business model… let site get hacked, let them do the SEO for you, then you take it over and replace with your affiliate links.
— Bill Hartzer (@bhartzer) January 22, 2020
Кое-кто из веб-мастеров, по их словам, даже умудрялся временно зарабатывать на этом благодаря возросшему пусть и не целевому трафику.
 Нападение на список дел
Нападение на список дел Оформление заметок
Оформление заметок Оформление статуса задач
Оформление статуса задач Как выглядит содержание
Как выглядит содержание Разметка планов на год
Разметка планов на год Разворот месяца
Разворот месяца Пример плана с отметками о выполнении
Пример плана с отметками о выполнении Пример страницы со списком
Пример страницы со списком

 Список компаний в выдаче
Список компаний в выдаче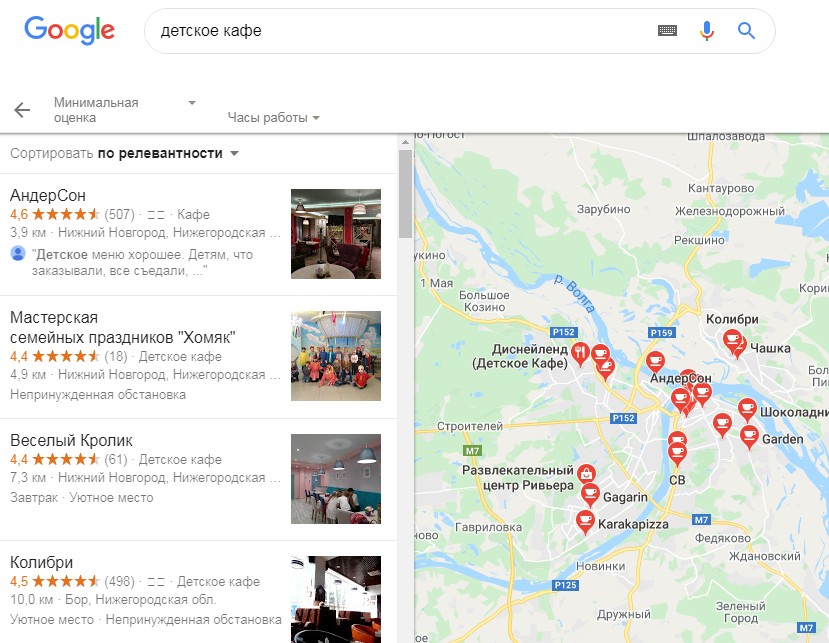 Список компаний на карте
Список компаний на карте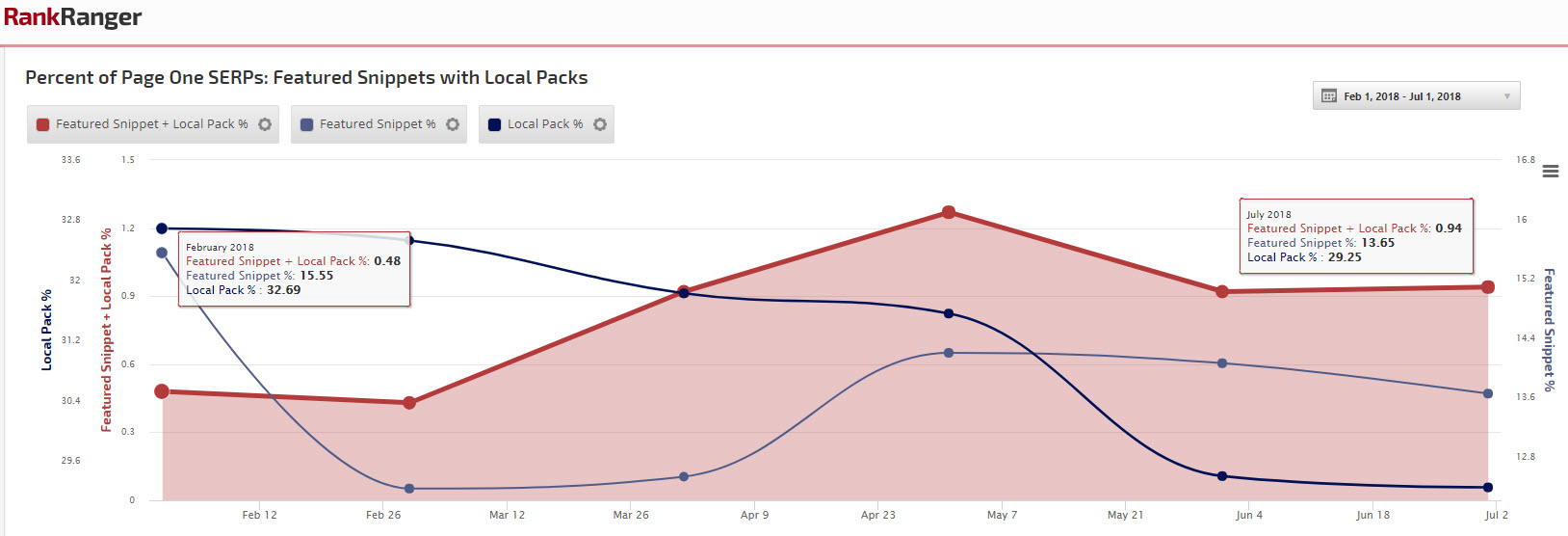 Скриншот статистики RankRanger
Скриншот статистики RankRanger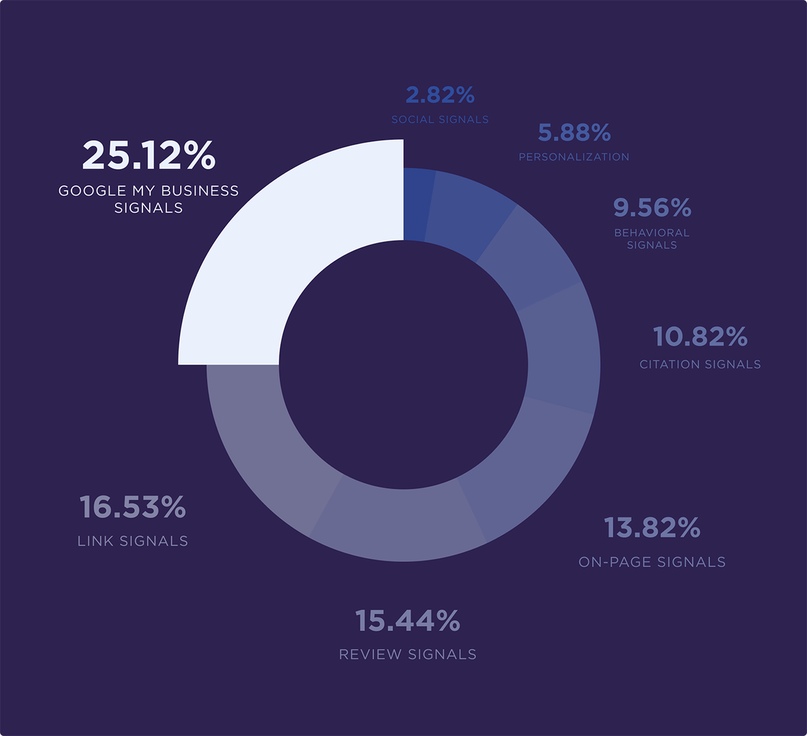
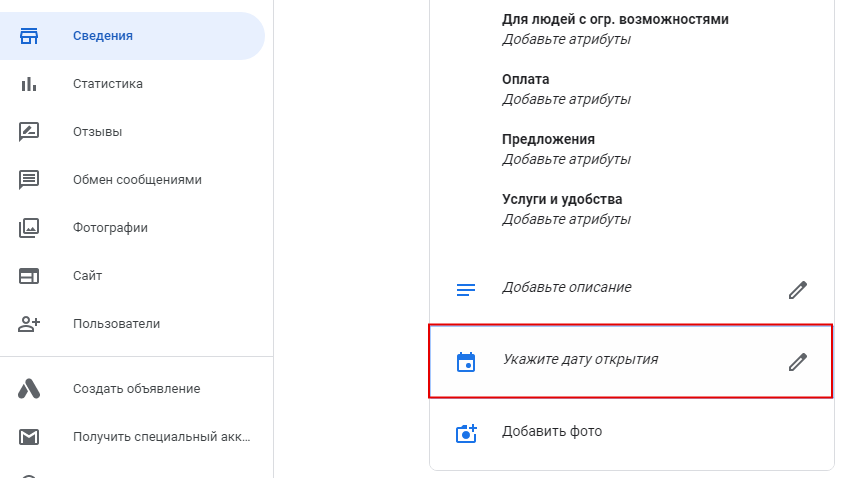 Указать дату открытия компании
Указать дату открытия компании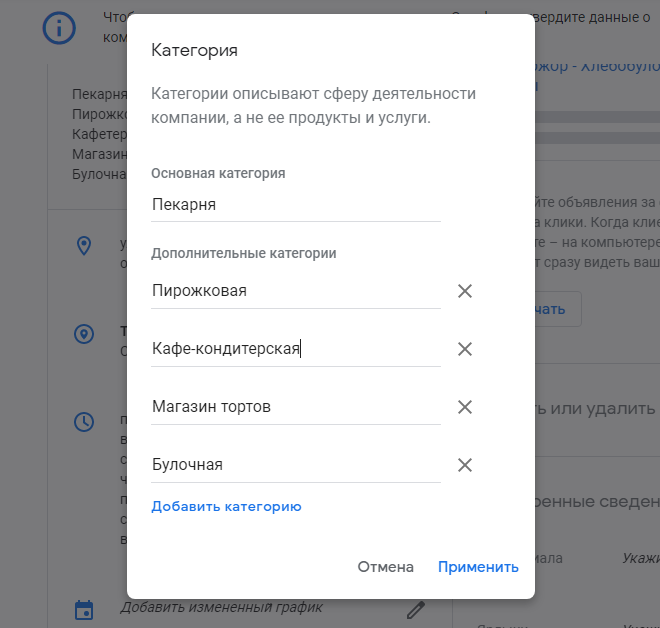 Выбор категорий
Выбор категорий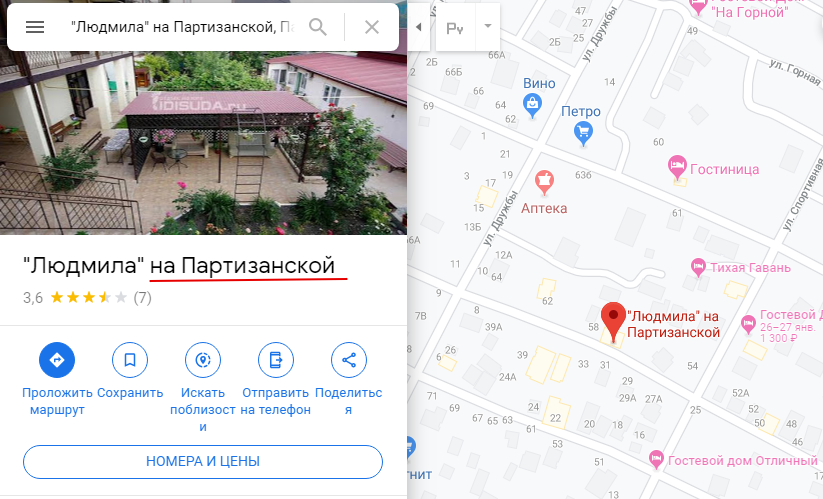 Есть гостиницы «Людмила» по другим адресам
Есть гостиницы «Людмила» по другим адресам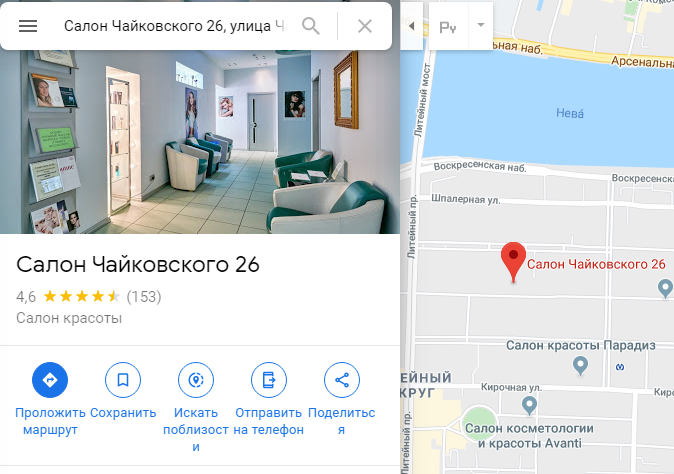 Салон без названия
Салон без названия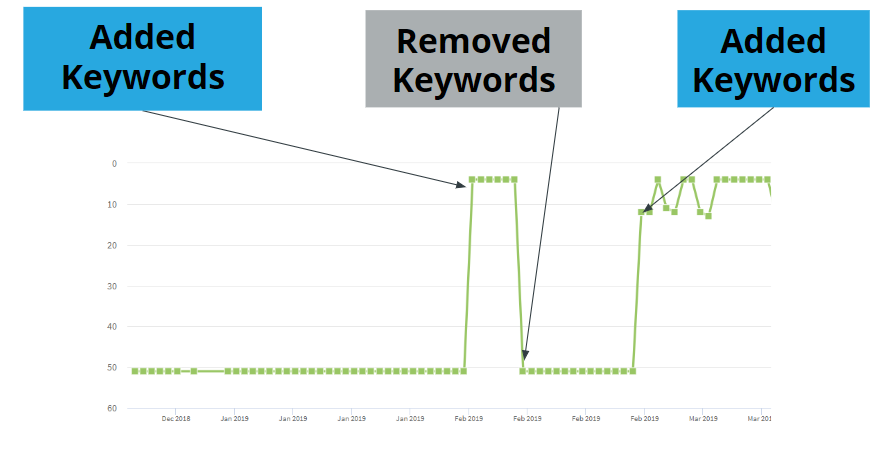 График локального ранжирования
График локального ранжирования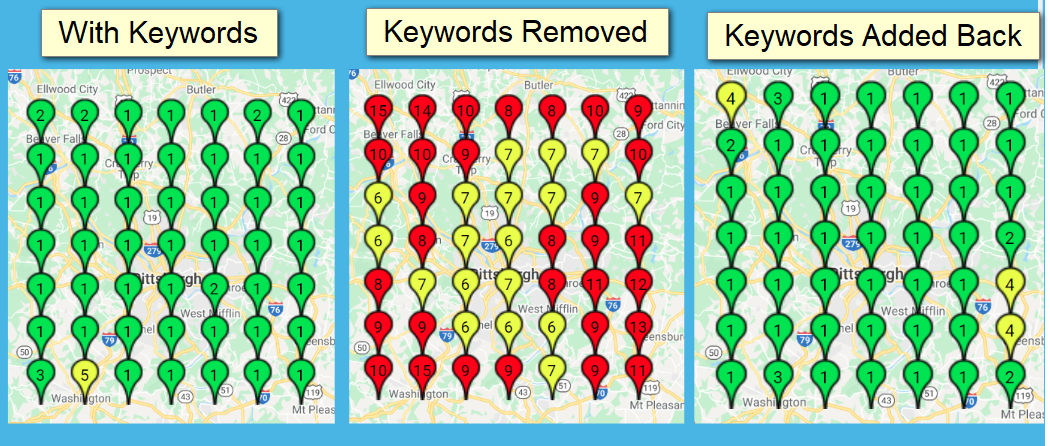 Эксперимент с ключевыми словами в названии карточки
Эксперимент с ключевыми словами в названии карточки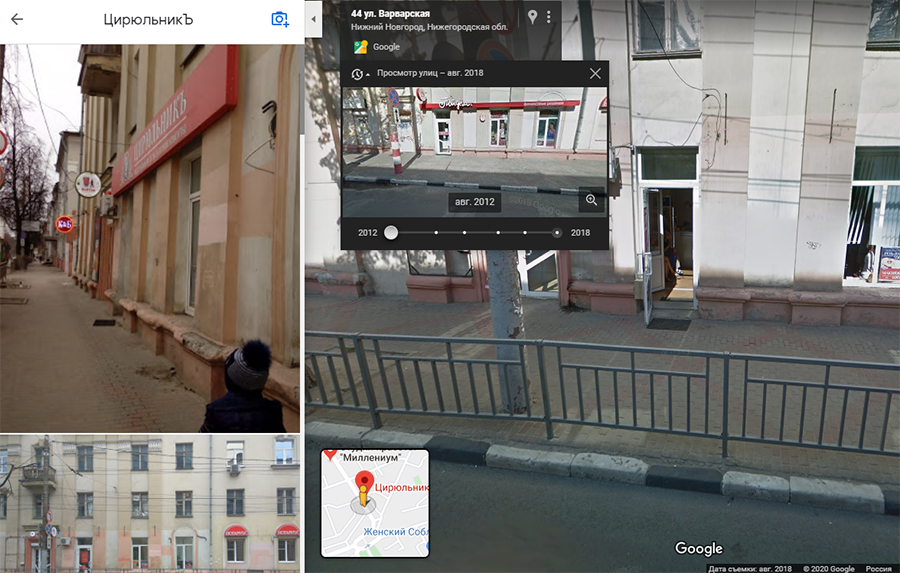 «Просмотр улиц»: вход в парикмахерскую
«Просмотр улиц»: вход в парикмахерскую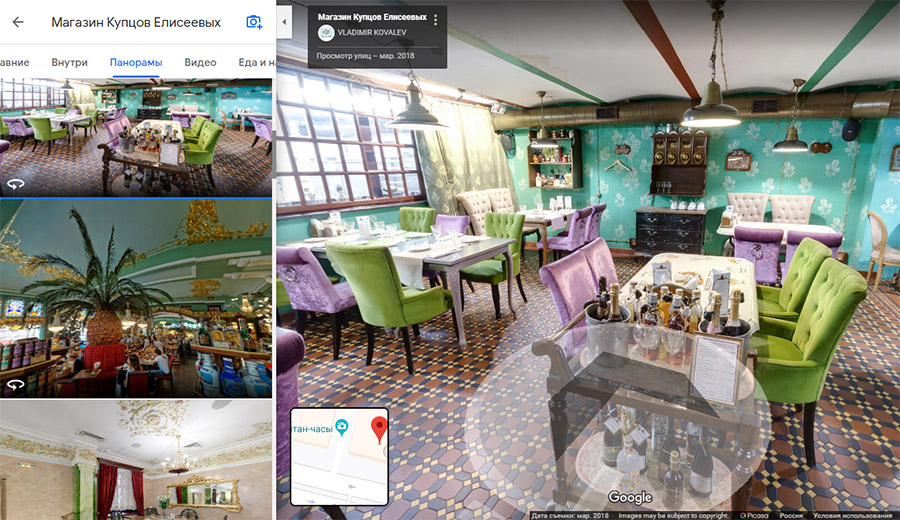 Виртуальный тур по магазину Купцов Елисеевых
Виртуальный тур по магазину Купцов Елисеевых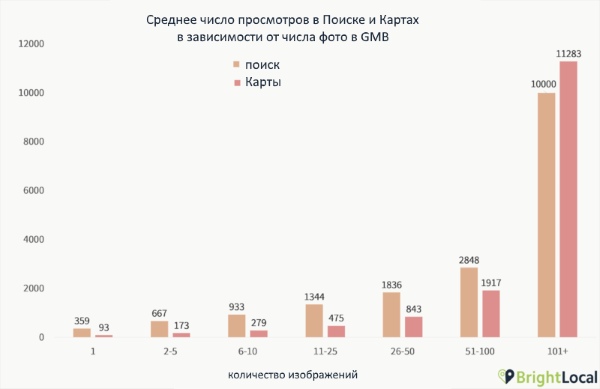
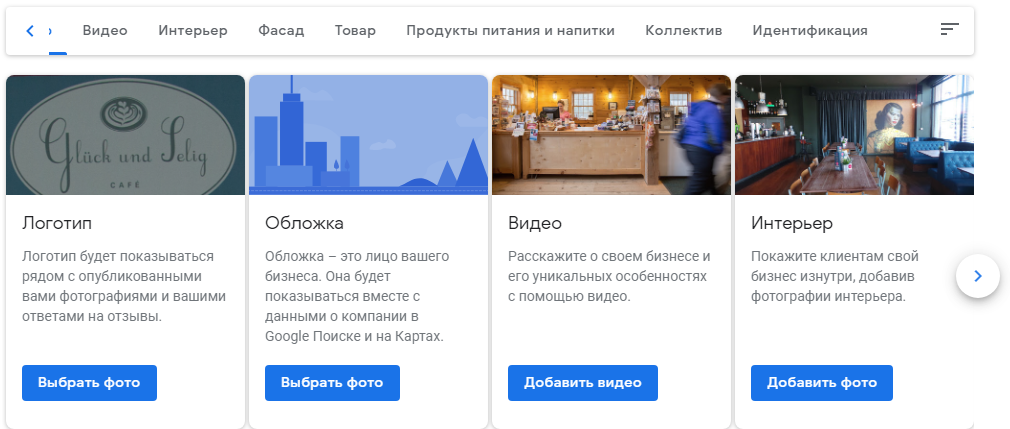 Заполнение альбомов в сервисе
Заполнение альбомов в сервисе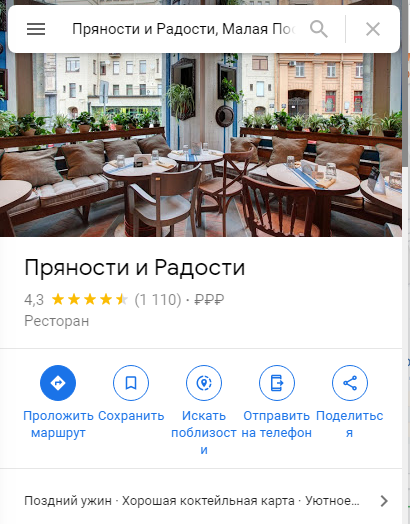 Обложка показывает интерьер ресторана
Обложка показывает интерьер ресторана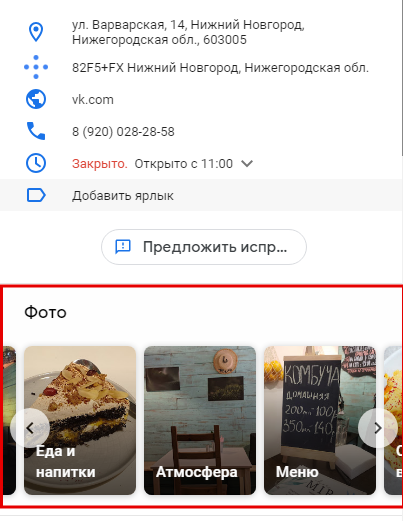 Альбомы на карточке компании
Альбомы на карточке компании Фотографии в альбоме
Фотографии в альбоме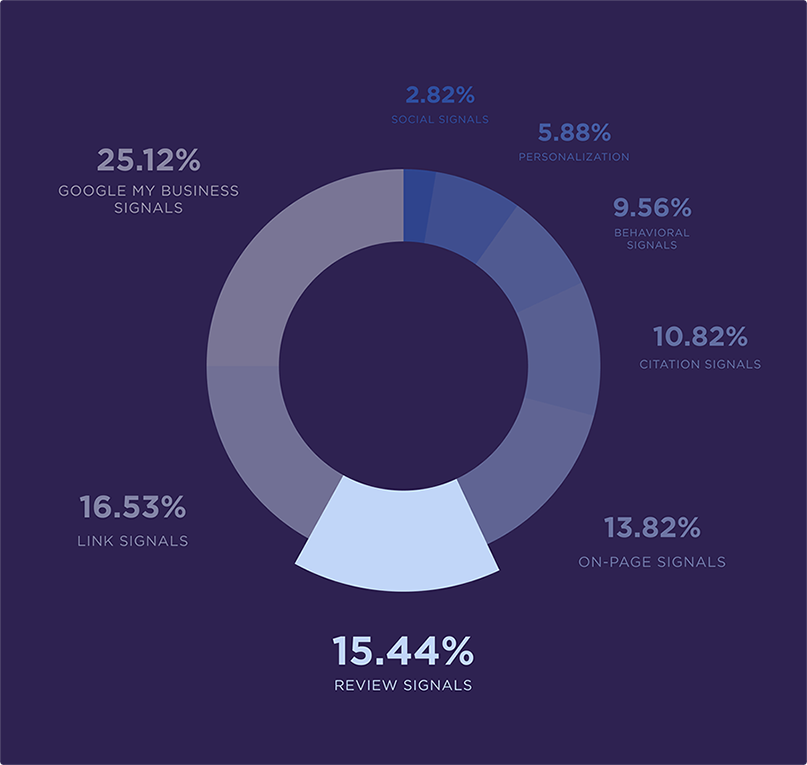
 Ответы от имени компании
Ответы от имени компании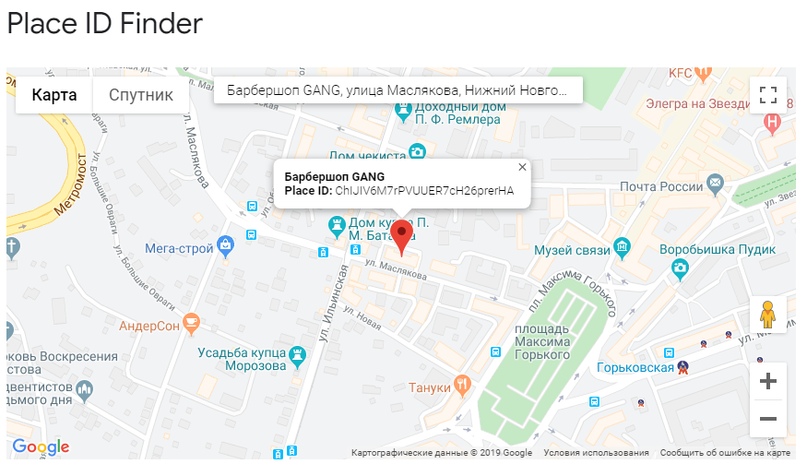 Place ID на карте
Place ID на карте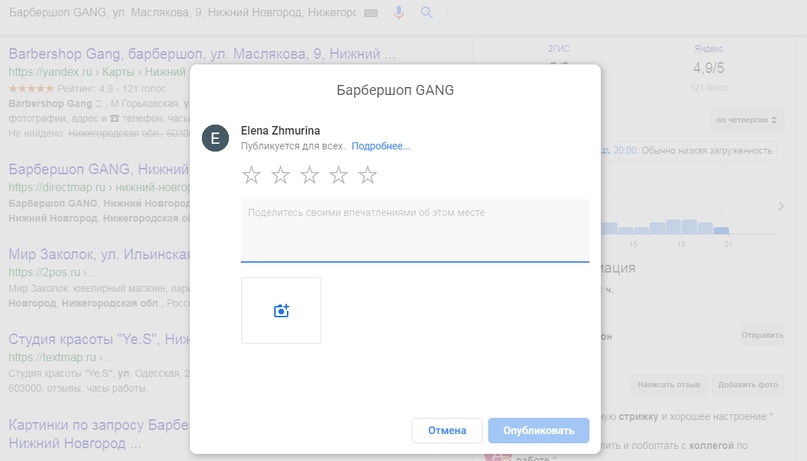 Форма для оценки и отзыва о компании
Форма для оценки и отзыва о компании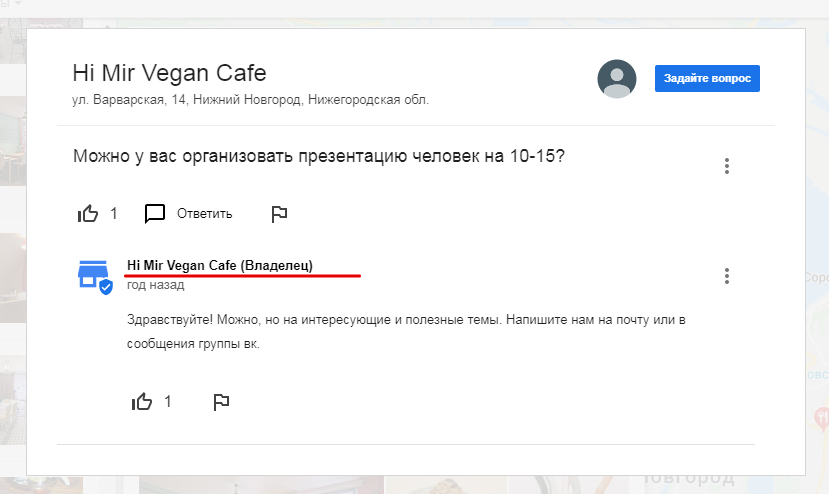 Ответ владельца кафе
Ответ владельца кафе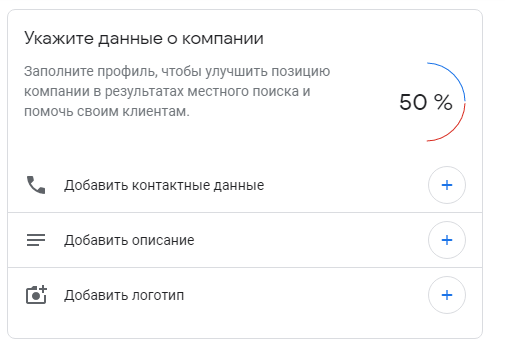 Процент заполнения информации
Процент заполнения информации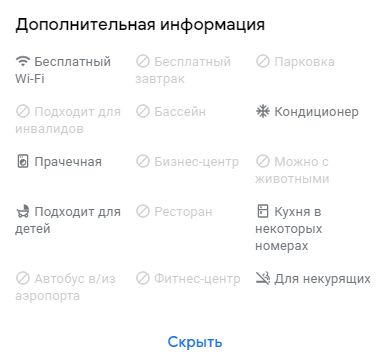 Дополнительная информация на карточке гостиницы
Дополнительная информация на карточке гостиницы