Юридическая консультация по иммиграционным вопросам от компании «PRAVO&STATUS» mmc.msk.ru: когда вам нужна иммиграционная помощь для иностранных граждан и юридическая помощь для работодателей-иммигрантов? Как известно, каждый иностранный гражданин с момента въезда в Российскую Федерацию немедленно подчиняется иммиграционному законодательству, которое строго регулирует пребывание иностранцев в России, устанавливает строгие сроки и правила в стране.
Нарушение иммиграционного законодательства требует от государства наложения санкций в виде штрафов, депортации и даже запрета на въезд в РФ. Однако штрафы за несоблюдение иммиграционного законодательства распространяются не только на иностранных граждан Российской Федерации, но и на работодателей, которые не соблюдают установленные процедуры приема на работу и увольнения иностранцев или не умеют вести кадровый учет. Вот почему многие иностранные граждане и их работодатели в России часто не нуждаются в большой помощи в оформлении документов для иммиграции, но нуждаются в профессиональной юридической помощи для решения иммиграционных проблем, связанных с отсутствием сложного иммиграционного законодательства.
Чтобы понять сложность иммиграционного законодательства, иностранные граждане и их работодатели, нуждающиеся в иммиграционной помощи, обычно обращаются за советом к юристам по иммиграционным вопросам. Это не только помогает предотвратить будущие трудности, но и помогает решить существующие проблемы, связанные с неиммигрантами. -Соблюдать иммиграционное законодательство. Поэтому иммиграционные юристы могут не только помочь решить проблемы иностранных граждан, но и оказать юридическую помощь работодателям-иммигрантам.
Служба иммиграционного адвоката
Услуги иммиграционных юристов и юристов связаны с любыми вопросами и различными этапами урегулирования, включая судебные и исполнительные процедуры. В полномочия правозащитников входят:
Обеспечить соблюдение юридически значимых документов, в том числе претензий и жалоб;
Получить патент;
Снять ограничения на въезд в РФ и отменить высылку;
Содействие в нарушении таможенных правил и условий транзита;
Допросить поведение сотрудников Главного управления внутренних дел Министерства внутренних дел;
Получить статус беженца;
Разрешать административные споры;
Документы трудовых мигрантов;
Сопровождение проверки ФМС;
Законный представитель.
Благодаря помощи юристов по иммиграционному законодательству более 90% дел могут быть завершены без проблем, многие вопросы решаются во внесудебном порядке, а затраты клиента самые низкие.
Каждый час в мире происходят события, которые важны для нас или других, затрагивают наши личные интересы или меняют глобальный мировой порядок. Все это доводится до простых граждан в виде новостей. Медиа-платформы наводнены новостными трансляциями, веб-сайтами и иногда читают ужасные фейки. Обычные люди верят в них и не могут отличить правду от лжи. Поэтому вам нужно только читать официальные источники, которые не будут искажать факты, а спокойно сообщать о событиях и новостях. Одним из таких надежных источников является сайт oqu.news, на котором собраны самые свежие и достоверные Новости Казахстана, Алматы и мира.
Казахстан — Отмена смертной казни В 2003 году Нурсултан Назарбаев объявил мораторий на казни. Недавно Казахстан вошел в число стран-участниц Международного пакта о гражданских и политических правах, направленного на отмену смертной казни, отмену легализации смертной казни. Документ подписал постпред страны при ООН К. Умаров. Соответствующее объяснение дал МИД. Подробнее читайте на сайте oqu.news .
АзияИнфо председатель Таджикистан передал Казахстану председательство в СВМДА, в том числе 27 стран. Главы государств обсудили вопрос взаимодействия стран в период глобальной пандемии и выразили готовность стран-участниц активизировать усилия по укреплению мира, международной безопасности и процветания.
Если будет вторая волна коронавируса, куда пойдет Казахстан? По словам министра труда и социальной защиты, 2,2 миллиона граждан столкнутся с финансовыми трудностями и будут нуждаться в помощи и поддержке государства. Только 4 миллиона рабочих могут сохранить свой график работы, поэтому угроза заработной платы и безработицы превышает 160 тысяч.
Читая новости Алматы, вы не только поймете, что ждет экономическое развитие и что происходит в обществе, но и многое другое. Вы получите информацию об общественной работе, спорте и научных достижениях, а также узнаете о последних погодных условиях. Публикует новости о работе учреждений здравоохранения и образования.
В заголовке «Инцидент» сообщается о дорожно-транспортных происшествиях, стихийных бедствиях и криминальных новостях. В разделе «Экономика» вы найдете самые свежие новости в сфере финансов, инвестиций, бизнес-проектов, стран и мировой экономики, а также ознакомитесь с анализом влияния мировых процессов на нашу экономику.
Отдельный раздел посвящен коронавирусу. Здесь собраны все данные о болезни, последние новости страны и мира.
Прочтите этот полезный ресурс, чтобы узнать о мировой жизни.
Сегодняшнее информационное агентство Tafsilar — это не только новости Узбекистана, но и одно из главных СМИ в Центральной Азии. Наш девиз: «Журналистика — наша профессия». Мы готовим новости из Узбекистана и Средней Азии, а наши корреспонденты всегда в курсе дела. На страницах наших публикаций вы всегда можете найти самые свежие новости во всех сферах жизни в Центральной Азии — политике, экономике, обществе, технологиях, культуре и спорте.
Кроме того, на сайте информационного агентства tafsilar.info вы найдете много другой полезной, действенной и интересной информации. В разделе «Туризм и путешествия» мы публикуем специальные новости из Центральной Азии, в частности знакомящие с туристическим потенциалом Узбекистана и всего региона, освещая последние события в регионе. Название также знакомит читателей с новыми туристическими маршрутами, мировыми тенденциями и мнениями экспертов о развитии туризма в стране и регионе.
В то же время вы можете увидеть и услышать новости из Узбекистана и Центральной Азии на сайте tafsilar.info. Это означает, что помимо графической ленты новостей, сайт также содержит видео-, аудио- и фотоматериалы. В разделе «Библиотека изображений» вы найдете уникальные фотографии Старого Ташкента в Узбекистане с авторскими фотографиями на определенную тему. В специальном разделе «Особые гости» в виде интервью вы узнаете о самых популярных и интересных людях, которые стали столицей или живут в Узбекистане. К ним относятся звезды шоу-бизнеса, актеры театра и кино, политики, дипломаты, ученые, эксперты, бизнесмены, артисты и т. Д.
Кроме того, редакция информационного агентства Podrobno.uz опубликовала мнения независимых экспертов по актуальным вопросам и событиям в мире и странах в специальном разделе «Редакционные мнения». Хочу вовремя быть в курсе новостей об Узбекистане и Средней Азии. Добро пожаловать на сайт информационного агентства Podrobno.uz! Искусственный спутник что-то сказал о молчании других людей. Агентство занимает уникальную рыночную нишу, объединяя альтернативных поставщиков новостного контента и вещателей в одно целое. Tafsilar полностью ориентирован на зарубежную аудиторию. Каждая редакция Tafsilar.info в крупнейшей столице мира имеет свой веб-сайт и ведет передачи из студии местной радиостанции. В 2015 году общее количество часов вещания Sputnik на 30 языках мира превысит 800 часов в день в 130 городах 34 стран мира. Организация имеет собственный мультимедийный новостной центр и выпускает эксклюзивный контент для веб-сайта.
Есть разные новости: международные, события из их родного города, региона или города. Метод получения информации точно такой же. Только он должен быть надежным, проверенным и объективным. Человек, который его слышит, сможет сам решить, что это значит для него лично. То же самое и новости Кыргызстана, и узнать о них можно совершенно по-другому. Какой вариант лучше?
Варианты знакомств в новостях
Неважно, что тот или иной житель Бишкека и Кыргызстана интересуется спортом, политикой или культурой, но всем хочется быть в курсе последних новостей. То, что произошло месяц назад или даже вчера, — это уже история. Завтра может зависеть от того, что произошло сегодня. Хорошие новости очень хорошие.
Вы можете узнавать о новостях через различные СМИ, и это касается не только новостей, публикуемых на бумаге. Предусмотрено несколько вариантов:
Газеты и журналы, на которые вы должны потратить деньги, чтобы купить или подписаться на них; Радио, которое сейчас используется чаще всего, кроме автомобилей; Телевизор, можно не только слушать информацию, но и смотреть видеоклипы; Интернет, который предоставляет множество новостных порталов. Сразу можно сказать, что последний вариант считается наиболее выгодным. Вы можете смотреть телевизор только дома, а газеты обычно издаются государством или определенными политическими партиями. Но новостные порталы могут быть полностью независимыми.
Новостной сайт manas.news считается одним из лучших новостных сайтов Кыргызстана, вы можете убедиться в этом сами. Все, что вам нужно сделать, это зайти на главную страницу manas.news и посмотреть, что там есть.
Среди этих преимуществ можно выделить следующие моменты:
Обеспечьте разные названия; Информация обновляется в течение дня; Доступен в любое время суток; Платить не нужно. Единственное условие — у вас есть устройство для выхода в Интернет. Будь то компьютер, ноутбук или смартфон.
Таким образом, оказывается, что даже если вы путешествуете на общественном транспорте, всегда можно быть в курсе последних новостей. Достаточно использовать свой смартфон и перейти на указанный новостной сайт. Это независимый портал, не принадлежащий какой-либо партии. Это означает только предоставление объективной информации о событиях в своей стране и во всем мире. Не нужно ждать, пока почтальон принесет газету или покажет новостную программу по телевидению ночью.
Соответствующее сообщение появилось сегодня в официальном Твиттере компании:
«Скоростной апдейт основного алгоритма, который позволит учитывать скорость загрузки страницы при ее ранжировании в мобильном поиске, в настоящий момент выкатывается для всех без исключения пользователей».
Больше никаких деталей о начавшемся обновлении поисковая система в этот раз не озвучила. Впрочем, не так давно о них рассказывал Джон Мюллер.
Кроме того, к этому моменту из других источников уже известно, что Google Speed Update:
затронет только самые медленные сайты;
не повлияет на позиции сайтов, которые загружаются быстро;
касается исключительно мобильного поиска.
SEO-сообщество пока никак не комментирует происходящее: как именно уже успел повлиять апдейт алгоритма Google на позиции ресурсов в SERP. Однако многие эксперты отрасли ожидают, что колебания позиций в выдаче могут быть существенными как в одну, так и другую сторону.
А вы уже заметили какие-то изменения в мобильных результатах поиска Google?
Если вы пишете оригинальный и интересный контент, рано или поздно кто-нибудь, позаимствует вашу статью для своего блога. С одной стороны это значит, что вы пишете достаточно хорошо, раз у кого-то возникло желание выдать материал за свой, но с другой стороны это неприятно и может вредить и вашему блогу.
Воровство контента вредит сайту
Когда копируют материал, на который вы тратили время и силы, это прежде всего обидно. Но кроме того, заимствование у вас материала с авторским правом может негативно повлиять и на вашу репутацию, и на позиции сайта.
Вам может быть на руку, если в статье, которую позаимствовали для публикации на другом ресурсе, говорится о вашем продукте, сервисе, компании с положительной тональностью. Если там будет много просмотров, значит больше людей узнает о вас что-то хорошее и кто-то из них обратится к вашей фирме.
Но если это просто полезный обучающий материал, то для вас профита не будет. Пользователи, которые сначала наткнулись на статью на том ресурсе, могут не проверить даты публикации и решить, что это вы воруете контент. Ваша репутация пострадает и авторитет упадет. К тому же, пользователю будет не интересно читать ее второй раз, поэтому открытий и просмотров будет меньше, чем могло бы быть.
Поисковики индексируют материалы набегами, а не по дате выхода, поэтому если вашу статью разместил у себя более крупный ресурс, поисковик может посетить его раньше вас и посчитает его за автора. А если там нет ссылки на вас как на автора, то ваш сайт не получит даже того плюса, что дала бы такая перелинковка.
Рекомендуем периодически отслеживать кражи контента и принимать меры. Разберемся, как это делать.
Сервисы антиплагиата для проверки онлайн
Спустя какое-то время после публикации в своем блоге на сайте или в социальной сети можно посмотреть, где еще появился ваш контент. Мы попробовали проследить, где еще размещена новость с сайта PR-CY.ru от 24.06.18, которую мы перевели из иностранного источника. У нас нет цели обвинить кого-то в краже контента, мы понимаем, что новости — это не авторские статьи, они могут быть написаны довольно похожими фразами.
Отследить ресурсы с похожими текстами можно как вручную, так и специальными сервисами для антиплагиата. Рассмотрим несколько сервисов антиплагиата, которые работают онлайн.
Copyscape
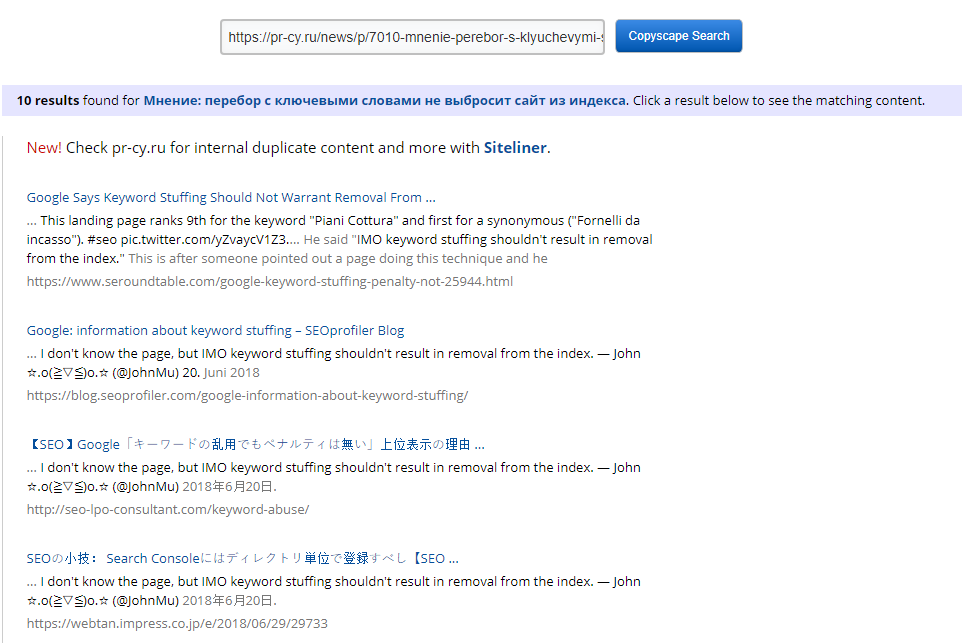
Вводим адрес страницы с контентом в строку. Сервис выводит список сайтов, где эта новость размещена кроме исходного ресурса. В бесплатной версии он анализирует только первые десять результатов поиска, можно купить премиум, если нужен подробный отчет.
Результат проверки
После проверки новости с сайта PR-CY нашлись десять ресурсов, где была размещена эта же новость. Но сервис выдал и японские, и англоязычные сайты, и сайты на русском, где новость о позиции Google была написана другим текстом. Видимо, сервис определяет ресурсы в том числе по совпадающим изображениям и ссылкам, в нашем случае использовались твиты из аккаунтов пользователей.
Удобно, что можно использовать ссылку, а не копировать текст, поиск по изображениям. Неудобно, что бесплатно анализирует только десять результатов выдачи.
Проверка текста на уникальность онлайн от PR-CY
Инструмент проверяет текст на уникальность, его можно использовать как бесплатный сервис антиплагиат.
Вводим текст в поле для анализа, вписываем в игнорируемые домены те ссылки, на которые не нужно обращать внимание, например, если это наш сайт, или мы в курсе, что там размещена статья.
Результаты проверки
Сервис показывает на каких источниках есть этот контент, анализирует текст по фразам и выделяет заимствования, считает их количество у копипастера. Нашлось довольно много ссылок, в списке они идет от большего числа заимствований к меньшему.
Результаты анализа по фразам
Анализ нашел много источников, где публикуется этот контент или фразы из него, то есть можно отследить полный и частичный копипаст или даже поверхностный рерайт.
Удобно, что можно просмотреть фразы, которые были взяты из оригинала, и отследить даже частичные заимствования. Неудобно, что нужно вставлять текст, а не ссылку.
eTXT
Еще сервис для проверки уникальности и антиплагиат. В поле для анализа нужно вставить текст, дальше сервис бесплатно и без регистрации проверит текст до 3000 символов, регистрация позволит загружать статьи до 5000 знаков. Работает онлайн, но можно скачать программу на компьютер или скрипт.
Результаты проверки сервисом в режиме «Обнаружение рерайтинга»
В настройках можно выбрать режим проверки копирайтинга или рерайтинга. В обоих вариантах для новости с PR-CY не нашлись сайты, на которых была бы размещена эта новость в любом виде.
Удобно, что можно выбрать копирайтинг или рерайтинг для отслеживания. Неудобно, что проверка по ссылке не работает, и сервис анализирует тексты до 5000 знаков.
Advego
Сервис для проверки на уникальность. Он работает онлайн, но регистрация на сайте обязательна. Ищет источники рерайтинга и выделит неуникальные фразы. Бесплатно проверит 8559 символов, больше можно докупить за деньги.
Фрагмент анализа со ссылками
После проверки новости нашлось четырнадцать источников, с которыми текст частично совпадает.
Удобно, что определяет процент заимствований и выделяет фразы.
Неудобно, что ограничено бесплатное количество символов и обязательна регистрация.
Content-watch
Сервис ищет сайты, на которых есть анализируемый текст. Можно указать ресурсы, которые можно игнорировать, к примеру, сайты с вашей статьей, о размещении которой вы в курсе. Также он покажет конкретные фразы, которые были взяты из источника, и процент заимствований.
Результаты поиска источников
Нашлось несколько ресурсов с частичным копипастом, также можно посмотреть, какие фразы совпадают.
Удобно, что сервис считает процент совпадений и выводит конкретные фразы. Неудобно, что нельзя искать по ссылке.
Ручной поиск
Можно искать заимствования и копипаст вручную, для этого нужно взять длинную цитату из текста статьи и забить в поисковик. В выдаче появятся ресурсы, которые использовали такую же фразу, а полужирным в сниппете будет выделен искомый фрагмент.
Результаты поиска цитаты из других источников в Google
На первых местах выдачи ссылки на новость с нашего сайта, а дальше появляются ресурсы, которые использовали такую же фразу. Результаты будут немного отличаться, если искомую фразу заключить в кавычки.
Результаты поиска цитаты из других источников в Яндекс
Для поиска в Яндексе пришлось взять фразу в кавычки, иначе в выдаче были ссылки с материалами, не относящимися к новости.
Результаты на первой странице в целом совпадают, порядок выдачи ожидаемо не одинаковый. Метод поиска копипаста рабочий, но так не очень удобно отслеживать полный копипаст, выводятся результаты по одной искомой фразе.
Почитать по теме: Юрист веб-мастеру: советы по авторскому праву и кейсы борьбы с нечестными конкурентами
Куда подать жалобу на плагиат
Если вы обнаружили, что ваша статья появилась на каком-то стороннем ресурсе без ссылки на автора, стоит побороться за свои права и не способствовать плагиату в интернете.
Первым делом стоит написать автору блога и попросить поставить ссылку или удалить материал. Обычно если обращается сам автор и предъявляет свою ссылку, где она выложена первее, плагиаторы выполняют требования. Лучше, если письмо будет написано на официальном бланке компании, если контент взяли из блога фирмы, и будет отражено ваше намерение пойти в суд в случае отказа.
Если плагиатор отказывает или игнорирует, можно повлиять на него другим способом. Обратитесь к хостингу сайта плагиаторов, они следят за материалами, которые размещаются на их серверах. Хостера можно найти через whois.net, нужно ввести адрес сайта и сервис выведет информацию. Нам нужна будет строчка nserver.
Информация о сайте PR-CY
Напишите письмо в хостинг, в нем укажите ссылки на исходный контент и размещенный без соблюдения ваших прав на сайте, который хостится у них. Угрожать им будет бессмысленно, но стоит попросить повлиять на сайт. Зачастую хостеры идут навстречу и блокируют страницы с плагиатом.
Можно обратиться к поисковым системам, чтобы они повлияли на сайты-плагиаторы. Для этого нужно заполнить специальные формы и обратиться в Яндекс или пожаловаться в Google. Поисковики могут понизить плагиатора в выдаче, если будет достаточно оснований. Если Google или Яндекс получат обоснованный запрос о нарушении авторских прав, они понизят страницу с таким контентом в выдаче или даже заблокируют.
Подробнее о методах защиты контента в статье Защищаем авторские права в Яндекс, Google и соцетях.
Когда кто-то присваивает себе ваш контент — это не просто обидно, но еще и может плохо повлиять на репутацию или позиции вашего сайта в поисковой выдаче. С плагиатом стоит бороться и пресекать его на сайтах и в социальных сетях, а сервисы из этой статьи помогут найти сайты, на которых размещены скопированные у вас материалы.






 Результат проверки
Результат проверки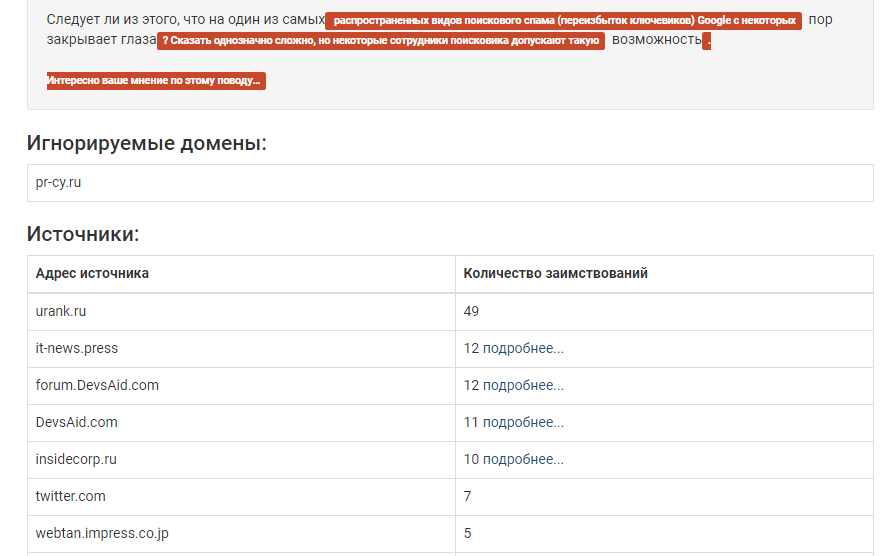 Результаты проверки
Результаты проверки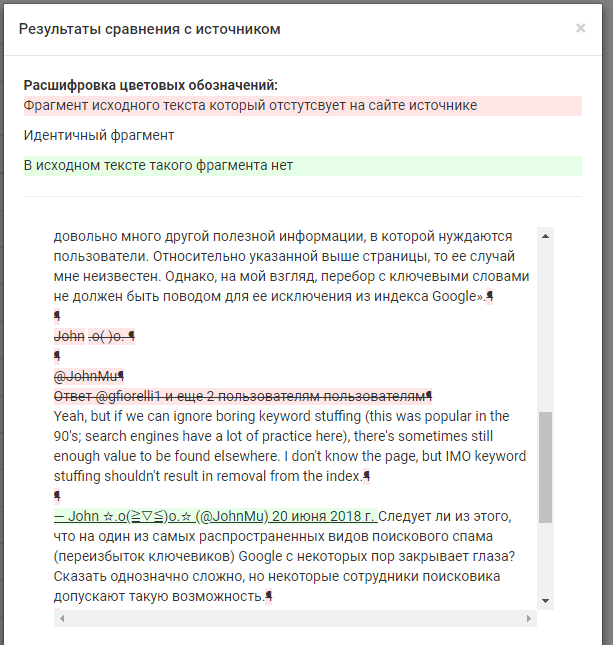 Результаты анализа по фразам
Результаты анализа по фразам Результаты проверки сервисом в режиме «Обнаружение рерайтинга»
Результаты проверки сервисом в режиме «Обнаружение рерайтинга» Фрагмент анализа со ссылками
Фрагмент анализа со ссылками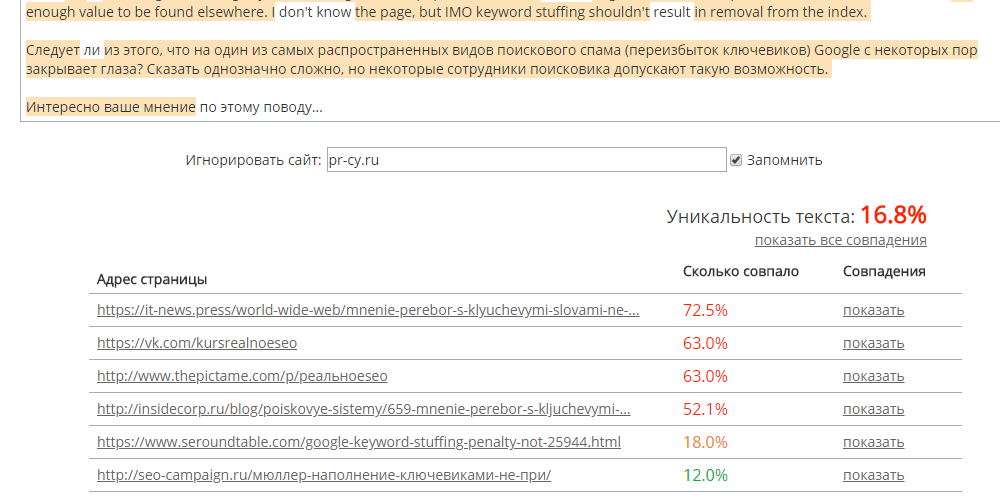 Результаты поиска источников
Результаты поиска источников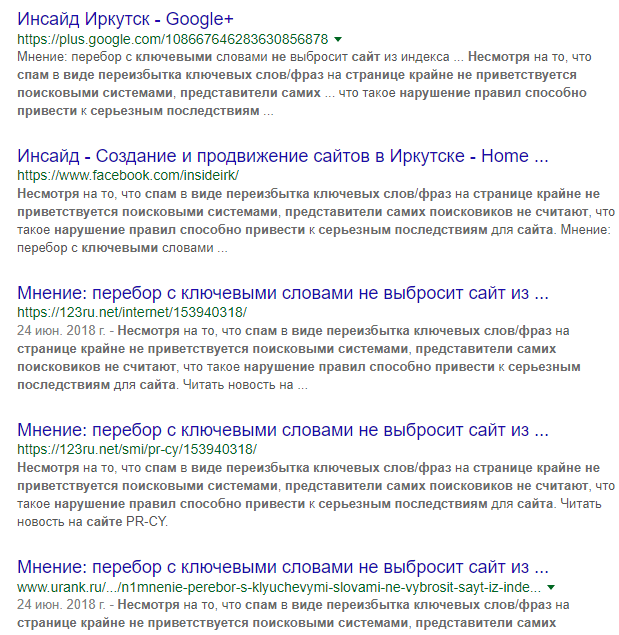 Результаты поиска цитаты из других источников в Google
Результаты поиска цитаты из других источников в Google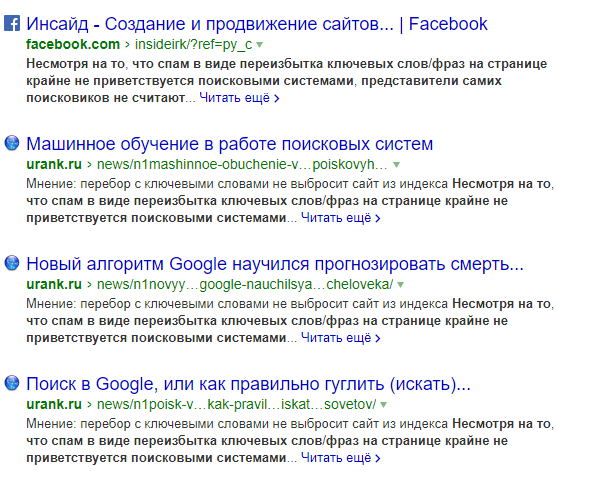 Результаты поиска цитаты из других источников в Яндекс
Результаты поиска цитаты из других источников в Яндекс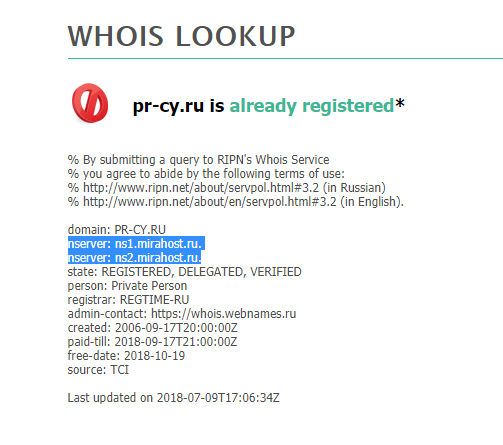 Информация о сайте PR-CY
Информация о сайте PR-CY