Спроси PR-CY — рубрика, где вы можете задавать приглашенном экспертам вопросы по SEO, маркетингу, контенту и другим смежным областям. Неделю мы собираем вопросы, а все ответы публикуем в отдельном посте.
Экспертом 18 выпуска выступил
Николай Коровушкин
Руководитель отдела веб-аналитики Roistat с более чем семилетним опытом работы в аналитике маркетинга и продаж.
За самый интересный вопрос подарок от Roistat, о нем в конце.
Пользователь AlexPsp спрашивает:
«Какой нужен бюджет на одно рекламное объявление (креатив), чтобы понять, эффективна реклама или нет?»
Бюджет кампании зависит от состава рекламных объявлений, ниши, конкуренции, охвата.
Очень часто мы делаем выводы исходя из бюджета, а не фактических данных. Важно анализировать полученные данные, которые собрались по ключевому запросу/объявлению. Поэтому рекомендую опираться на 100 визитов по объявлению (при средней конверсии сайта 2%. Если конверсия ниже, то и визитов нужно больше). Подробнее эту тему рассматривают наши веб-аналитики с клиентами Roistat во время обучения.
Пользователь zerozen спрашивает:
«Может ли сайт пробиться к получению трафика из ПС без SEO? Почему поисковики устроены так, что необходимы SEO-специалисты?»
Seo-специалисты, как правило, знают основные стандарты алгоритмов основных поисковиков. Под эти стандарты и нужно привести сайт, чтобы поисковик видел и считывал информацию с сайта. Поисковик является связующим звеном между сайтом и пользователем и поэтому ему необходимо сделать так, чтобы пользователь находил именно то, что искал. А как это сделать и по каким стандартам работает поисковик, хорошо знают люди, которые с этим сталкиваются ежедневно.
Анна Буданова спрашивает:
«Николай, добрый день! Сейчас веду маркетинг и продвижение производителя электронных компонентов. По причине безопасности и внутренним правилам мы не можем сделать сайт на русском. Но компания хочет, что ее продукцию находили в русскоязычном интернете.
Я сейчас организовала Яндекс.Дзен канал, у нас есть переходы с поисковика Яндекс. Я хочу подключить еще один канал коммуникации с заказчиками — Телеграм или ВК. ЦА- инженеры, возраст от 30 и выше. Хочу узнать ваше мнение, какой канал оптимален для распространения информации для заказчиков при условии, что сайта на русском нет и тема техническая. Рынок B2B. Спасибо».
Для такой ЦА подходит также Facebook и Google. Если есть запрет на русскоязычный сайт, то может стоит вести блог в Instagram/Facebook и там организовать каталог продукции.
Пользователь lewstav1 спрашивает:
«Добрый день! У нас сервис по управлению несколькими профилями в социальных сетях и порядка 50 регистраций в день. Подскажите, как можно проанализировать входящий трафик, чтоб увеличить переход в оплату?»
Вариантов несколько. Можно вручную сводить источники переходов и факты оплат, чтобы больше выделять именно на эти источники, либо настроить сквозную аналитику. Для этого потребуется больше ресурсов в первое время, но облегчит бизнес в дальнейшем.
Maksym Myroshnyk спрашивает:
«Какое УТП может быть у стандартного СТО для иномарок? Бесплатная диагностика уже никого не впечатляет».
Рекомендуется придумать свою фишку, ради которой клиенты будут к вам возвращаться не из-за качества основной услуги (сейчас качество на рынке везде плюс-минус одинаковое при здоровой конкуренции), а из-за вашей фишки. Кто-то делает упор на фирменные обеды/ зону отдыха/ отсутствие агрессивных продаж/ и многое другое. Тут вы должны быть не серой массой, а найти свою фишку, которая вам самим будет нравиться.
Elena_Zhmurina спрашивает:
«Как понять, какие KPI выбрать для контекстной рекламы, как прогнозировать результаты?»
KPI самый корректный ROMI и ROI. Если реклама окупается с первой покупки, это замечательно. Часто бывает, что клиент окупается только после второй и третьей покупки (зависит от бизнеса), тогда следует упор делать на CPO (стоимость продажи). Как опережающий показатель можно использовать CPL (стоимость лида/заявки).
«Как считается нормальным работать с новым клиентом: делать период теста рекламы, где он дает на нее бюджет, но не платит за работу? Или нормально сразу просить деньги за работу, даже если клиенту покажется, что заявки с рекламы стоят дорого? Или клиент платит за работу только в случае успешной настройки?»
У каждой стороны свои интересы. Если у вас есть договор на оказание услуг, то можно работать и по эффективности рекламы.
Пользователь mixas спрашивает:
«Как узнать бюджет конкурентов?»
Сделать конкурентный анализ. Для этого есть платные программы. Также можно заказать аудит у сторонней компании, которые уже пользуются этими программами.
Подарок за самый интересный вопрос
От сервиса Roistat 10000 рублей на счет в личный кабинет и купон на удвоение рекламного бюджета в MyTarget для новых клиентов получает AlexPsp. Поздравляем! Ждите письмо на почте 🙂
Мнение редакции PR-CY может не совпадать с мнением приглашенного эксперта
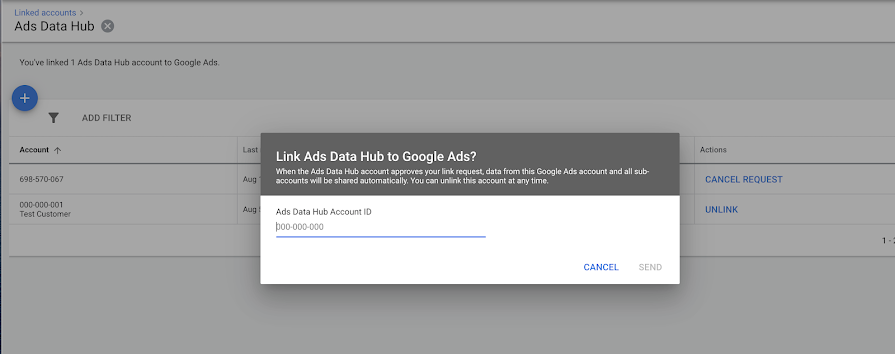
Мы уже писали в октябре об обновленном дизайне Редактора отчетов и новых функциях для настройки рекламных кампаний. Теперь же в Google Ads добавилась интеграция с сервисом Ads Data Hub.
Ads Data Hub — это облачный сервис Google, используемый для анализа данных. С его помощью вы можете получать данные из различных платформ Google (Менеджер Кампаний, Дисплей и Видео 360, Data Studio, Google Таблицы и многих других) и визуализировать их с помощью интерактивных панелей мониторинга и отчетов. А при новой интеграции с Google Ads вы сможете отследить соотношение показов ваших объявлений к уже существующим и новым клиентам.
Чтобы связать аккаунты между собой и подключить Ads Data Hub к своей CRM, вы можете обратиться к справке Google. Для подключения функции необходим доступ с правами администратора к аккаунту Google Ads..
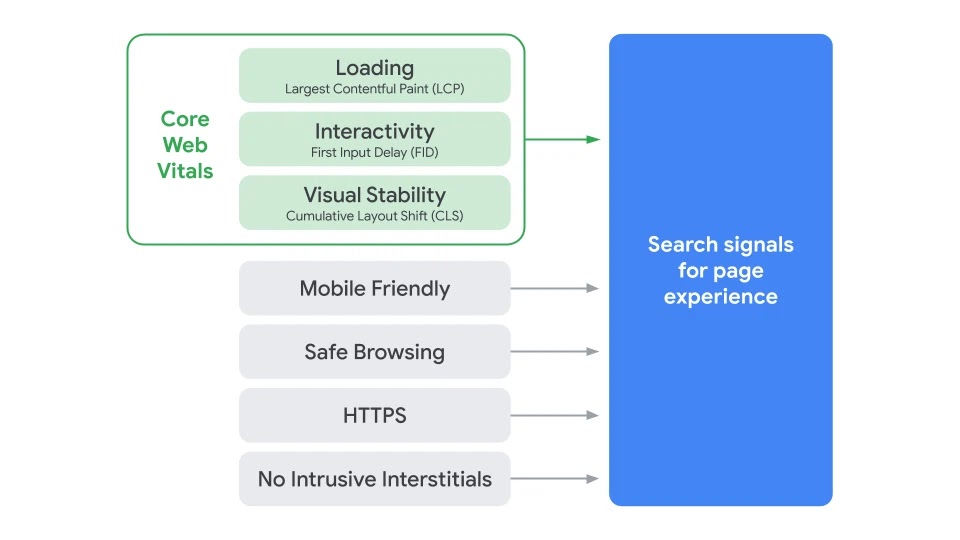
Мы уже публиковали большой материал о новых факторах ранжирования Google в прошлом месяце. И для одного из них — Page Experience — Google наконец назвал дату выхода. Новый сигнал будет выпущен в мае 2021.
Page Experience объединяет метрики Core Web Vitals с собственными сигналами ранжирования Google. Это сделано для удобства анализа страницы. По данным Google, число пользователей, использующих Lighthouse и Page Speed Insights, выросло на 70% за последние несколько месяцев, и многие из них анализируют именно Core Web Vitals.
Плюсом ко всему поисковик тестирует визуальный индикатор качества страниц, который будет выделять хорошие для восприятия страницы в результатах поиска. Если тест окажется успешным, то это нововведение выпустят вместе с Page Experience в мае 2021.
Для того, чтобы подготовиться к новым сигналам и улучшить качество страницы, разработчики рекомендуют использовать отчет Search Console в Core Web Vitals для подробной статистики и выявления проблем. А инструменты Lighthouse и Page Speed Insights помогут в их устранении.
Также с мая несколько изменится политика отображения контента для мобильных устройств: Google будет отдавать предпочтение качеству страницы, вне зависимости от использования AMP в них. Но несмотря на то, что AMP перестает быть фактором в ранжировании мобильных страниц, Google признает его эффективность для качества и удобства для пользователей, и также рекомендует ознакомиться с обновленным руководством для него.
Дзен полагает, что подборка из нескольких товаров в одном видео помогает охватить большую аудиторию и, как следствие, получить лучшие конверсии. Плюсом, помимо обзора нескольких товаров, можно рассказывать об одном и приводить в качестве примера другие модели. Это также положительно влияет на конверсии.
Разработчики рекомендуют вставлять виджет примерно через 40 секунд после начала видео, чтобы зритель успел вникнуть в суть. Очень важно также, что зритель был в курсе того, что на виджет необходимо нажать для перехода — об этом следует сказать в видео или указать в субтитрах.
Главное требование Яндекса к блогерам состоит в том, чтобы товар полностью соответствовал тому, о котором рассказывается. Остальные требования представлены в Справке.
Маркет платит блогерам за клики на номера телефонов, переходы в интернет-магазины и оформленные заказы. В статистике вы можете просмотреть общий доход.
Это 19 выпуск рубрики Спроси PR-CY, где наши читатели могут задать вопросы экспертам по SEO, маркетингу, рекламе и контенту. В каждом выпуске эксперт новый, в этом на ваши вопросы ответит
Александр Алаев aka Алаич
Известен как автор блога Алаича и Телеграм-канала @alaevseo. Занимается созданием и продвижением сайтов более 15 лет, руководит веб-студией «АлаичЪ и Ко». Создал программы FastTrust и ComparseR и сервис CheckTrust.ru
Пишите любое количество вопросов по SEO в комментарии к этому посту. Мы будем собирать ваши вопросы до конца недели и потом передадим их Александру в работу. Пост с ответами выложим на следующей неделе.
Подарки за вопросы 😉
Авторам самых интересных вопросов подарим промокоды:
бесплатный месяц тарифа Профи в сервисе Анализ сайта от PR-CY;
бесплатный месяц тарифа Вебмастер в сервисе CheckTrust.ru от эксперта.
Ждем ваши вопросы в комментариях!
Спроси PR-CY#18: ответы эксперта прошлого выпуска — руководителя отдела веб-аналитики Roistat Николая Коровушкина
Теперь для Google особенно важна экспертность и достоверность контента. В этом материале рассмотрим, что внедрить на сайте, чтобы Google понял, что материал написан специалистами по теме.
В статье:
Почему теперь важно следить за экспертностью
С помощью каких сигналов Google распознает авторов
Как Google измеряет уровень экспертности
Как продемонстрировать поисковику авторитет автора
Почему вдруг стало важно, кто автор контента
В 2020 году Google больше внимания уделяет качеству страницы. Среди прочих он использует параметры E-A-T — экспертность, авторитетность и достоверность.
Все сайты проходят оценку по E-A-T, но к сайтам, связанным со здоровьем, финансами и благополучием, более высокие требования. Такие сайты составляют категорию YMYL — Your Money or Your Life. Туда можно отнести порталы о воспитании детей, советы по оформлению ипотеки, вкладам и инвестициям, ремонту техники, подбору витаминов и другие темы, требующие специальных компетенций. Это могут быть интернет-магазины, инфосайты, блоги и даже форумы.
Подробно мы разбирали тему в статье «Главное о факторах E-A-T Google и три чек-листа для разных YMYL-сайтов»
На E-A-T работают качественные входящие ссылки, документы о соответствии требованиям, достижения, награды и доказательства экспертности авторов. В этом материале остановимся на авторах: по каким сигналам Google распознает, кто написал статью, и как повысить авторитет в глазах поисковика.
Как Google распознает авторов контента
Google умеет распознавать, кто автор, и может оценивать его авторитетность. Посмотрим на развитие по истории патентов:
Распознавание по подписи
Еще в 2007 году по патенту «Agent Rank» поисковик мог идентифицировать авторов и экспертов на разных сайтах по их подписям, давать числовую оценку репутации и использовать ее как еще один фактор ранжирования контента.
В июне 2011 года Google начал поддерживать разметку авторства Schema.org, тогда стало нужно размечать контент тегами rel = «author» и rel = «me», связывая каждый фрагмент содержания с профилем автора на сайте.
Распознавание по речи
Google может идентифицировать говорящего с помощью распознавания речи, информация об этом есть в патенте «Speaker Identification», который он получил в 2020 году. Так что поисковику под силу анализировать видео и подкасты.
Распознавание на основе стиля письма
Также в 2020 году в марте поисковик подал заявку на патент «Generating Author Vectors», по которому он может идентифицировать авторов только на основе их стиля письма, даже если их имена не упоминаются на странице. Это возможно благодаря системе нейронной сети, обученной на наборе слов.
Получается, если Google активно использует этот патент в алгоритмах поиска, то для SEO это имеет много интересных последствий:
Google может раскрыть обман, если веб-мастер укажет имя экспертного автора к статье, которую тот не писал.
Google на основе авторского стиля сможет определить автора материала, если тот не указан.
Google может проанализировать качество и стиль письма конкретных экспертов, чтобы определить, как должен выглядеть другой экспертный контент по этой теме.
У нас нет доказательств, что Google делает так на практике. Но в любом случае недостаточно просто написать, что ваш контент проверили эксперты. Сложно обмануть поисковик и сделать вид, что у сайта хорошие E-A-T, если качество не соответствует ожидаемому уровню знаний.
Как Google измеряет уровень экспертности
У показателя E-A-T нет счетчика, так что веб-мастер не может узнать, на сколько баллов асессоры Google оценили экспертность сайта. Но есть ли порог, который сайт должен перейти, чтобы считаться достаточно экспертной площадкой по теме?
Патент Website Representation Vectors сообщает, что Google может классифицировать сайты по уровням знаний:
эксперт;
ученик;
непрофессионал.
А также ранжировать страницы на основе авторитетности.
Классифицировать контент по этим уровням он может на основе «любого подходящего метода», как написано в патенте. Например, с помощью анализа текста или изображений, просмотра входящих ссылок или и того, и другого.
Это не значит, что категории ученик или непрофессионал хуже эксперта. Google не против того, что называется «повседневной экспертизой» в некоторых видах контента. О методах лечения должен писать врач, основываясь на научных исследованиях, но об опыте жизни с заболеванием можно писать и без образования в медицине.
«Некоторые темы требуют менее формальной экспертизы. Многие люди пишут подробные и полезные обзоры продуктов или ресторанов, делятся советами и опытом на форумах, в блогах. Этих обычных людей можно считать экспертами в тех областях, в которых они опытны.
Если кажется, что у человека, создающего контент, есть такой жизненный опыт, который делает его экспертом в теме, мы будем ценить этот опыт и не накажем автора, страницу или сайт за то, что он не имеет формального образования или профессиональной подготовки».
В патенте 2017 года под названием «Obtaining Authoritative Search Results» есть информация, что Google может распознавать сайты низкого качества по обилию рекламы и поверхностному по содержанию контенту.
Как продемонстрировать поисковику экспертность автора
Рассмотрим, как работать с контентом, чтобы Google понял, что тексты на сайте написаны экспертами в теме и достойны доверия.
Содержание материала
Что делать с контентом на сайте:
1. Заказывайте оригинальные тексты.
Не копируйте материалы с других сайтов. Google это легко вычислит, да и настоящий автор может заметить и заявить об этом, что повредит вашей репутации. Аудитория потеряет доверие.
2. Назначайте контенту экспертов
Обычно в зависимости от сложности темы используют одну из таких схем:
эксперт сам пишет материал на сайт;
копирайтер пишет текст, а эксперт его проверяет и ищет ошибки, эксперта указывают как рецензента;
копирайтер опрашивает эксперта и на основе ответов собирает статью или интервью, которую согласовывают перед публикацией. Эксперта также указывают как рецензента.
В любом случае материал проходит через профессионала, который разбирается в теме. Создавать материалы по такой схеме дольше, чем просто заказывать статьи у копирайтеров, но пусть лучше на сайте будет меньше текстов, зато они будут качественными и экспертными.
3. Следите за глубиной содержания
Не пытайтесь сделать из сайта Википедию, поверхностные тексты обо всем сразу не нравятся Google. Пусть лучше ваш сайт будет узкопрофильным, зато в полной мере отвечающим на запросы по теме.
4. Выбирайте слова
Исходя из классификации «эксперт, ученик, непрофессионал» подозреваем, что Google может обращать внимание на наличие профессиональных терминов в тексте для определения уровня.
5. Следите за актуальностью
Удаляйте или обновляйте устаревший контент, указывайте дату обновления.
Проверяйте, насколько факты соответствуют действительности и современной научной точке зрения.
Добавляйте цитаты экспертов по вашей теме со ссылками на них.
Ставьте ссылки на доказательства — исследования, статистику, эксперименты и другие публикации с авторитетных площадок.
Добавьте визуальные элементы по теме — диаграммы, скриншоты, видео, иллюстрации.
Другое по теме: Продвижение новостных сайтов
Микоразметка Schema.org
Используйте микроразметку, чтобы упростить ботам понимание контента.
Страница автора
Информацию об эксперте можно передать с помощью разметки Person, там есть множество свойств для данных о работе, образовании, контактов и прочего.
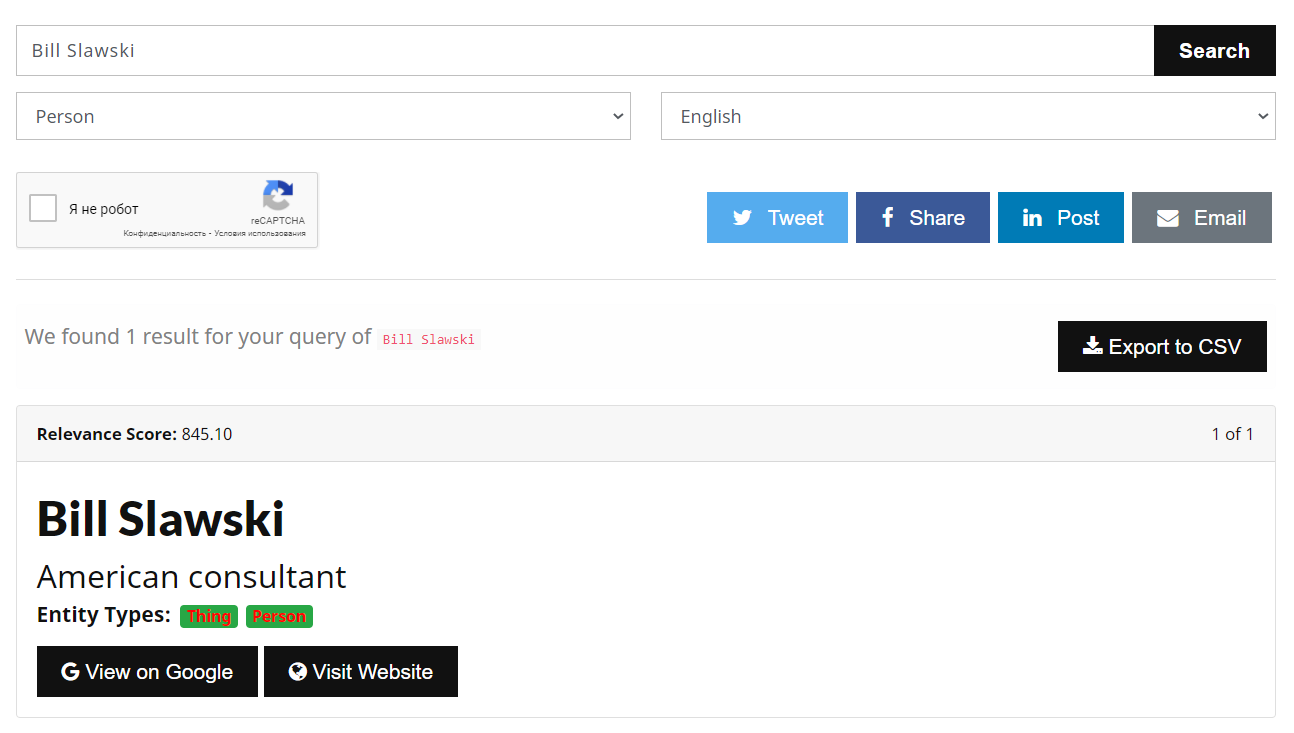
Некоторые известные эксперты, редакторы, организации или места есть в базе Google «Сеть знаний», проверить наличие в базе можно через инструмент. Мы нашли там американского SEO-консультанта Билла Славски, который занимается изучением патентов Google и ведет блог «SEO by the Sea».
Билл Славски в Базе знаний Google
Если вы нашли в базе своего эксперта, организацию или другой термин, для дополнительного сигнала Google можете указать ссылку на страницу в Базе знаний в разметке SameAs.
Это полезно, если у бота могут быть сомнения о релевантности. Например, в случае с двумя Майклами Джексонами: певцом и военачальником.
Если страницы в Базе знаний нет, но есть в Википедии или на других авторитетных источниках, в SameAs можете указать этот адрес.
Подпись автора
Для подписи автора используют свойство author, он. Если их несколько, укажите каждого в отдельном теге.
Типы для свойства Author — Person или Organization, если вы публикуете контент от имени компании, указывайте в качестве автора компанию — Organization.
Если ваш материал проверили специалисты по теме, экспертные критики, укажите их в reviewedBy — там можно указать человека или организацию. Особенно важно это для медицинских, юридических и других сайтов из YMYL.
Это хороший способ добавить экспертности материалу, если автор неизвестный, но эксперт имеет репутацию в интернете.
Цитаты и ссылки
Для цитат со ссылками на авторитетные источники есть свойство citation. Там можно указать исследования, обзоры, статистику — все публикации на авторитетных источниках, на которые вы ссылаетесь в тексте.
Так вы покажете Google, что контент основан на правдивых, заслуживающих доверия данных.
Подпись с автором и страница с информацией
Добавьте подпись автора ко всем статьям, которые он написал на вашем сайте. Обычно это имя с кликабельной ссылкой, как, например, на lifehacker.ru:
Подпись автора
Ссылка ведет на список всех статей автора:
Список всех статей одного автора в блоге
На некоторых площадках авторы оформлены еще подробнее — у каждого есть страница с именем, фотографией, описанием с перечислением опыта и профессиональных интересов. Тогда на подписи к статьям стоит ссылка на такую страницу об авторе.
На страницу об авторе можно добавить ссылки на сайт автора и социальные сети, чтобы было понятно, что профиль автора на сайте и профиль в соцсетях принадлежат одному человеку и связаны по теме. Идеально, если он ведет блог на смежную тему в этих соцсетях или просто публикует тематические посты и размещает ссылки на свои публикации.
Как пример, у всех статей в блоге searchenginejournal.com в начале текста есть кликабельная плашка с фотографией и именем автора:
Указание автора статьи
Ссылка с имени ведет на страницу автора на сайте, где указан личный сайт автора, ссылки на социальные сети, почта, описание опыта и рекомендации:
Страница с информацией об авторе
Это служит подтверждением экспертности для поисковика и полезно для читателя: он может больше узнать об авторе и проникнуться доверием к его опыту.
Такое оформление используют не только в контентных проектах. Рассмотрим, как выглядит информация о врачах на сайте personaclinic.ru. На странице со статьей по стоматологии стоит подпись автора — врача, и стоит ссылка на его страницу.
Подпись врача в блоге
Было бы еще нагляднее оформить подпись автора в заметную плашку со ссылкой и миниатюрой фотографии.
Ссылка ведет на отдельную страницу с полным именем, фотографией, информацией об образовании и опыте работы. Пациент может удостовериться в том, что его будет лечить квалифицированный специалист:
Основная информация
На этой же странице видео с ним, дипломы и отзывы клиентов, это подкрепляет доверие:
Дипломы и отзывы
Запросите у авторов информацию, подтверждающую их компетенции:
образование и дополнительное обучение;
публикации на других авторитетных площадках;
награды, дипломы;
выступления на конференциях и вебинарах;
перечень профессиональных интересов.
Соберите только то, что относится к теме вашей площадки или косвенно с ней связано. Если ваше издание посвящено автомобилям, вряд ли читателям будет интересен опыт автора в организации собачьих выставок и обучение в аграрном техникуме.
Но если вы работаете с разными заказчиками — к примеру, вы контентное бюро, тогда стоит перечислить темы, в которых автор лучше разбирается. Порталу об антропологии может быть легче работать с автором, имеющим образование биолога или историка, чем с маркетологом.
Работой с авторами дело не ограничится. E-A-T подразумевают экспертность, авторитет и достоверность, все способы продемонстрировать это Google собраны в наших чек-листах по E-A-T для медицинских сайтов, e-commerce и инфопроектов.
Стратегия SEO, ориентированная на E-A-T, имеет долгосрочный характер. Не получится исправить что-то на сайте и сразу увидеть результаты, сложность состоит и в том, что соответствие параметрам E-A-T нельзя измерить. Но работа над повышением авторитетности и экспертности сработает только в плюс — как для работы в Google, так и для продвижения в Яндексе, и для повышения доверия у пользователей.


 Билл Славски в Базе знаний Google
Билл Славски в Базе знаний Google Подпись автора
Подпись автора Список всех статей одного автора в блоге
Список всех статей одного автора в блоге Указание автора статьи
Указание автора статьи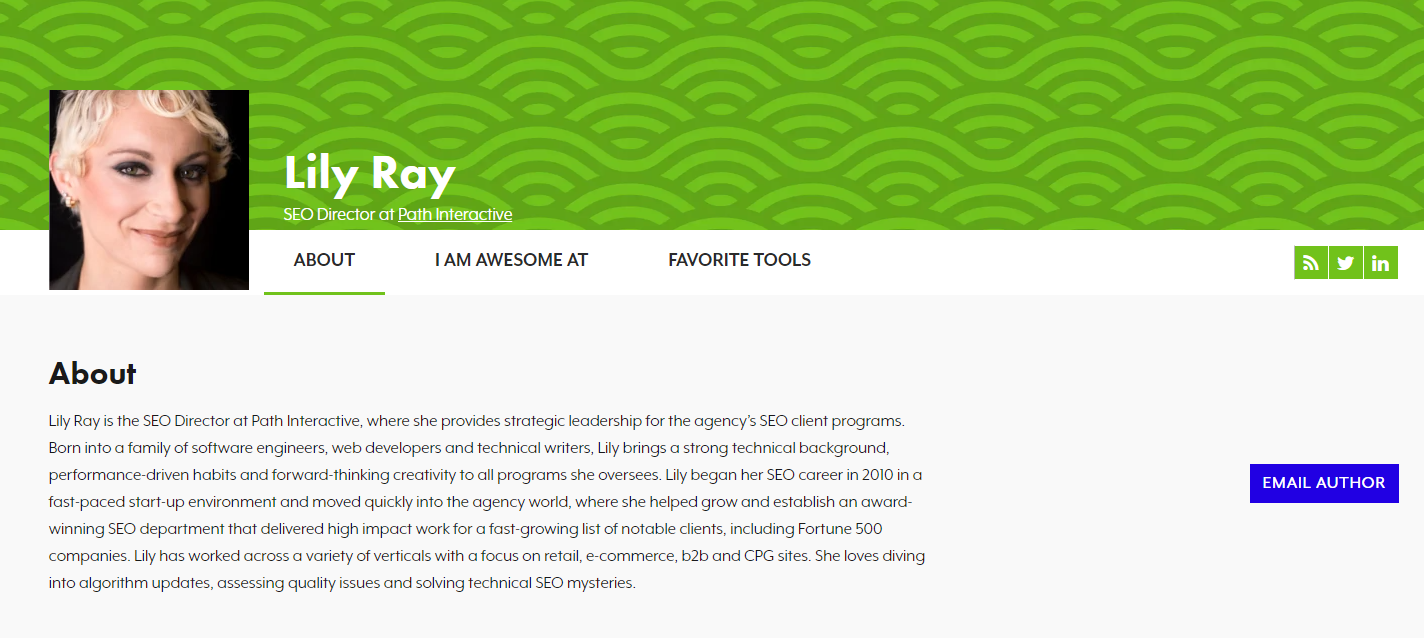 Страница с информацией об авторе
Страница с информацией об авторе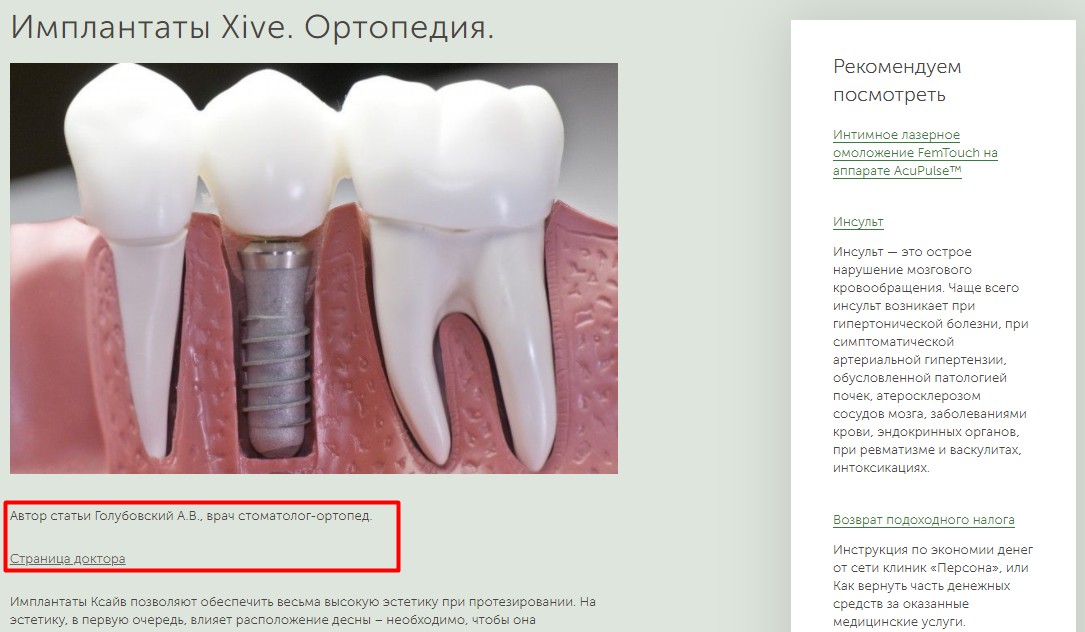 Подпись врача в блоге
Подпись врача в блоге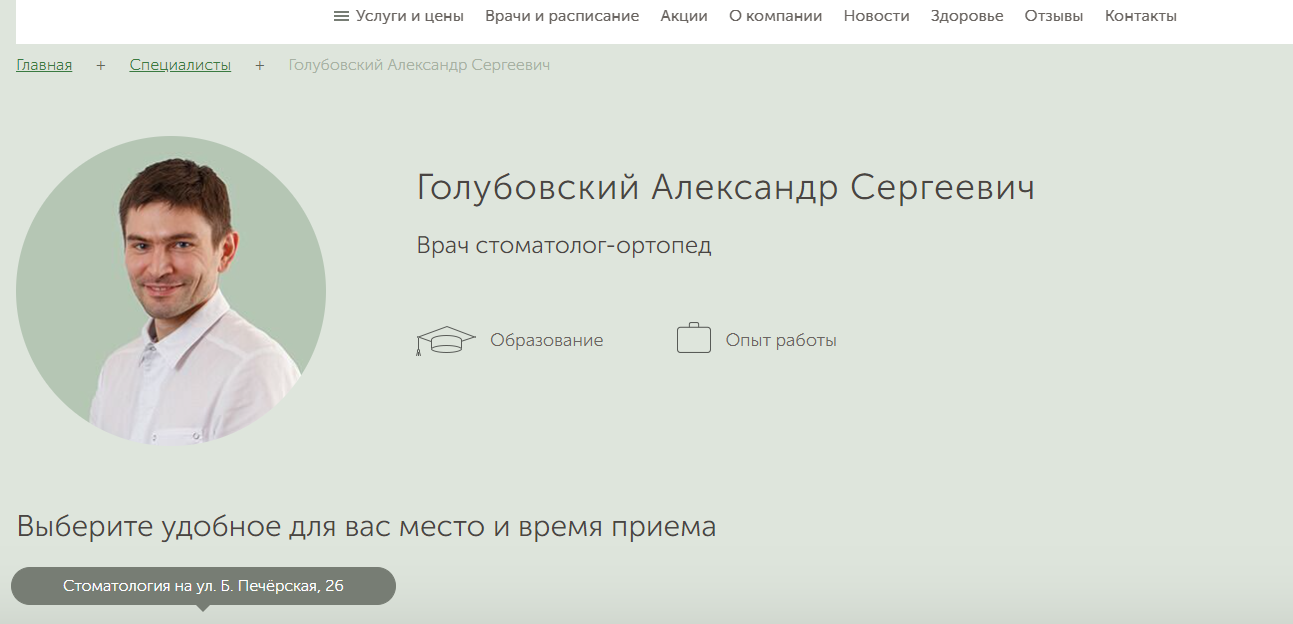 Основная информация
Основная информация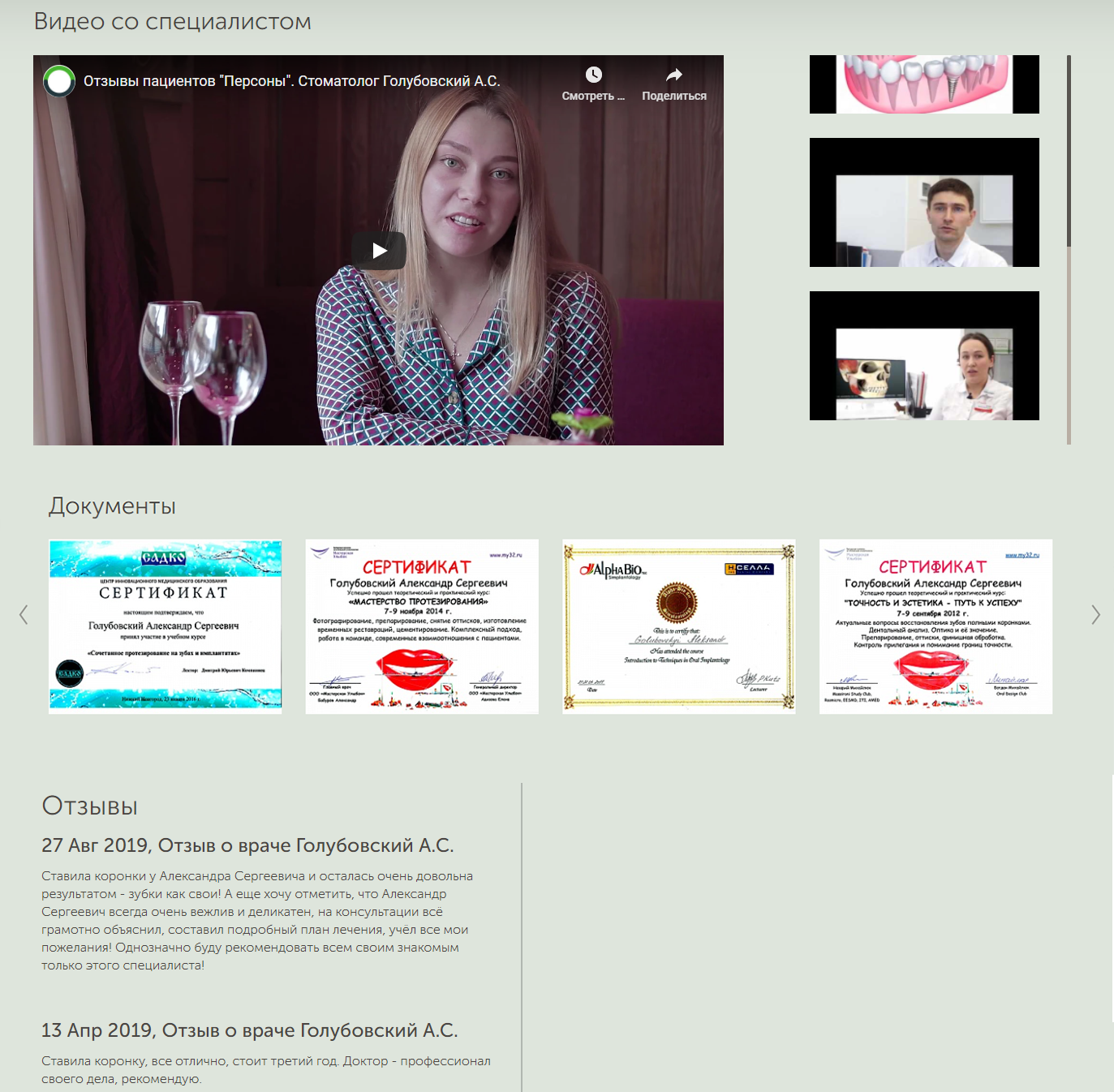 Дипломы и отзывы
Дипломы и отзывы